0. PGL图学习之图神经网络GraphSAGE、GIN图采样算法[系列七]
本我的项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5061984?contributionType=1
相干我的项目参考:更多材料见主页
对于图计算&图学习的基础知识概览:前置知识点学习(PGL)[系列一] https://aistudio.baidu.com/ai…
图机器学习(GML)&图神经网络(GNN)原理和代码实现(前置学习系列二):https://aistudio.baidu.com/ai…
在图神经网络中,应用的数据集可能是亿量级的数据,而因为GPU/CPU资源无限无奈一次性全图送入计算资源,须要借鉴深度学习中的mini-batch思维。
传统的深度学习mini-batch训练每个batch的样本之间无依赖,多层样本计算量固定;而在图神经网络中,每个batch中的节点之间相互依赖,在计算多层时会导致计算量爆炸,因而引入了图采样的概念。
GraphSAGE也是图嵌入算法中的一种。在论文Inductive Representation Learning on Large Graphs 在大图上的演绎示意学习中提出。github链接和官网介绍链接。
与node2vec相比较而言,node2vec是在图的节点级别上进行嵌入,GraphSAGE则是在整个图的级别上进行嵌入。之前的网络示意学习的transductive,难以从而提出了一个inductive的GraphSAGE算法。GraphSAGE同时利用节点特色信息和构造信息失去Graph Embedding的映射,相比之前的办法,之前都是保留了映射后的后果,而GraphSAGE保留了生成embedding的映射,可扩展性更强,对于节点分类和链接预测问题的体现也比较突出。
0.1提出背景
现存的办法须要图中所有的顶点在训练embedding的时候都呈现;这些前人的办法实质上是transductive,不能天然地泛化到未见过的顶点。文中提出了GraphSAGE,是一个inductive的框架,能够利用顶点特色信息(比方文本属性)来高效地为没有见过的顶点生成embedding。GraphSAGE是为了学习一种节点示意办法,即如何通过从一个顶点的部分街坊采样并聚合顶点特色,而不是为每个顶点训练独自的embedding。
这个算法在三个inductive顶点分类benchmark上超过了那些很强的baseline。文中基于citation和Reddit帖子数据的信息图中对未见过的顶点分类,试验表明应用一个PPI(protein-protein interactions)多图数据集,算法能够泛化到齐全未见过的图上。
0.2 回顾GCN及其问题
在大型图中,节点的低维向量embedding被证实了作为各种各样的预测和图剖析工作的特色输出是十分有用的。顶点embedding最根本的根本思维是应用降维技术从高维信息中提炼一个顶点的街坊信息,存到低维向量中。这些顶点嵌入之后会作为后续的机器学习零碎的输出,解决像顶点分类、聚类、链接预测这样的问题。
- GCN尽管能提取图中顶点的embedding,然而存在一些问题:
- GCN的根本思维: 把一个节点在图中的高纬度邻接信息降维到一个低维的向量示意。
- GCN的长处: 能够捕获graph的全局信息,从而很好地示意node的特色。
-
GCN的毛病: Transductive learning的形式,须要把所有节点都参加训练能力失去node embedding,无奈疾速失去新node的embedding。
1.图采样算法
1.1 GraphSage: Representation Learning on Large Graphs
图采样算法:顾名思义,图采样算法就是在一张图中进行采样失去一个子图,这里的采样并不是随机采样,而是采取一些策略。典型的图采样算法包含GraphSAGE、PinSAGE等。
文章码源链接:
https://cs.stanford.edu/peopl…
https://github.com/williamlei…
后面 GCN 解说的文章中,我应用的图节点个数非常少,然而在理论问题中,一张图可能节点十分多,因而就没有方法一次性把整张图送入计算资源,所以咱们应该应用一种无效的采样算法,从全图中采样出一个子图 ,这样就能够进行训练了。
GraphSAGE与GCN比照:
既然新增的节点,肯定会扭转原有节点的示意,那么为什么肯定要失去每个节点的一个固定的示意呢?何不间接学习一种节点的示意办法。去学习一个节点的信息是怎么通过其街坊节点的特色聚合而来的。 学习到了这样的“聚合函数”,而咱们自身就已知各个节点的特色和街坊关系,咱们就能够很不便地失去一个新节点的示意了。
GCN等transductive的办法,学到的是每个节点的一个惟一确定的embedding; 而GraphSAGE办法学到的node embedding,是依据node的街坊关系的变动而变动的,也就是说,即便是旧的node,如果建设了一些新的link,那么其对应的embedding也会变动,而且也很不便地学到。
在理解图采样算法前,咱们至多应该保障采样后的子图是连通的。例如上图图中,右边采样的子图就是连通的,左边的子图不是连通的。
GraphSAGE的外围:GraphSAGE不是试图学习一个图上所有node的embedding,而是学习一个为每个node产生embedding的映射。 GraphSage框架中蕴含两个很重要的操作:Sample采样和Aggregate聚合。这也是其名字GraphSage(Graph SAmple and aggreGatE)的由来。GraphSAGE 次要分两步:采样、聚合。GraphSAGE的采样形式是街坊采样,街坊采样的意思是在某个节点的街坊节点中抉择几个节点作为原节点的一阶街坊,之后对在新采样的节点的街坊中持续抉择节点作为原节点的二阶节点,以此类推。
文中不是对每个顶点都训练一个独自的embeddding向量,而是训练了一组aggregator functions,这些函数学习如何从一个顶点的部分街坊聚合特色信息(见图1)。每个聚合函数从一个顶点的不同的hops或者说不同的搜寻深度聚合信息。测试或是推断的时候,应用训练好的零碎,通过学习到的聚合函数来对齐全未见过的顶点生成embedding。
GraphSAGE 是Graph SAmple and aggreGatE的缩写,其运行流程如上图所示,能够分为三个步骤:
- 对图中每个顶点街坊顶点进行采样,因为每个节点的度是不统一的,为了计算高效, 为每个节点采样固定数量的街坊
- 依据聚合函数聚合街坊顶点蕴含的信息
- 失去图中各顶点的向量示意供上游工作应用
街坊采样的长处:
- 极大缩小计算量
- 容许泛化到新连贯关系,集体了解相似dropout的思维,能加强模型的泛化能力
采样的阶段首先选取一个点,而后随机选取这个点的一阶街坊,再以这些街坊为终点随机抉择它们的一阶街坊。例如下图中,咱们要预测 0 号节点,因而首先随机抉择 0 号节点的一阶街坊 2、4、5,而后随机抉择 2 号节点的一阶街坊 8、9;4 号节点的一阶街坊 11、12;5 号节点的一阶街坊 13、15
聚合具体来说就是间接将子图从全图中抽离进去,从最边缘的节点开始,一层一层向里更新节点
上图展现了街坊采样的长处,极大缩小训练计算量这个是毋庸置疑的,泛化能力加强这个可能不太好了解,因为本来要更新一个节点须要它四周的所有街坊,而通过街坊采样之后,每个节点就不是由所有的街坊来更新它,而是局部街坊节点,所以具备比拟强的泛化能力。
1.1.1 论文角度看GraphSage
聚合函数的选取
在图中顶点的街坊是无序的,所以心愿结构出的聚合函数是对称的(即也就是对它输出的各种排列,函数的输入后果不变),同时具备较高的表达能力。 聚合函数的对称性(symmetry property)确保了神经网络模型能够被训练且能够利用于任意程序的顶点街坊特色汇合上。
a. Mean aggregator :
mean aggregator将指标顶点和街坊顶点的第$k−1$层向量拼接起来,而后对向量的每个维度进行求均值的操作,将失去的后果做一次非线性变换产生指标顶点的第$k$层示意向量。
卷积聚合器Convolutional aggregator:
文中用上面的式子替换算法1中的4行和5行失去GCN的inductive变形:
$$
\mathbf{h}_{v}^{k} \leftarrow \sigma\left(\mathbf{W} \cdot \operatorname{MEAN}\left(\left\{\mathbf{h}_{v}^{k-1}\right\} \cup\left\{\mathbf{h}_{u}^{k-1}, \forall u \in \mathcal{N}(v)\right\}\right)\right) $$
原始算法1中的第4,5行是
$$\begin{array}{l}
\mathbf{h}_{\mathcal{N}(v)}^{k} \leftarrow \operatorname{AGGREGATE}_{k}\left(\left\{\mathbf{h}_{u}^{k-1}, \forall u \in \mathcal{N}(v)\right\}\right) \\
\mathbf{h}_{v}^{k} \leftarrow \sigma\left(\mathbf{W}^{k} \cdot \operatorname{CONCAT}\left(\mathbf{h}_{v}^{k-1}, \mathbf{h}_{\mathcal{N}(v)}^{k}\right)\right)
\end{array}$$
**论文提出的均值聚合器Mean aggregator:**
$$\begin{array}{l}
\mathbf{h}_{v}^{k} \leftarrow \sigma\left(\mathbf{W} \cdot \operatorname{MEAN}\left(\left\{\mathbf{h}_{v}^{k-1}\right\} \cup\left\{\mathbf{h}_{u}^{k-1}, \forall u \in \mathcal{N}(v)\right\}\right)\right) \\
\mathbf{h}_{v}^{k} \leftarrow \sigma\left(\mathbf{W}^{k} \cdot \operatorname{CONCAT}\left(\mathbf{h}_{v}^{k-1}, \mathbf{h}_{\mathcal{N}(v)}^{k}\right)\right)
\end{array}$$
* 均值聚合近似等价在transducttive GCN框架中的卷积流传规定
* 这个批改后的基于均值的聚合器是convolutional的。然而这个卷积聚合器和文中的其余聚合器的重要不同在于它没有算法1中第5行的CONCAT操作——卷积聚合器没有将顶点前一层的示意$\mathbf{h}^{k-1}_{v}$聚合的街坊向量$\mathbf{h}^k_{\mathcal{N}(v)}$拼接起来
* 拼接操作能够看作一个是GraphSAGE算法在不同的搜寻深度或层之间的简略的**skip connection**[Identity mappings in deep residual networks]的模式,它使得模型的表征性能取得了微小的晋升
* 举个简略例子,比方一个节点的3个街坊的embedding别离为[1,2,3,4],[2,3,4,5],[3,4,5,6]依照每一维别离求均值就失去了聚合后的街坊embedding为[2,3,4,5]
**b. LSTM aggregator**
文中也测试了一个基于LSTM的简单的聚合器[Long short-term memory]。和均值聚合器相比,LSTMs有更强的表达能力。然而,LSTMs不是对称的(symmetric),也就是说不具备排列不变性(permutation invariant),因为它们以一个序列的形式解决输出。因而,须要先对街坊节点**随机程序**,而后将街坊序列的embedding作为LSTM的输出。
* 排列不变性(permutation invariance):指输出的程序扭转不会影响输入的值。
**c. Pooling aggregator**
pooling聚合器,它既是对称的,又是可训练的。Pooling aggregator 先对指标顶点的街坊顶点的embedding向量进行一次非线性变换,之后进行一次pooling操作(max pooling or mean pooling),将失去后果与指标顶点的示意向量拼接,最初再通过一次非线性变换失去指标顶点的第k层示意向量。
一个element-wise max pooling操作利用在街坊汇合上来聚合信息:
$$\begin{aligned}
\mathbf{h}_{\mathcal{N}(v)}^{k}=& \mathrm{AGGREGATE}_{k}^{\text {pool}}=\max \left(\left\{\sigma\left(\mathbf{W}_{\text {pool}} \mathbf{h}_{u}^{k-1}+\mathbf{b}\right), \forall u \in \mathcal{N}(v)\right\}\right) \\
&\mathbf{h}_{v}^{k} \leftarrow \sigma\left(\mathbf{W}^{k} \cdot \operatorname{CONCAT}\left(\mathbf{h}_{v}^{k-1}, \mathbf{h}_{\mathcal{N}(v)}^{k}\right)\right)
\end{aligned}$$
其中
* $max$示意element-wise最大值操作,取每个特色的最大值
* $\sigma$是非线性激活函数
* 所有相邻节点的向量共享权重,先通过一个非线性全连贯层,而后做max-pooling
* 按维度利用 max/mean pooling,能够捕捉街坊集上在某一个维度的突出的/综合的体现。
#### (有监督和无监督)参数学习
在定义好聚合函数之后,接下来就是对函数中的参数进行学习。文章别离介绍了无监督学习和监督学习两种形式。
**基于图的无监督损失**
基于图的损失函数偏向于使得相邻的顶点有类似的示意,但这会使互相远离的顶点的示意差别变大:
$$J \mathcal{G}\left(\mathbf{z}_{u}\right)=-\log \left(\sigma\left(\mathbf{z}_{u}^{T} \mathbf{z}_{v}\right)\right)-Q \cdot \mathbb{E}_{v_{n} \sim P_{n}(v)} \log \left(\sigma\left(-\mathbf{z}_{u}^{T} \mathbf{z}_{v_{n}}\right)\right)$$
其中
* $\mathbf{z}_{u}$为节点$u$通过GraphSAGE生成的embedding
* 节点$v$是节点$u$随机游走达到的“街坊”
* $\sigma$是sigmoid函数
* $P_{n}$是负采样的概率分布,相似word2vec中的负采样
* $Q$是负样本的数目
* embedding之间类似度通过向量点积计算失去
文中输出到损失函数的示意$\mathbf{z}_u$是从蕴含一个顶点部分街坊的特色生成进去的,而不像之前的那些办法(如DeepWalk),对每个顶点训练一个举世无双的embedding,而后简略进行一个embedding查找操作失去。
**基于图的有监督损失**
无监督损失函数的设定来学习节点embedding 能够供上游多个工作应用。监督学习模式依据工作的不同间接设置指标函数即可,如最罕用的节点分类工作应用穿插熵损失函数。
**参数学习**
通过前向流传失去节点$u$的embedding $z_u$,而后梯度降落(实现应用Adam优化器) 进行反向流传优化参数$\mathbf{W}^{k}$和聚合函数内的参数。
**新节点embedding的生成**
这个$\mathbf{W}^{k}$ 就是所谓的dynamic embedding的外围,因为保留下来了从节点原始的高维特色生成低维embedding的形式。当初,如果想得到一个点的embedding,只须要输出节点的特征向量,通过卷积(利用曾经训练好的 $\mathbf{W}^{k}$ 以及特定聚合函数聚合neighbor的属性信息),就产生了节点的embedding。
**有了GCN为啥还要GraphSAGE?**
“`
GCN灵活性差、为新节点产生embedding要求 额定的操作 ,比方“对齐”:
GCN是 直推式(transductive) 学习,无奈间接泛化到新退出(未见过)的节点;
GraphSAGE是 演绎式(inductive) 学习,能够为新节点输入节点特色。
GCN输入固定:
GCN输入的是节点 惟一确定 的embedding;
GraphSAGE学习的是节点和邻接节点之间的关系,学习到的是一种 映射关系 ,节点的embedding能够随着其邻接节点的变动而变动。
GCN很难利用在超大图上:
无论是拉普拉斯计算还是图卷积过程,因为GCN其须要对 整张图 进行计算,所以计算量会随着节点数的减少而递增。
GraphSAGE通过采样,可能造成 minibatch 来进行批训练,能用在超大图上
“`
**GraphSAGE有什么长处?**
“`
采纳 演绎学习 的形式,学习街坊节点特色关系,失去泛化性更强的embedding;
采样技术,升高空间复杂度,便于构建minibatch用于 批训练 ,还让模型具备更好的泛化性;
多样的聚合函数 ,对于不同的数据集/场景能够选用不同的聚合形式,使得模型更加灵便。
“`
**采样数大于邻接节点数怎么办?**
“`
设采样数量为K:
若节点街坊数少于K,则采纳 有放回 的抽样办法,直到采样出K个节点。
若节点街坊数大于K,则采纳 无放回 的抽样。
“`
**训练好的GraphSAGE如何失去节点Embedding?**
“`
假如GraphSAGE曾经训练好,咱们能够通过以下步骤来取得节点embedding,具体算法请看下图的算法1。
训练过程则只须要将其产生的embedding扔进损失函数计算并反向梯度流传即可。
对图中每个节点的邻接节点进行 采样 ,输出节点及其n阶邻接节点的特征向量
依据K层的 聚合函数 聚合邻接节点的信息
就产生了各节点的embedding
“`

**minibatch的子图是怎么失去的?**

那**和DeepWalk、Node2vec这些有什么不一样?**
“`
DeepWalk、Node2Vec这些embedding算法间接训练每个节点的embedding,实质上仍然是直推式学习,而且须要大量的额定训练能力使他们能预测新的节点。同时,对于embedding的正交变换(orthogonal transformations),这些办法的指标函数是不变的,这意味着生成的向量空间在不同的图之间不是人造泛化的,在再次训练(re-training)时会产生漂移(drift)。
与DeepWalk不同的是,GraphSAGE是通过聚合节点的邻接节点特色产生embedding的,而不是简略的进行一个embedding lookup操作失去。
“`
论文仿真后果:
试验比照了四个基线:随机分类,基于特色的逻辑回归(疏忽图构造),DeepWalk算法,DeepWork+特色;同时还比照了四种GraphSAGE,其中三种在3.3节中曾经阐明,GraphSAGE-GCN是GCNs的演绎版本。具体超参数为:K=2,s1=25,s2=10。程序应用TensorFlow编写,Adam优化器。
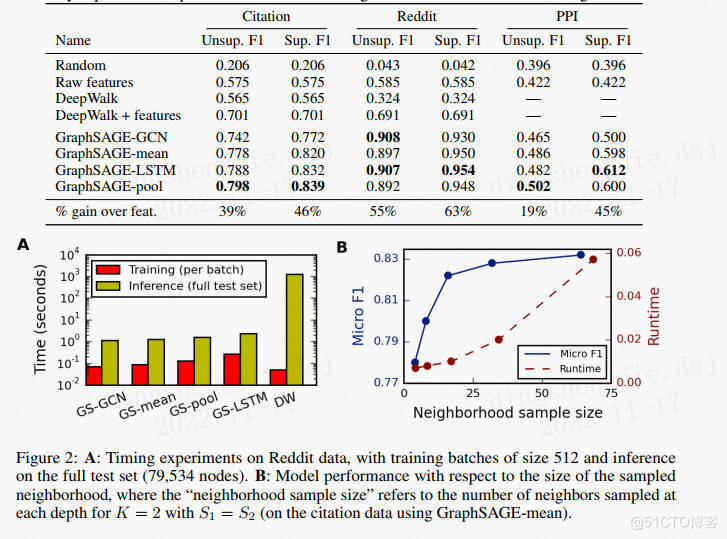
对于跨图泛化的工作,须要学习节点角色而不是训练图的构造。应用跨各种生物蛋白质-蛋白质相互作用(PPI)图,对蛋白质性能进行分类。在20个图表上训练算法,2个图用于测试,2个图用于验证,均匀每图蕴含2373个节点,均匀度为28.8。从试验后果能够看出LSTM和池化办法比Mean和GCN成果更好。
比照不同聚合函数:
如表-1所示,LSTM和POOL办法成果最好,与其它办法相比有显著差别,LSTM和POOL之间无显著差别,但LSTM比POOL慢得多(≈2x),使POOL聚合器在总体上略有劣势。
### 1.1.2 更多问题
“`
采样
为什么要采样?
采样数大于邻接节点数怎么办?
采样的街坊节点数应该选取多大?
每一跳采样须要一样吗?
适宜有向边吗?
采样是随机的吗?
聚合函数
聚合函数的选取有什么要求?
GraphSAGE论文中提供多少种聚合函数?
均值聚合的操作是怎么的?
pooling聚合的操作是怎么的?
应用LSTM聚合时须要留神什么?
均值聚合和其余聚合函数有啥区别?
max-和mean-pooling有什么区别?
这三种聚合办法,哪种比拟好?
个别聚合多少层?层数越多越好吗?
什么时候和GCN的聚合模式“等价”?
无监督学习
GraphSAGE怎么进行无监督学习?
GraphSAGE如何定义邻近和远处的节点?
如何计算无监督GraphSAGE的损失函数?
GraphSAGE是怎么随机游走的?
GraphSAGE什么时候思考边的权重了?
训练
如果只有图、没有节点特色,是否应用GraphSAGE?
训练好的GraphSAGE如何失去节点Embedding?
minibatch的子图是怎么失去的?
减少了新的节点来训练,须要为所有“旧”节点从新输入embeding吗?
GraphSAGE有监督学习有什么不一样的中央吗?
“`
参考链接:https://zhuanlan.zhihu.com/p/184991506
https://blog.csdn.net/yyl424525/article/details/100532849
## 1.2 PinSAGE
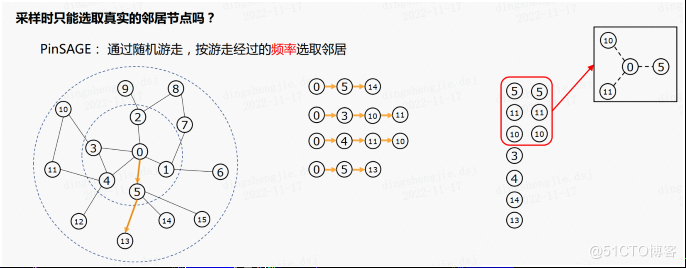
采样时只能选取实在的街坊节点吗?如果构建的是一个与虚构街坊相连的子图有什么长处?PinSAGE 算法将会给咱们解答,PinSAGE 算法通过屡次随机游走,按游走通过的频率选取街坊,上图右侧为进行随机游走失去的节点序列,统计序列的频数能够发现节点5,10,11的频数为2,其余为1,当咱们心愿采样三个节点时,咱们选取5,10,11作为0号节点的虚构街坊。之后如果心愿失去0号节点的二阶虚构街坊则在已采样的节点持续进行随机游走即可。
回到上述问题,采样时选取虚构街坊有什么益处?**这种采样形式的益处是咱们能更快的聚合到远处节点的信息。**。实际上如果是依照 GraphSAGE 算法的形式生成子图,在聚合的过程中,非一阶街坊的信息能够通过消息传递逐步传到核心,然而随着间隔的增大,离核心越远的节点,其信息在传递过程中就越艰难,甚至可能无奈传递到;如果依照 PinSAGE 算法的形式生成子图,有肯定的概率能够将非一阶街坊与核心间接相连,这样就能够疾速聚合到多阶街坊的信息
### 1.2.1论文角度看PinSAGE
**和GraphSAGE相比,PinSAGE改良了什么?**
* 采样 :应用重要性采样代替GraphSAGE的平均采样;
* 聚合函数 :聚合函数思考了边的权重;
* 生产者-消费者模式的minibatch构建 :在CPU端采样节点和构建特色,构建计算图;在GPU端在这些子图上进行卷积运算;从而能够低提早地随机游走构建子图,而不须要把整个图存在显存中。
* 高效的MapReduce推理 :能够分布式地为百万以上的节点生成embedding,最大化地缩小反复计算。
这里的计算图,指的是用于卷积运算的部分图(或者叫子图),通过采样来造成;与TensorFlow等框架的计算图不是一个概念。
**PinSAGE应用多大的计算资源?**
“`
训练时,PinSAGE应用32核CPU、16张Tesla K80显卡、500GB内存;
推理时,MapReduce运行在378个d2.8xlarge Amazon AWS节点的Hadoop2集群。
“`
**PinSAGE和node2vec、DeepWalk这些有啥区别?**
“`
node2vec,DeepWalk是无监督训练;PinSAGE是有监督训练;
node2vec,DeepWalk不能利用节点特色;PinSAGE能够;
node2vec,DeepWalk这些模型的参数和节点数呈线性关系,很难利用在超大型的图上;
“`
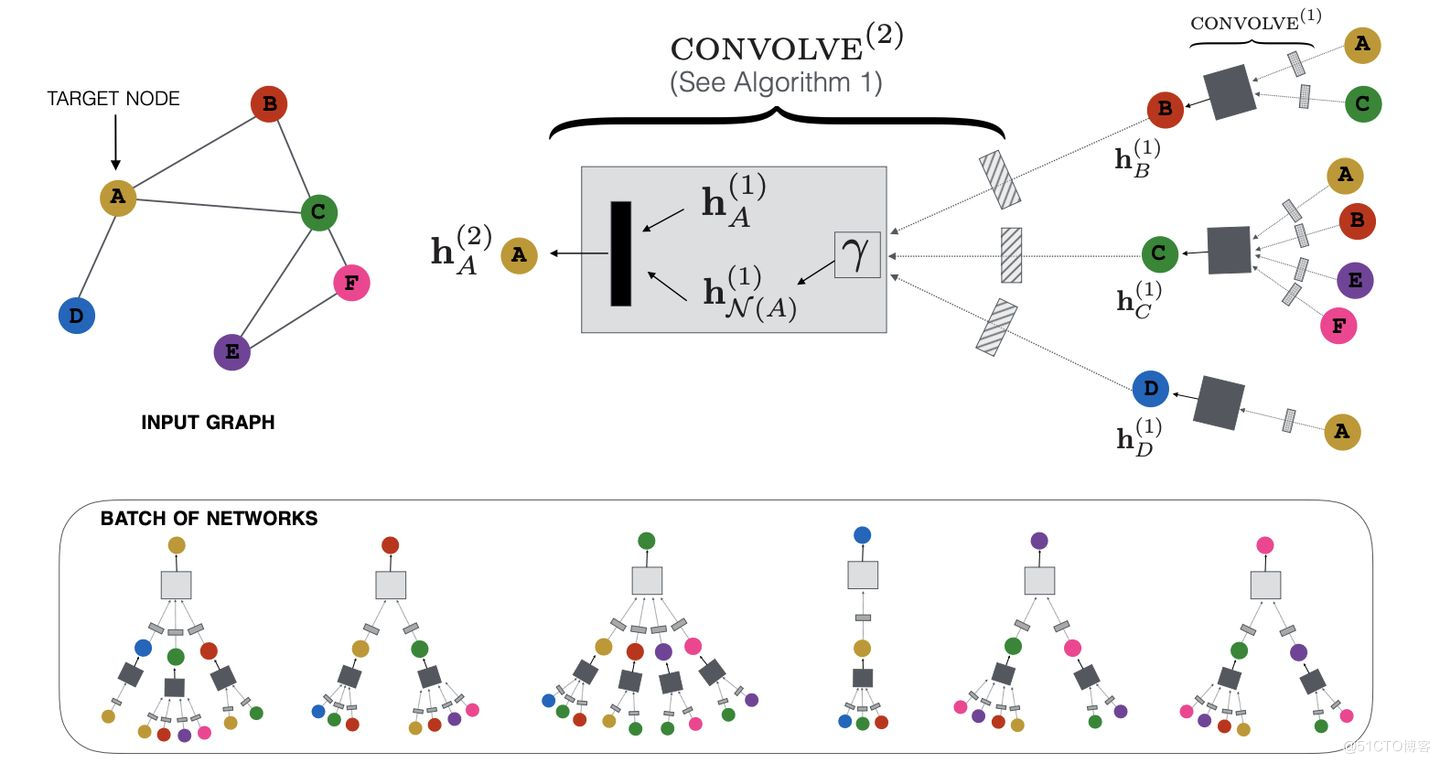
**PinSAGE的单层聚合过程是怎么的?**
和GraphSAGE一样,PinSAGE的外围就是一个 部分卷积算子 ,用来学习如何聚合街坊节点信息。
如下图算法1所示,PinSAGE的聚合函数叫做CONVOLVE。次要分为3局部:
* 聚合 (第1行):k-1层街坊节点的表征通过一层DNN,而后聚合(能够思考边的权重),是聚合函数符号,聚合函数能够是max/mean-pooling、加权求和、求均匀;
* 更新 (第2行): 拼接 第k-1层指标节点的embedding,而后再通过另一层DNN,造成指标节点新的embedding;
* 归一化 (第3行): 归一化 指标节点新的embedding,使得训练更加稳固;而且归一化后,应用近似最近街坊搜寻的效率更高。

**PinSAGE是如何采样的?**
“`
如何采样这个问题从另一个角度来看就是:如何为指标节点构建街坊节点。
和GraphSAGE的平均采样不一样的是,PinSAGE应用的是重要性采样。
PinSAGE对街坊节点的定义是:对指标节点 影响力最大 的T个节点。
“`
**PinSAGE的街坊节点的重要性是如何计算的?**
“`
其影响力的计算方法有以下步骤:
从指标节点开始随机游走;
应用 正则 来计算节点的“拜访次数”,失去重要性分数;
指标节点的街坊节点,则是重要性分数最高的前T个节点。
这个重要性分数,其实能够近似看成Personalized PageRank分数。
对于随机游走,能够浏览《Pixie: A System for Recommending 3+ Billion Items to 200+ Million Users in Real-Time》
“`
**重要性采样的益处是什么?**
“`
和GraphSAGE一样,能够使得 街坊节点的数量固定 ,便于管制内存/显存的应用。
在聚合街坊节点时,能够思考节点的重要性;在PinSAGE实际中,应用的就是 加权均匀 (weighted-mean),原文把它称作 importance pooling 。
“`
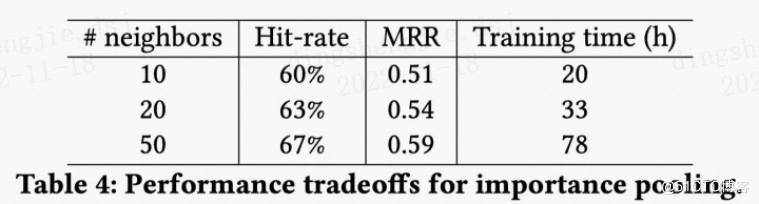
**采样的大小是多少比拟好?**
“`
从PinSAGE的试验能够看出,随着街坊节点的减少,而收益会递加;
并且两层GCN在 街坊数为50 时可能更好的抓取节点的街坊信息,同时放弃运算效率。
“`
**PinSage论文中还介绍了落地过程中采纳的大量工程技巧。**
1. **负样本生成**:首先是简略采样:在每个minibatch蕴含节点的范畴之外随机采样500个item作为minibatch所有正样本共享的负样本汇合。但思考到理论场景中模型须要从20亿的物品item汇合中辨认出最类似的1000个,即要从2百万中辨认出最类似的那一个,只是简略采样会导致模型分辨的粒度过粗,分辨率只到500分之一,因而减少一种“hard”负样本,即对于每个 对,和物品q有些类似但和物品i不相干的物品汇合。这种样本的生成形式是将图中节点依据绝对节点q的个性化PageRank分值排序,随机选取排序地位在2000~5000的物品作为“hard”负样本,以此进步模型分辨正负样本的难度。
2. **渐进式训练(Curriculum training**:如果训练全程都应用hard负样本,会导致模型收敛速度减半,训练时长加倍,因而PinSage采纳了一种Curriculum训练的形式,这里我了解是一种渐进式训练方法,即第一轮训练只应用简略负样本,帮忙模型参数疾速收敛到一个loss比拟低的范畴;后续训练中逐渐退出hard负样本,让模型学会将很类似的物品与些微类似的辨别开,形式是第n轮训练时给每个物品的负样本汇合中减少n-1个hard负样本。
3. **样本的特色信息**:Pinterest的业务场景中每个pin通常有一张图片和一系列的文字标注(题目,形容等),因而原始图中每个节点的特色示意由图片Embedding(4096维),文字标注Embedding(256维),以及节点在图中的度的log值拼接而成。其中图片Embedding由6层全连贯的VGG-16生成,文字标注Embedding由Word2Vec训练失去。
4. **基于random walk的重要性采样**:用于街坊节点采样,这一技巧在下面的算法了解局部曾经解说过,此处不再赘述。
5. **基于重要性的池化操作**:这一技巧用于上一节Convolve算法中的 函数中,聚合通过一层dense层之后的街坊节点Embedding时,基于random walk计算出的节点权重做聚合操作。据论文形容,这一技巧在离线评估指标中晋升了46%。
6. **on-the-fly convolutions:疾速卷积操作**,这个技巧次要是绝对原始GCN中的卷积操作:特色矩阵与全图拉普拉斯矩阵的幂相乘。波及到全图的都是计算量超高,这里GraphSage和PinSage都是统一地应用采样街坊节点动静构建部分计算图的办法晋升训练效率,只是二者采样的形式不同。
7. **生产者消费者模式构建minibatch**:这个点次要是为了进步模型训练时GPU的利用率。保留原始图构造的街坊表和数十亿节点的特色矩阵只能放在CPU内存中,GPU执行convolve卷积操作时每次从CPU取数据是很耗时的。为了解决这个问题,PinSage应用re-index技术创立以后minibatch内节点及其街坊组成的子图,同时从数十亿节点的特色矩阵中提取出该子图节点对应的特色矩阵,留神提取后的特色矩阵中的节点索引要与后面子图中的索引保持一致。这个子图的邻接列表和特色矩阵作为一个minibatch送入GPU训练,这样一来,convolve操作过程中就没有GPU与CPU的通信需要了。训练过程中CPU应用OpenMP并设计了一个producer-consumer模式,CPU负责提取特色,re-index,负采样等计算,GPU只负责模型计算。这个技巧升高了一半的训练耗时。
8. **多GPU训练超大batch**:前向流传过程中,各个GPU等分minibatch,共享一套参数,反向流传时,将每个GPU中的参数梯度都聚合到一起,执行同步SGD。为了适应海量训练数据的须要,增大batchsize从512到4096。为了在超大batchsize下疾速收敛保障泛化精度,采纳warmup过程:在第一个epoch中将学习率线性晋升到最高,前面的epoch中再逐渐指数降落。
9. **应用MapReduce高效推断**:模型训练实现后生成图中各个节点的Embedding过程中,如果间接应用上述PinSage的minibatch算法生Embedding,会有大量的反复计算,如计算以后target节点的时候,其相当一部分街坊节点曾经计算过Embedding了,而当这些街坊节点作为target节点的时候,以后target节点极有可能须要再从新计算一遍,这一部分的反复计算既耗时又节约。
### 1.2.2更多问题
“`
聚合函数
PinSAGE的单层聚合过程是怎么的?
为什么要将街坊节点的聚合embedding和以后节点的拼接?
采样
PinSAGE是如何采样的?
PinSAGE的街坊节点的重要性是如何计算的?
重要性采样的益处是什么?
采样的大小是多少比拟好?
MiniBatch
PinSAGE的minibatch和GraphSAGE有啥不一样?
batch应该选多大?
训练
PinSAGE应用什么损失函数?
PinSAGE如何定义标签(正例/负例)?
PinSAGE用什么办法进步模型训练的鲁棒性和收敛性?
负采样
PinSAGE如何进行负采样?
训练时简略地负采样,会有什么问题?
如何解决简略负采样带来的问题?
如果只应用“hard”负样本,会有什么问题?
如何解决只应用“hard”负采样带来的问题?
如何辨别采样、负采样、”hard“负采样?
推理
间接为应用训练好的模型产生embedding有啥问题?
如何解决推理时反复计算的问题?
上游工作如何利用PinSAGE产生的embedding?
如何为用户进行个性化举荐?
工程性技巧
pin样本的特色如何构建?
board样本的特色如何构建?
如何应用多GPU并行训练PinSAGE?
PinSAGE为什么要应用生产者-消费者模式?
PinSAGE是如何应用生产者-消费者模式?
“`
https://zhuanlan.zhihu.com/p/195735468
https://zhuanlan.zhihu.com/p/133739758?utm_source=wechat_session&utm_id=0
## 1.3 小结
学习大图、一直扩大的图,未见过节点的表征,是一个很常见的利用场景。GraphSAGE通过训练聚合函数,实现优化未知节点的示意办法。之后提出的GAN(图注意力网络)也针对此问题优化。
论文中提出了:传导性问题和演绎性问题,传导性问题是已知全图状况,计算节点表征向量;演绎性问题是在不齐全理解全图的状况下,训练节点的表征函数(不是间接计算向量示意)。
图工具的处理过程每轮迭代( 一次propagation)个别都蕴含:收集信息、聚合、更新,从本文也能够更好地了解,其中聚合的重要性,及优化办法。
GraohSage次要奉献如下:
* 针对问题:大图的节点表征
* 后果:训练出的模型可利用于表征没见过的节点
* 外围办法:改良图卷积办法;从街坊节点中采样;思考了节点特色,退出更简单的特色聚合办法
个别状况下一个节点的表式通过聚合它k跳之内的邻近节点计算,而全图的示意则通过对所有节点的池化计算。GIN应用了WL-test办法,即图同构测试,它是一个辨别网络结构的强效办法,也是通过迭代聚合街坊的办法来更新节点,它的弱小在于应用了injective(见后)聚合更新办法。而这里要评测GNN是否能达到相似WL-test的成果。文中还应用了多合集multiset的概念,指可能蕴含反复元素的汇合。
GIN次要奉献如下:
* 展现了GNN模型可达到与WL-test相似的图构造辨别成果
* 设计了聚合函数和Readout函数,使GNN能达到更好的辨别成果
* 发现GCN及GraphSAGE无奈很好表白图构造,而GNN能够
* 开发了简略的网络结构GIN(图同构网络),它的辨别和示意能力与WL-test相似。
# 2.街坊聚合
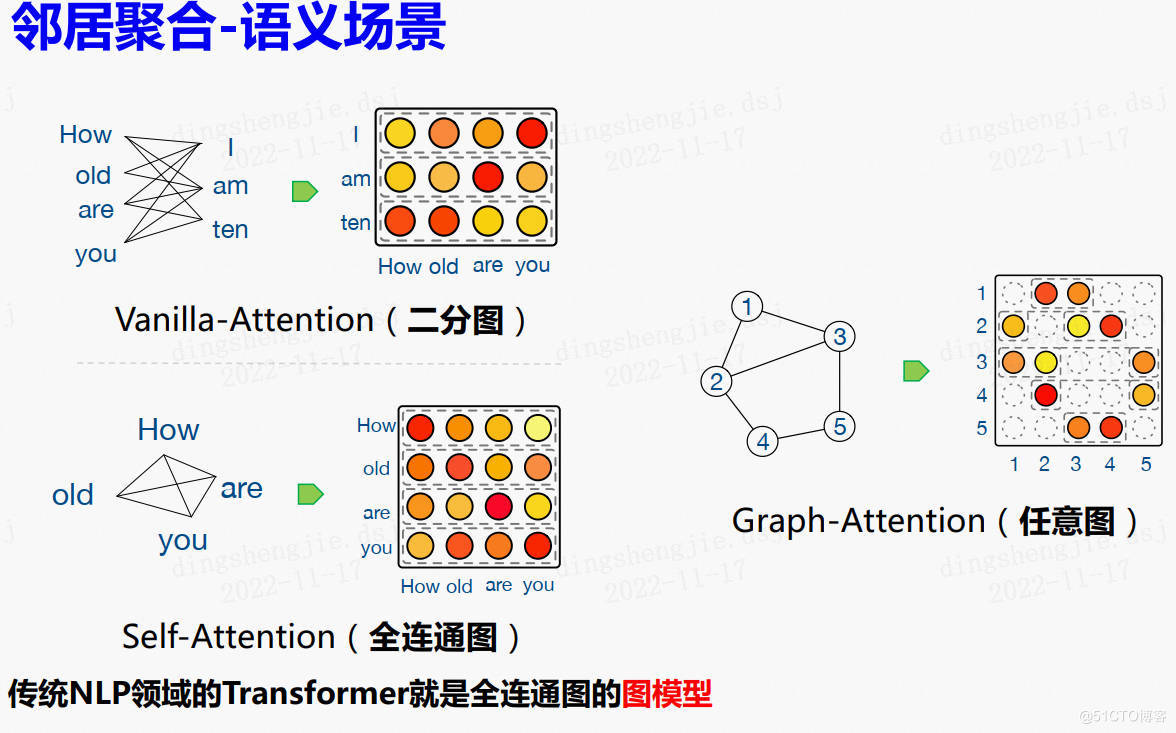
在图采样之后,咱们须要进行街坊聚合的操作。经典的街坊聚合函数包含取均匀、取最大值、求和。
评估聚合表达能力的指标——单射(一对一映射),在上述三种经典聚合函数中,取均匀偏向于学习散布,取最大值偏向于疏忽反复值,这两个不属于单射,而求和可能保留街坊节点的残缺信息,是单射。单射的益处是能够保障对聚合后的后果可辨别。

## 2.1 GIN模型的聚合函数
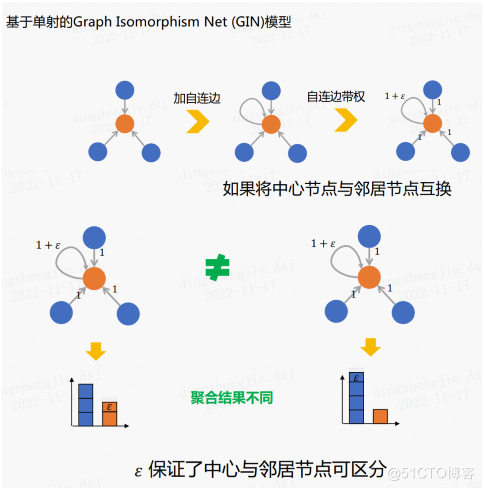
Graph Isomorphic Net(GIN)的聚合局部是基于单射的。
如上图所示,GIN的聚合函数应用的是求和函数,它非凡的一点是在核心节点加了一个自连边(自环),之后对自连边进行加权。
这样做的益处是即便咱们调换了核心节点和街坊节点,失去的聚合后果仍旧是不同的。所以带权重的自连边可能保障核心节点和街坊节点可辨别。
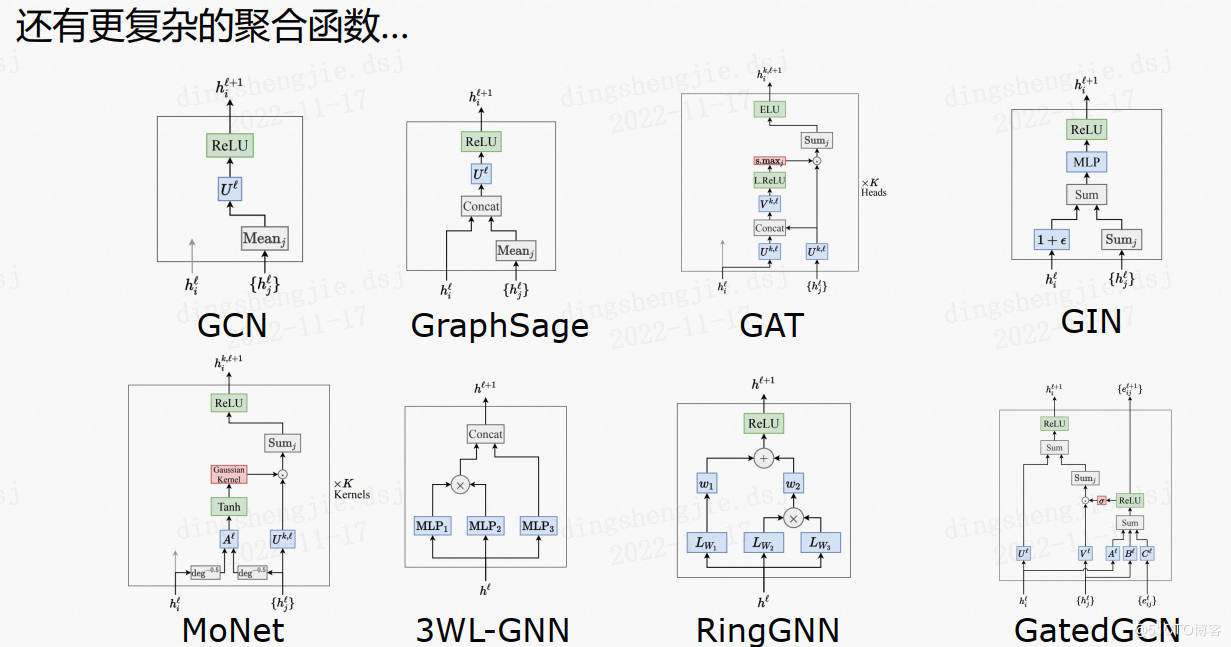
## 2.2其余简单的聚合函数
## 2.3 令居聚合语义场景
# 3.数据集介绍
数据源:http://snap.stanford.edu/graphsage/ 斯坦福
## 3.1 Citation数据集
应用科学网引文数据集,将学术论文分类为不同的主题。数据集共蕴含302424个节点,均匀度9.15,应用2000-2004年数据作为训练集,2005年数据作为测试集。应用节点的度以及论文摘要的句嵌入作为特色。
## 3.2 Reddit数据集
https://aistudio.baidu.com/aistudio/datasetdetail/177810
将Reddit帖子归类为属于不同社区。数据集蕴含232965个帖子,均匀度为492。应用现成的300维GloVe Common Crawl单词向量;对于每个帖子,应用特色蕴含:(1) 帖子题目的均匀嵌入 (2) 帖子所有评论的均匀嵌入 (3) 帖子的分数 (4)帖子的评论数量
为了对社区进行抽样,依据 2014 年的评论总数对社区进行了排名,并抉择了排名 [11,50](含)的社区。省略了最大的社区,因为它们是大型的通用默认社区,大大扭曲了类散布。抉择了在这些社区的联结上定义的图中最大的连通重量。
更多数据资料见:
http://files.pushshift.io/reddit/comments/
https://github.com/dingidng/reddit-dataset
最新数据曾经更新到2022.10了
## 3.3 PPI(Protein–protein interactions)蛋白质交互作用
https://aistudio.baidu.com/aistudio/datasetdetail/177807
PPI 网络是蛋白质相互作用(Protein-Protein Interaction,PPI)网络的简称,在GCN中次要用于节点分类工作
PPI是指两种或以上的蛋白质联合的过程,通常旨在执行其生化性能。
个别地,如果两个蛋白质独特参加一个生命过程或者协同实现某一性能,都被看作这两个蛋白质之间存在相互作用。多个蛋白质之间的简单的相互作用关系能够用PPI网络来形容。
PPI数据集共24张图,每张图对应不同的人体组织,均匀每张图有2371个节点,共56944个节点818716条边,每个节点特色长度为50,其中蕴含地位基因集,基序集和免疫学特色。基因本体基作为label(总共121个),label不是one-hot编码。
* alid_feats.npy文件保留节点的特色,shape为(56944, 50)(节点数目,特色维度),值为0或1,且1的数目稀少
* ppi-class_map.json为节点的label文件,shape为(121, 56944),每个节点的label为121维
* ppi-G.json文件为节点和链接的形容信息,节点:{“test”: true, “id”: 56708, “val”: false}, 示意节点id为56708的节点是否为test集或者val集,链接:”links”: [{“source”: 0, “target”: 372}, {“source”: 0, “target”: 1101}, 示意节点id为0的节点和为1101的节点之间有links,
* ppi-walks.txt文件中为链接信息
* ppi-id_map.json文件为节点id信息
参考链接:
https://blog.csdn.net/ziqingnian/article/details/112979175
# 4 基于PGL算法实际
## 4.1 GraphSAGE
GraphSAGE是一个通用的演绎框架,它利用节点特色信息(例如,文本属性)为以前看不见的数据无效地生成节点嵌入。GraphSAGE 不是为每个节点训练独自的嵌入,而是学习一个函数,该函数通过从节点的本地邻域中采样和聚合特色来生成嵌入。基于PGL,咱们重现了GraphSAGE算法,在Reddit Dataset中达到了与论文等同程度的指标。此外,这是PGL中子图采样和训练的一个例子。
超参数
“`
epoch: Number of epochs default (10)
normalize: Normalize the input feature if assign normalize.
sample_workers: The number of workers for multiprocessing subgraph sample.
lr: Learning rate.
symmetry: Make the edges symmetric if assign symmetry.
batch_size: Batch size.
samples: The max neighbors for each layers hop neighbor sampling. (default: [25, 10])
hidden_size: The hidden size of the GraphSAGE models.
“`
“`
parser = argparse.ArgumentParser(description=’graphsage’)
parser.add_argument(
“–normalize”, action=’store_true’, help=”normalize features”) # normalize:归一化节点特色
parser.add_argument(
“–symmetry”, action=’store_true’, help=”undirect graph”) # symmetry:聚合函数的对称性
parser.add_argument(“–sample_workers”, type=int, default=5) # sample_workers:多线程数据读取器的线程个数
parser.add_argument(“–epoch”, type=int, default=10)
parser.add_argument(“–hidden_size”, type=int, default=128)
parser.add_argument(“–batch_size”, type=int, default=128)
parser.add_argument(“–lr”, type=float, default=0.01)
parser.add_argument(‘–samples’, nargs=’+’, type=int, default=[25, 10]) # samples_1:第一级街坊采样时候抉择的最大街坊个数(默认25)#,samples_2:第而级街坊采样时候抉择的最大街坊个数(默认10)
“`
局部后果展现:
“`
[INFO] 2022-11-18 16:45:44,177 [ train.py: 63]: Batch 800 train-Loss [0.5213774] train-Acc [0.9140625]
[INFO] 2022-11-18 16:45:45,783 [ train.py: 63]: Batch 900 train-Loss [0.65641916] train-Acc [0.875]
[INFO] 2022-11-18 16:45:47,385 [ train.py: 63]: Batch 1000 train-Loss [0.57411766] train-Acc [0.921875]
[INFO] 2022-11-18 16:45:48,977 [ train.py: 63]: Batch 1100 train-Loss [0.68337256] train-Acc [0.890625]
[INFO] 2022-11-18 16:45:50,434 [ train.py: 160]: Runing epoch:9 train_loss:[0.58635516] train_acc:[0.90786038]
[INFO] 2022-11-18 16:45:57,836 [ train.py: 165]: Runing epoch:9 val_loss:0.55885834 val_acc:0.9139818
[INFO] 2022-11-18 16:46:05,259 [ train.py: 169]: Runing epoch:9 test_loss:0.5578749 test_acc:0.91468066
100%|███████████████████████████████████████████| 10/10 [06:02<00:00, 36.29s/it]
[INFO] 2022-11-18 16:46:05,260 [ train.py: 172]: Runs 0: Model: graphsage Best Test Accuracy: 0.918849
“`
目前官网最佳性能是95.7%,我这里没有调参
| Aggregator | Accuracy_me_10 epochs | Accuracy_200 epochs|Reported in paper_200 epochs|
| ——– | ——– | ——– |——– |
| Mean | 91.88% | 95.70% | 95.0% |
其余聚合器下官网和论文性能比照:
| Aggregator | Accuracy_200 epochs|Reported in paper_200 epochs|
| ——– | ——– |——– |
| Meanpool | 95.60% | 94.8% |
| Maxpool | 94.95% | 94.8% |
| LSTM | 95.13% | 95.4% |
## 4.2 Graph Isomorphism Network (GIN)
图同构网络(GIN)是一个简略的图神经网络,冀望达到Weisfeiler-Lehman图同构测试的能力。基于 PGL重现了 GIN 模型。
超参数
* data_path:数据集的根门路
* dataset_name:数据集的名称
* fold_idx:拆分的数据集折叠。这里咱们应用10折穿插验证
* train_eps:是否参数是可学习的。
“`
parser.add_argument(‘–data_path’, type=str, default=’./gin_data’)
parser.add_argument(‘–dataset_name’, type=str, default=’MUTAG’)
parser.add_argument(‘–batch_size’, type=int, default=32)
parser.add_argument(‘–fold_idx’, type=int, default=0)
parser.add_argument(‘–output_path’, type=str, default=’./outputs/’)
parser.add_argument(‘–use_cuda’, action=’store_true’)
parser.add_argument(‘–num_layers’, type=int, default=5)
parser.add_argument(‘–num_mlp_layers’, type=int, default=2)
parser.add_argument(‘–feat_size’, type=int, default=64)
parser.add_argument(‘–hidden_size’, type=int, default=64)
parser.add_argument(
‘–pool_type’,
type=str,
default=”sum”,
choices=[“sum”, “average”, “max”])
parser.add_argument(‘–train_eps’, action=’store_true’)
parser.add_argument(‘–init_eps’, type=float, default=0.0)
parser.add_argument(‘–epochs’, type=int, default=350)
parser.add_argument(‘–lr’, type=float, default=0.01)
parser.add_argument(‘–dropout_prob’, type=float, default=0.5)
parser.add_argument(‘–seed’, type=int, default=0)
args = parser.parse_args()
“`
GIN github代码复现含数据集下载:How Powerful are Graph Neural Networks? [https://github.com/weihua916/powerful-gnns](https://github.com/weihua916/powerful-gnns)
https://github.com/weihua916/powerful-gnns/blob/master/dataset.zip
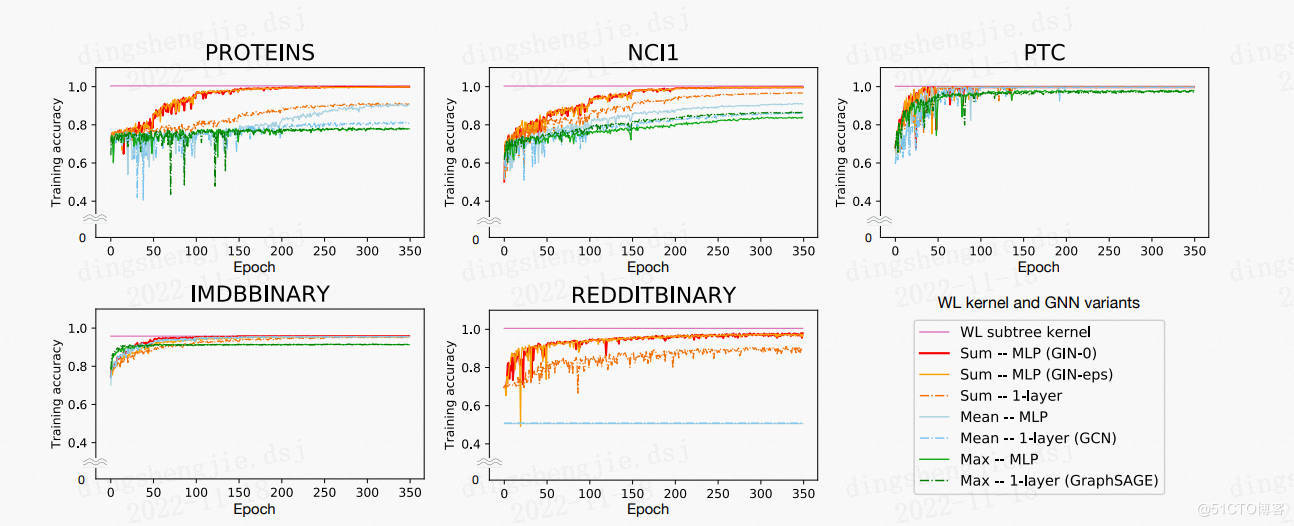
论文应用 9 个图形分类基准:**4 个生物信息学数据集(MUTAG、PTC、NCI1、PROTEINS)** 和 **5 个社交网络数据集(COLLAB、IMDB-BINARY、IMDB-MULTI、REDDITBINARY 和 REDDIT-MULTI5K)(Yanardag & Vishwanathan,2015)**。 重要的是,我指标不是让模型依赖输出节点特色,而是次要从网络结构中学习。因而,在生物信息图中,节点具备分类输出特色,但在社交网络中,它们没有特色。 对于社交网络,按如下形式创立节点特色:对于 REDDIT 数据集,将所有节点特征向量设置为雷同(因而,这里的特色是无信息的); 对于其余社交图,咱们应用节点度数的 one-hot 编码。
**社交网络数据集。**
* IMDB-BINARY 和 IMDB-MULTI 是电影合作数据集。每个图对应于每个演员/女演员的自我网络,其中节点对应于演员/女演员,如果两个演员/女演员呈现在同一部电影中,则在两个演员/女演员之间绘制一条边。每个图都是从预先指定的电影类型派生的,工作是对其派生的类型图进行分类。
* REDDIT-BINARY 和 REDDIT-MULTI5K 是均衡数据集,其中每个图表对应一个在线探讨线程,节点对应于用户。如果其中至多一个节点回应了另一个节点的评论,则在两个节点之间绘制一条边。工作是将每个图分类到它所属的社区或子版块。
* COLLAB 是一个迷信合作数据集,源自 3 个公共合作数据集,即高能物理、凝聚态物理和天体物理。每个图对应于来自每个畛域的不同钻研人员的自我网络。工作是将每个图分类到相应钻研人员所属的畛域。
**生物信息学数据集。**
* MUTAG 是一个蕴含 188 个诱变芳香族和杂芳香族硝基化合物的数据集,具备 7 个离散标签。
* PROTEINS 是一个数据集,其中节点是二级构造元素 (SSE),如果两个节点在氨基酸序列或 3D 空间中是相邻节点,则它们之间存在一条边。 它有 3 个离散标签,代表螺旋、薄片或转弯。
* PTC 是一个蕴含 344 种化合物的数据集,报告了雄性和雌性大鼠的致癌性,它有 19 个离散标签。
* NCI1 是由美国国家癌症研究所 (NCI) 公开提供的数据集,是通过筛选以克制或克制一组人类肿瘤细胞系成长的化学化合物均衡数据集的子集,具备 37 个离散标签。
局部后果展现:
“`
[INFO] 2022-11-18 17:12:34,203 [ main.py: 98]: eval: epoch 347 | step 2082 | | loss 0.448468 | acc 0.684211
[INFO] 2022-11-18 17:12:34,297 [ main.py: 98]: eval: epoch 348 | step 2088 | | loss 0.393809 | acc 0.789474
[INFO] 2022-11-18 17:12:34,326 [ main.py: 92]: train: epoch 349 | step 2090 | loss 0.401544 | acc 0.8125
[INFO] 2022-11-18 17:12:34,391 [ main.py: 98]: eval: epoch 349 | step 2094 | | loss 0.441679 | acc 0.736842
[INFO] 2022-11-18 17:12:34,476 [ main.py: 92]: train: epoch 350 | step 2100 | loss 0.573693 | acc 0.7778
[INFO] 2022-11-18 17:12:34,485 [ main.py: 98]: eval: epoch 350 | step 2100 | | loss 0.481966 | acc 0.789474
[INFO] 2022-11-18 17:12:34,485 [ main.py: 103]: best evaluating accuracy: 0.894737
“`
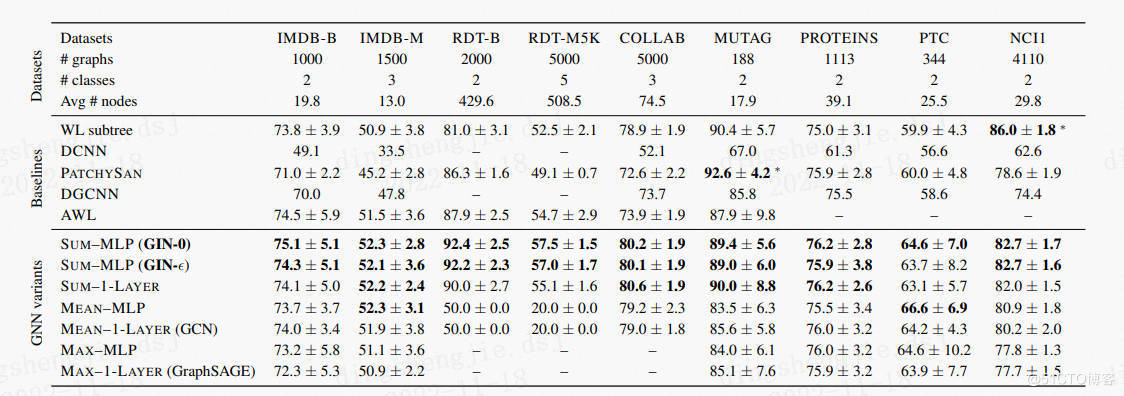
后果整合:(这里就不把数据集一一跑一遍了)
| | MUTAG | COLLAB | IMDBBINARY | IMDBMULTI |
| ——– | ——– | ——– |——– | ——– |
| PGL result | 90.8 | 78.6 |76.8 |50.8|
| paper reuslt | 90.0 | 80.0 | 75.1 | 52.3 |
原论文所有后果:
发表回复