根底定义:
`\d`:匹配数字
`\w`:匹配数字或字母
`.`:匹配任意字符
`\s`:匹配空格
`*`:任意个字符
`+`:多个
`?`:0/1个
`{n}`:n个
`{n,m}`:n-m个
`[]`:标适范畴
`A|B`:能够匹配A或B
`^`示意行的结尾
`$`示意行的完结
特殊字符须要用`'\'`转译.例:'-'=>`\-`
例子:
1. 例:
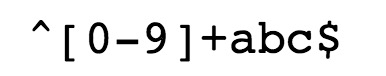
* ^ 为匹配输出字符串的开始地位。
* [0-9]+匹配多个数字, [0-9] 匹配单个数字,+ 匹配一个或者多个。
* abc$匹配字母 abc 并以 abc 结尾,$为匹配输出字符串的完结地位。
2. 例:
咱们在写用户注册表单时,只容许用户名蕴含字符、数字、下划线和连贯字符(-),并设置用户名的长度,咱们就能够应用以下正则表达式来设定。
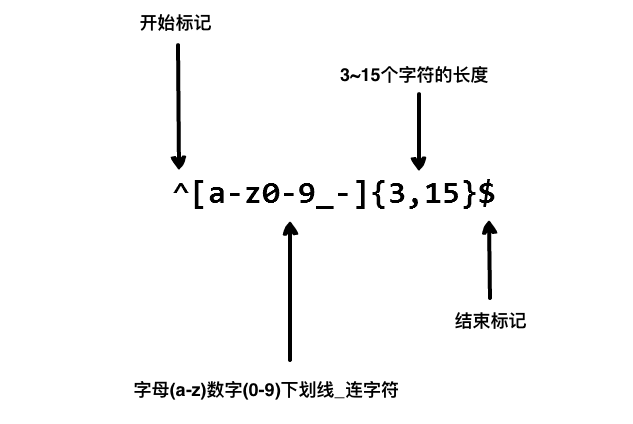在JavaScript中应用正则:
- RegExp:是正则表达式(regular expression)的简写。
-
语法:
var patt = new RegExp(pattern,modifiers) 或者 var patt = /pattern/modifiers 例: var re = new RegExp("w+"); 等价于 var re = /w+/; - i – 修饰符是用来执行不辨别大小写的匹配。
-
g – 修饰符是用于执行全文的搜寻(而不是在找到第一个就进行查找,而是找到所有的匹配)。
test():查问指定字符返回true/false 例:re.test('sting') exec():查问指定字符返回被找到的值/null 例:re.exec('sting')
在python当中应用正则
- re模块
- 转译:
s = 'ABC\\001'等价于s = r'ABC\001'
=>'ABC-001'match()办法判断是否匹配,返回一个Match对象/None
import re
re.match(r'^d{3}-d{3,8}$', '010-12345')
//<_sre.SRE_Match object; span=(0, 9), match='010-12345'>
re.match(r'^d{3}-d{3,8}$', '010 12345')
//none- 切割字符串
'a b c'.split(' ')
// ['a', 'b', '', '', 'c']
// 无奈解决空格
re.split(r'[s,;]+', 'a,b;; c d')
// ['a', 'b', 'c', 'd']
// 主动解决- 分组
用()示意的就是要提取的分组(Group)
t = '19:05:30'
m = re.match(r'^(0[0-9]|1[0-9]|2[0-3]|[0-9]):(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9]):(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])$', t)
m.groups()
// ('19', '05', '30')
发表回复