前言:
如果你正在经验工作调整,那么倡议你肯定要珍藏起来,这是一份预防互联网寒冬的必备指南~
1.输入的后果是什么? 怎么扭转循环1输入后果变成循环2的打印后果
for(var i = 0;i<5;i++){
setTimeout(()=>{
console.log(i) //五次5
},1000)
console.log(i) //0 1 2 3 4
}
for(let i = 0;i<5;i++){
setTimeout(()=>{
console.log(i) // 0 1 2 3 4
},1000)
}
// 扭转
for(var i = 0;i<5;i++){
(function(j) {
setTimeout( function timer() {
console.log( j );
}, j*1000 );
})(i);
}:::tips
这是因为setTimeout是异步执行,每一次for循环的时候,setTimeout都执行一次,然而外面的函数没有被执行,而是被放到了工作队列里,期待执行。只有主线上的工作执行完,才会执行工作队列里的工作。也就是说它会等到for循环全副运行结束后,才会执行fun函数,然而当for循环完结后此时i的值曾经变成了5,因而尽管定时器跑了5秒,管制台上的内容仍然是5。
同时因为for循环头部的let不仅将i绑定到for循环中,事实上它将其从新绑定到循环体的每一次迭代中,确保上一次迭代完结的值从新被赋值。setTimeout外面的function()属于一个新的域,通过var定义的变量是无奈传入到这个函数执行域中的,通过应用let来申明块变量能作用于这个块,所以function就能应用i这个变量了;这个匿名函数的参数作用域和for参数的作用域不一样,是利用了这一点来实现的。这个匿名函数的作用域有点相似类的属性,是能够被内层办法应用的。
最初呢 应用var申明的变量会存在变量晋升的问题,而应用let就不存在变量晋升的问题。如果非要应用var当做循环循环头的话,呈现循环后打印出的后果截然不同的问题,能够应用传参或者闭包的形式
:::
2.数组循环形式有哪些
(1)、forEach:会遍历数组, 没有返回值, 不容许在循环体内写return, 会扭转原来数组的内容.forEach()也能够循环对象
(2)、map:遍历数组, 会返回一个新数组, 不会扭转原来数组里的内容
(3)、filter:会过滤掉数组中不满足条件的元素, 把满足条件的元素放到一个新数组中, 不扭转原数组
(4)、reduce:
let array = [1, 2, 3, 4];
let temp = array.reduce((x, y) => {
console.log("x,"+x);
console.log("y,"+y);
console.log("x+y,",Number(x)+Number(y));
return x + y;
});
console.log(temp); // 10
console.log(array); // [1, 2, 3, 4](5)、every:遍历数组, 每一项都是true, 则返回true, 只有有一个是false, 就返回false
(6)、some:遍历数组的每一项, 有一个返回true, 就进行循环
3.script标签中defer和async的区别?
:::tips
defer:script被异步加载后并不会⽴刻执⾏,而是要等到整个页面在内存中失常渲染完结后,才会执行。多 个 defer 脚本会依照它们在页面呈现的程序加载。
:::
:::tips
async:同样是异步加载脚本,区别是脚本加载结束后⽴即执⾏,这导致async属性下的脚本是乱序的,对于script有先后依赖关系的状况,并不适⽤。
:::
4.用 setTimeout()办法来模仿 setInterval()与 setInterval()之间的什么区别?
首先来看 setInterval 的缺点,应用 setInterval()创立的定时器确保了定时器代码规定地插 入队列中。这种形式的问题在于,如果定时器代码在代码再次增加到队列之前还没实现执行, 后果就会导致定时器代码间断运行好几次,而之间没有距离。<br /> 所以可能会呈现上面的状况:以后执行栈执行的工夫很长,导致事件队列里边积攒多个定时器退出的事件,当执行栈完结后,这些事件会顺次执行而之间没有任何进展,不能达到距离一段时间执行的成果。<br />不过侥幸的是:javascript引擎足够聪慧,可能防止这个问题。当应用 setInterval()时,仅当没有该定时器的任何其余代码实例时,才将定时器代码增加到队列中。这确保了定时器代码退出队列中最小的工夫距离为指定工夫。这种反复定时器的规定有两个问题:<br />1.某些距离会被跳过 ;<br />2.多个定时器的代码执行工夫可能会比预期小 ; <br />eg: 假如,某个 onclick 事件处理程序应用啦 setInterval()来设置了一个 200ms 的反复定时器。 <br />如果事件处理程序花了 300ms 多一点的工夫实现。 <br />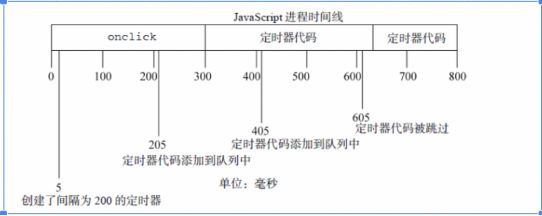<br />注:这个例子中的第 1 个定时器是在 205ms 处增加到队列中的,然而直到过了 300ms 处才可能执行。当执行这个定时器代码时,在 405ms 处又给队列增加了另外一个正本。在下一个距离,即 605ms 处,第一个定时器代码仍在运行,同时在队列中曾经有了一个定时器代码的实例。后果是,在这个工夫点上的定时器代码不会被增加到队列中。后果在 5ms 处增加的定时器代码完结之后,405ms 处增加的定时器代码就立即执行
所以如果用setTimeout代替的话,就能够确保只有一个事件完结了之后,才会触发下一个定时器事件。这确保了定时器代码退出到队列中的最小工夫距离为指定距离。
以下是实现的2种简略形式:
function say(){
//something
setTimeout(say,200);
}
setTimeout(say,200)
// 或者
setTimeout(function(){
//do something
setTimeout(arguments.callee,200);
},200); 5.JS 怎么管制一次加载一张图片,加载完后再加载下一张
(1)办法 1
<script type="text/javascript">
var obj=new Image();
obj.src="http://www.phpernote.com/uploadfiles/editor/201107240502201179.jpg";
obj.onload=function(){
alert('图片的宽度为:'+obj.width+';图片的高度为:'+obj.height);
document.getElementById("mypic").innnerHTML="<img src='"+this.src+"' />";
}
</script>
<div id="mypic">onloading……</div> (2)办法 2
<script type="text/javascript">
var obj=new Image();
obj.src="http://www.phpernote.com/uploadfiles/editor/201107240502201179.jpg";
obj.onreadystatechange=function(){
if(this.readyState=="complete"){
alert('图片的宽度为:'+obj.width+';图片的高度为:'+obj.height);
document.getElementById("mypic").innnerHTML="<img src='"+this.src+"' />";
}
}
</script>
<div id="mypic">onloading……</div> 6.如何实现 sleep 的成果(es5 或者 es6)
(1)while 循环的形式
function sleep(ms){
var start=Date.now(),expire=start+ms;
while(Date.now()<expire);
console.log('1111');
return;
}执行 sleep(1000)之后,休眠了 1000ms 之后输入了 1111。上述循环的形式毛病很显著,容易造成死循环。
(2)通过 promise 来实现
function sleep(ms){
var temple=new Promise(
(resolve)=>{
console.log(111);
setTimeout(resolve,ms);
});
return temple
}
sleep(500).then(
function(){
//console.log(222)
})//先输入了 111,提早 500ms 后输入 222
(3)通过 async 封装
function sleep(ms){
return new Promise((resolve)=>setTimeout(resolve,ms));
}
async function test(){
var temple=await sleep(1000);
console.log(1111)
return temple
}
test(); //提早 1000ms 输入了 1111
(4).通过 generate 来实现
function* sleep(ms){
yield new Promise(function(resolve,reject){
console.log(111);
setTimeout(resolve,ms);
})
}
sleep(500).next().value.then(
function(){
console.log(2222)
}) 7.实现 JS 中所有对象的深度克隆(包装对象,Date 对象,正则对象)
通过递归能够简略实现对象的深度克隆,然而这种办法不论是 ES6 还是 ES5 实现,都有 同样的缺点,就是只能实现特定的 object 的深度复制(比方数组和函数),不能实现包装对象 Number,String ,Boolean,以及 Date 对象,RegExp 对象的复制。
(1)前文的办法
function deepClone(obj){
var newObj= obj instanceof Array?[]:{};
for(var i in obj){
newObj[i] = typeof obj[i] == 'object' ? deepClone(obj[i]):obj[i];
}
return newObj;
}这种办法能够实现个别对象和数组对象的克隆,比方:
var arr=[1,2,3];
var newArr=deepClone(arr);
// newArr->[1,2,3]
var obj={
x:1,
y:2
}
var newObj=deepClone(obj);
// newObj={x:1,y:2} 然而不能实现例如包装对象 Number,String,Boolean,以及正则对象 RegExp 和 Date 对象的
克隆,比方:
//Number 包装对象
var num=new Number(1);
typeof num // "object"
var newNum=deepClone(num);
//newNum -> {} 空对象
//String 包装对象
var str=new String("hello");
typeof str //"object"
var newStr=deepClone(str);
//newStr-> {0:'h',1:'e',2:'l',3:'l',4:'o'};
//Boolean 包装对象
var bol=new Boolean(true);
typeof bol //"object"
var newBol=deepClone(bol);
// newBol ->{} 空对象 (2)valueof()函数
所有对象都有 valueOf 办法,valueOf 办法对于:如果存在任意原始值,它就默认将对象转换为示意它的原始值。对象是复合值,而且大多数对象无奈真正示意为一个原始值,因而默认的 valueOf()办法简略地返回对象自身,而不是返回一个原始值。数组、函数和正则表达式简略地继承了这个默认办法,调用这些类型的实例的 valueOf()办法只是简略返回这个对象自身。
对于原始值或者包装类:
function baseClone(base){
return base.valueOf();
}
//Number
var num=new Number(1);
var newNum=baseClone(num);
//newNum->1
//String
var str=new String('hello');
var newStr=baseClone(str);
// newStr->"hello"
//Boolean
var bol=new Boolean(true);
var newBol=baseClone(bol);
//newBol-> true 其实对于包装类,齐全能够用=号来进行克隆,其实没有深度克隆一说,这里用 valueOf 实现,语法上比拟符合规范。
对于 Date 类型:
因为 valueOf 办法,日期类定义的 valueOf()办法会返回它的一个外部示意:1970 年 1 月 1 日以来的毫秒数.因而咱们能够在 Date 的原型上定义克隆的办法:
Date.prototype.clone=function(){
return new Date(this.valueOf());
}
var date=new Date('2010');
var newDate=date.clone();
// newDate-> Fri Jan 01 2010 08:00:00 GMT+0800 对于正则对象 RegExp:
RegExp.prototype.clone = function() {
var pattern = this.valueOf();
var flags = '';
flags += pattern.global ? 'g' : '';
flags += pattern.ignoreCase ? 'i' : '';
flags += pattern.multiline ? 'm' : '';
return new RegExp(pattern.source, flags);
};
var reg=new RegExp('/111/');
var newReg=reg.clone();
//newReg-> /\/111\// 8.JS 监听对象属性的扭转
咱们假如这里有一个 user 对象,
(1)在 ES5 中能够通过 Object.defineProperty 来实现已有属性的监听
Object.defineProperty(user,'name',{
set:function(key,value){}
})
//毛病:如果 id 不在 user 对象中,则不能监听 id 的变动(2)在 ES6 中能够通过 Proxy 来实现
var user = new Proxy({},{
set:function(target,key,value,receiver){}
})
//这样即便有属性在 user 中不存在,通过 user.id 来定义也同样能够这样监听这个属性的变动 9.Vue3.0 里为什么要用 Proxy API 代替 defineProperty API?
答:响应式优化。
(1)defineProperty API 的局限性最大起因是它只能针对单例属性做监听。
Vue2.x 中的响应式实现正是基于 defineProperty 中的 descriptor,对 data 中的属性做了遍历 + 递归,为每个属性设置了 getter、setter。
这也就是为什么 Vue 只能对 data 中预约义过的属性做出响应的起因,在 Vue 中应用下标的形式间接批改属性的值或者增加一个事后不存在的对象属性是无奈做到 setter 监听的,这是 defineProperty 的局限性。
(2)Proxy API 的监听是针对一个对象的,这就齐全能够代理所有属性。
Proxy API 监听一个对象,那么对这个对象的所有操作会进入监听操作,从而就齐全能够代理所有属性,能够了解成,在指标对象之前架设一层“拦挡”,外界对该对象的拜访,都必须先通过这层拦挡,因而提供了一种机制,能够对外界的拜访进行过滤和改写,这样就带来了很大的性能晋升和更优的代码。
(3)响应式是惰性的
在 Vue.js 2.x 中,对于一个深层属性嵌套的对象,要劫持它外部深层次的变动,就须要递归遍历这个对象,执行 Object.defineProperty 把每一层对象数据都变成响应式的,这无疑会有很大的性能耗费。
在 Vue.js 3.0 中,应用 Proxy API 并不能监听到对象外部深层次的属性变动,因而它的解决形式是在 getter 中去递归响应式,这样的益处是真正拜访到的外部属性才会变成响应式,简略的能够说是按需实现响应式,缩小性能耗费。
10、js 中宏观工作、宏观工作、循环机制的了解
js 属于单线程,分为同步和异步,js代码是自上向下执行的,在主线程中立刻执行的就是同步工作,比方简略的逻辑操作及函数,而异步工作不会立马执行,会挪步放到到异步队列中,比方ajax、promise、事件、计时器等等。
先执行同步,主线程完结后再依照异步的程序再次执行。
事件循环:同步工作进入主线程,立刻执行,执行之后异步工作进入主线程,这样循环。
在事件循环中,每进行一次循环操作称为tick,tick 的工作解决模型是比较复杂的,里边有两个词:别离是 Macro Task (宏工作)和 Micro Task(微工作)
宏观工作和宏观工作(先执行宏观工作,再执行宏观工作)
针对js
宏观工作:setTimeOut、setTimeInterval、postMessage
宏观工作:Promise.then
重点:Promise 同步 Promise.then 异步
console.log("开始111");
setTimeout(function() {
console.log("setTimeout111");
}, 0);
Promise.resolve().then(function() {
console.log("promise111");
}).then(function() {
console.log("promise222");
});
console.log("开始222");咱们依照步骤来剖析下:
1、遇到同步工作,间接先打印 “开始111”。
2、遇到异步 setTimeout ,先放到队列中期待执行。
3、遇到了 Promise ,放到期待队列中。
4、遇到同步工作,间接打印 “开始222”。
5、同步执行完,返回执行队列中的代码,从上往下执行,发现有宏观工作 setTimeout 和宏观工作 Promise ,那么先执行宏观工作,再执行宏观工作。
所以打印的程序为: 开始111 、开始222 、 promise111 、 promise222 、 setTimeout111 。
11. rgb和16进制色彩转换
首先咱们须要晓得RGB与十六进制之间的关系,例如咱们最常见的红色RGB示意为rgb(255, 255, 255), 十六进制示意为#FFFFFFF, 咱们能够把十六进制色彩除‘#’外按两位宰割成一部分,即FF,FF,FF, 看一下十六进制的FF转为十进制是多少呢?没错,就是255!
理解了十六进制和RGB关系之后,咱们就会发现RGB转十六进制办法就很简略了
将RGB的3个数值别离转为十六进制数,而后拼接,即 rgb(255, 255, 255) => ‘#’ + ‘FF’ + ‘FF’ + ‘FF’。
奇妙利用左移,咱们把十六进制数值局部当成一个整数,即FFFFFF,咱们能够了解为FF0000 + FF00 + FF, 如同咱们下面解释,如果左移是基于十六进制计算的,则能够了解为FF << 4, FF << 2, FF, 而实际上咱们转为二进制则变为 FF << 16,如下:
x 16^4 = x 2 ^ 16
理解了原理当前,代码如下:
function RGBFUN(rgb){
// 取出rgb中的数值
let arr = rgb.match(/\d+/g);
console.log(arr,'输入rgb转换数值') //[ '0', '255', '0' ] 输入rgb转换数值
if (!arr || arr.length !== 3) {
console.error('rgb数值不非法');
return
}
let hex = (arr[0]<<16 | arr[1]<<8 | arr[2]).toString(16);
// 主动补全第一位
if (hex.length < 6) {
hex = '0' + hex;
}
console.log(`#${hex}`,'输入转换之后的数值') // #0ff00 输入转换之后的数值
return `#${hex}`;
}
RGBFUN('rgb(0,255,0)')12. JavaScript位操作:两个操作数相应的比特位有且只有一个1时,后果为1,否则为0
能够实现简略的加密
const value = 456;
function encryption(str) {
let s = '';
str.split('').map(item => {
s += handle(item);
})
return s;
}
function decryption(str) {
let s = '';
str.split('').map(item => {
s += handle(item);
})
return s;
}
function handle(str) {
if (/\d/.test(str)) {
return str ^ value;
} else {
let code = str.charCodeAt();
let newCode = code ^ value;
return String.fromCharCode(newCode);
}
}
let init = 'JS 把握 位运算';
let result = encryption(init); // ƂƛǨ扄戩Ǩ亅踘穟 加密之后
console.log(result,'加密之后')
let decodeResult = decryption(result); // JS 把握 位运算 解密之后
console.log(decodeResult,'解密之后')13.【基于webpack】有哪些Loader?用过哪些?
:::tips
文件
- val-loader:将代码作为模块执行,并将其导出为 JS 代码
- ref-loader:用于手动建设文件之间的依赖关系
:::
:::tips
JSON - cson-loader:加载并转换 CSON 文件
:::
:::tips
语法转换 - babel-loader:应用 Babel 加载 ES2015+ 代码并将其转换为 ES5
- esbuild-loader:加载 ES2015+ 代码并应用 esbuild 转译到 ES6+
- buble-loader:应用 Bublé 加载 ES2015+ 代码并将其转换为 ES5
- traceur-loader:应用 Traceur 加载 ES2015+ 代码并将其转换为 ES5
- ts-loader:像加载 JavaScript 一样加载 TypeScript 2.0+
- coffee-loader:像加载 JavaScript 一样加载 CoffeeScript
- fengari-loader:应用 fengari 加载 Lua 代码
- elm-webpack-loader:像加载 JavaScript 一样加载 Elm
:::
:::tips
模板 - html-loader:将 HTML 导出为字符串,须要传入动态资源的援用门路
- pug-loader:加载 Pug 和 Jade 模板并返回一个函数
- markdown-loader:将 Markdown 编译为 HTML
- react-markdown-loader:应用 markdown-parse 解析器将 Markdown 编译为 React 组件
- posthtml-loader:应用 PostHTML 加载并转换 HTML 文件
- handlebars-loader:将 Handlebars 文件编译为 HTML
- markup-inline-loader:将 SVG/MathML 文件内嵌到 HTML 中。在将图标字体或 CSS 动画利用于 SVG 时,此性能十分实用。
- twig-loader:编译 Twig 模板并返回一个函数
- remark-loader:通过 remark 加载 markdown,且反对解析内容中的图片
:::
:::tips
款式 - style-loader:将模块导出的内容作为款式并增加到 DOM 中
- css-loader:加载 CSS 文件并解析 import 的 CSS 文件,最终返回 CSS 代码
- less-loader:加载并编译 LESS 文件
- sass-loader:加载并编译 SASS/SCSS 文件
- postcss-loader:应用 PostCSS 加载并转换 CSS/SSS 文件
- stylus-loader:加载并编译 Stylus 文件
:::
:::tips
框架 - vue-loader:加载并编译 Vue 组件
-
angular2-template-loader:加载并编译 Angular 组件
:::14.谈谈Js如何实现继承?
1.原型链继承:将父类的实例作为子类的原型
:::tips
长处:
1. 简略,易于实现
2. 父类新增原型办法、原型属性,子类都能拜访到
毛病:
1. 无奈实现多继承,因为原型一次只能被一个实例更改
2. 来自原型对象的所有属性被所有实例共享(上诉例子中的color属性)
3. 创立子类实例时,无奈向父构造函数传参
:::
2.构造函数继承:复制父类的实例属性给子类
:::tips
长处:
1. 解决了原型链继承中子类实例共享父类援用属性的问题
2. 创立子类实例时,能够向父类传递参数
3. 能够实现多继承(call多个父类对象)
毛病:
1. 实例并不是父类的实例,只是子类的实例
2. 只能继承父类实例的属性和办法,不能继承其原型上的属性和办法
3. 无奈实现函数复用,每个子类都有父类实例函数的正本,影响性能
:::
3.组合继承(经典继承):将原型链和借用构造函数的技术组合到一块。应用原型链实现对原型属性和办法的继承,而通过构造函数来实现对实例属性的继承
:::tips
长处:
1. 补救了结构继承的毛病,当初既能够继承实例的属性和办法,也能够继承原型的属性和办法
2. 既是子类的实例,也是父类的实例
3. 能够向父类传递参数
4. 函数能够复用
毛病:
1. 调用了两次父类构造函数,生成了两份实例
2. constructor指向问题
:::
4.实例继承:为父类实例增加新特色,作为子类实例返回
:::tips
长处:
1. 不限度调用形式,不论是new 子类()还是子类(),返回的对象具备雷同的成果
毛病:
1. 实例是父类的实例,不是子类的实例
2. 不反对多继承
:::
5.拷贝继承:对父类实例中的的办法与属性拷贝给子类的原型
:::tips
长处:
1. 反对多继承
毛病:
1. 效率低,性能差,占用内存高(因为须要拷贝父类属性)
2. 无奈获取父类不可枚举的办法(不可枚举的办法,不能应用for-in拜访到)
:::
6.寄生组合继承:通过寄生形式,砍掉父类的实例属性,防止了组合继承生成两份实例的毛病
:::tips
长处:
1. 比拟完满(js实现继承首选形式)
毛病:
1.实现起来较为简单(可通过Object.create简化)
:::
7.es6–Class继承:应用extends表明继承自哪个父类,并且在子类构造函数中必须调用super
:::tips
长处:
1.语法简略易懂,操作更不便
毛病:
1.并不是所有的浏览器都反对class关键字 lass Per
:::15.最终后果会输入什么?
var length = 10; function fn(){ console.log(this.length) } var obj = { length: 5, method: function(fn){ fn(); arguments[0]() } } obj.method(fn,1) //10 2:::tips
解析:
1、fn():任意函数里如果嵌套了非箭头函数,那这个时候,嵌套函数里的 this 在未指定的状况下,应该指向的是 window 对象,所以这里执行 fn 会打印 window.length。如果应用 let 申明变量时会造成块级作用于,且不存在变量晋升;而 var 存在申明晋升。所以是输入后果是10;然而如果是let length = 10;那输入后果就是:0 2。
2、arguments[0]():在办法调用(如果某个对象的属性是函数,这个属性就叫办法,调用这个属性,就叫办法调用)中,执行函数体的时候,作为属性拜访主体的对象和数组便是其调用办法内 this 的指向。(艰深的说,调用谁的办法 this 就指向谁)。
这里 arguments[0]() 是作为 arguments 对象的属性 [0] 来调用 fn 的,所以 fn 中的 this 指向属性拜访主体的对象 arguments。
这里还有一点要留神,arguments 这个参数,指的是 function 的所有实参,与形参无关。也就是调用函数时,理论传入的参数,fn 与 1 作为一个参数存储在 arguments 对象里,所以 arguments 的长度为2,所以输入 2。
:::16. 如何实现CLI创立模板我的项目?
:::tips
- 讲述实现的根本步骤:
- 终端参数解析
- CLI交互收集创立我的项目必要参数
- 拷贝模板我的项目
- 重写package.json文件(批改项目名称等)
- 创立实现后提醒或执行我的项目的初始化过程
- 讲述实现过程的注意事项:
- package.json中name的命名标准
- 同名我的项目再次被创立须要思考是否笼罩或中断,笼罩的状况下要思考已创立的我的项目是否接入的版本治理
- 创立实现后提醒或执行我的项目初始化要依据应用时的包管理器来判断
- 内容扩大
- 在CLI交互收集参数能够反对历史我的项目模板或第三方模板,通过对应模板的创立形式来实现兼容
-
CLI创立我的项目通常要先执行装置CLI的命令,再来运行CLI内置的创立我的项目命令两步,能够思考应用命名规约来实现间接执行npm create xxx、yarn create xxx 启动CLI创立我的项目
:::17. 如何实现自动化埋点?
自动化埋点能够利用 Babel + 定制埋点插件在我的项目编译过程中对函数插桩实现埋点自动化,应用Babel自动化插桩须要关注两点:
-
埋点模块判断是否曾经导入和如何导入:
- 在 Babel 插件执行中通过遍历代码中的
ImportDeclaration来剖析是否蕴含了指定的埋点模块; - 通过Babel内置
@babel/helper-module-imports模块来实现埋点模块导入;
- 在 Babel 插件执行中通过遍历代码中的
-
埋点函数如何生成并插入到源函数;
- 如何生成:通过内置API
template.statement来生成调用埋点函数的AST; -
如何插入:函数的不同模式对应的AST中类型包含了
ClassMethod、ArrowFunctionExpression、FunctionExpression、FunctionDeclaration,在 Babel 遍历它们的时候在对应的节点的body中插入生成的AST,当遇到没有函数体的函数须要减少函数体并解决返回值;18. 讲述一下JSON Web Token?
- 如何生成:通过内置API
-
工作原理:
JWT在服务器认证后生成蕴含用户信息,工夫工夫,平安信息等内容组成的JSON对象来惟一示意以后用户状态,在其后的数据交互中继续携带来表明申请的有效性。
2. 数据结构:
JWT是有header,payload和signature三局部通过“.”连接起来的字符串,在JWT字符串中没有换行。- header是一个JSON对象,用来形容一些元数据;
- payload的格局要求同header,内容次要官网定义字段+自定义的字段来满足业务场景的须要;
-
“Header”和“Payload”都没有提到加密一说,只是进行的字符的编码,所以在“Header”和“Payload”中咱们不应该搁置一些用户相干的波及平安的信息,未避免上述两块的内容被中间商拦挡篡改,所以须要用到“Signature”;
signature = HMACSHA256( base64UrlEncode(header) + "." + base64UrlEncode(payload), secret )
- 应用形式:
规范的应用形式为在HTTP的头部减少key为“Authorization”,value为:“ Bearer <token>”的一组信息,token的具体存储按理论业务解决。
4. 注意事项: - JWT默认不加密,但能够自行加密解决。
- 采纳默认不加密的状况,请勿将涉密数据放入JWT中。
-
倡议采纳HTTPS来避免中间人攻打。
19. JavaScript中toString()和join()的区别?
// 申明两个不同的数组 const fruitList = ['苹果', '香蕉', '百香果'] const objList = [ { name: '张三', age: 16 }, { name: '李斯', age: 18 } ] // 通过toString()间接进行转换为字符串 console.log(fruitList.toString()) // '苹果,香蕉,百香果' console.log(objList.toString()) // '[object Object],[object Object]' // 通过join()自定义拼接进行转换为字符串 console.log(fruitList.join()) // '苹果,香蕉,百香果' console.log(fruitList.join(',')) // '苹果,香蕉,百香果' console.log(fruitList.join('、')) // '苹果、香蕉、百香果' console.log(fruitList.join('宰割')) // '苹果宰割香蕉宰割百香果' console.log(objList.join()) // '[object Object],[object Object]':::tips
总结论断:
toString()与join()是将数组中的所有元素放入一个字符串。
当join()函数外部参数为空时,join()等价于toString()。
当join(‘,’)函数外部参数为逗号字符,则示意用逗号宰割数组,等价于外部参数为空。
当join(‘、’)函数外部参数为顿号字符,则示意用顿号宰割数组。
当join(‘宰割’)函数外部参数为字符串时,则示意用‘宰割’字符串宰割数组。
:::20. null / undefined 的区别
:::tips
null值:属于null类型,代表“空值”,代表一个空对象指针;应用typeof运算失去 “object”,所以你能够认为它是一个非凡的对象值。
undefined值:属于undefined类型,当一个申明的变量未初始化赋值时,失去的就是undefined。应用typeof运算失去“undefined”。
:::21. 循环遍历map()与forEach()的区别?
array.map(function(currentValue, index, arr), thisValue)const nums = [4, 9, 16, 25] const emptyList = [] const doubleNums = nums.map(Math.sqrt) console.log(doubleNums) // [2, 3, 4, 5] console.log(nums) // [4, 9, 16, 25] console.log(emptyList.map(Math.sqrt)) // []:::tips
定义和用法:
map()办法返回一个新数组,数组中的元素为原始数组元素调用函数解决后的值。
map()办法依照原始数组元素程序顺次解决元素。
map()不会对空数组进行检测。
map()不会扭转原始数组。
:::array.forEach(function(currentValue, index, arr), thisValue)const nums = [4, 9, 16, 25] const emptyList = [] const doubleNums = nums.forEach(Math.sqrt) console.log(doubleNums) // undefined console.log(emptyList.forEach(Math.sqrt)) // undefined定义和用法:
forEach()办法用于调用数组的每个元素,并将元素传递给回调函数。
forEach()对于空数组是不会执行回调函数的。
区别:
forEach()办法不会返回执行后果,而是undefined。也就是说,forEach()会批改原来的数组。而map()办法会失去一个新的数组并返回。
map()会分配内存空间存储新数组并返回,forEach()不会返回数据。
forEach()容许callback更改原始数组的元素。map()返回新的数组。22. for/in 与 for/of有什么区别?
Array.prototype.method = function () {} let myArray = [1, 2, 3] myArray.name = '数组'; for (let index in myArray) { console.log(index) // 0,1,2, name, method console.log(myArray[index]) //1,2,3,数组,f() {} } for (let val of myArray) { console.log(val) // 1,2,3 }最间接的区别就是: for/in遍历的是数组的索引,而for/of遍历的是数组元素值。
for/in遍历的缺点: - 索引是字符串类型的数字,所以不能间接进行几何运算
- 遍历程序可能不是理论的外部程序
- for/in会遍历数组所有的可枚举属性,包含原型。
所以个别用来遍历对象,而不是数组。
for/of遍历的缺点:
for/of不反对一般对象,想遍历对象的属性,能够用for/in循环,或者内建的Object.keys()办法:
Object.keys(obj)获取对象的实例属性组成的数组,不包含原型办法和属性
for(let key of Object.keys(obj)) {
console.log(key + ":" + Object[key])
}for/of语句创立一个循环来迭代可迭代的对象,容许遍历Arrays,Strings,Map, Set等可迭代的数据结构
// variable 每个迭代的属性值被调配给该变量。
// iterable 一个具备可枚举属性并且能够迭代的对象。
for(let variable of iterable) {
statement
}总体来说:for/in遍历对象;for/of遍历数组
23.css 的渲染层合成是什么,浏览器如何创立新的渲染层
:::tips
在 DOM 树中每个节点都会对应一个渲染对象(RenderObject),当它们的渲染对象处于雷同的坐标空间(z 轴空间)时,就会造成一个 RenderLayers,也就是渲染层。渲染层将保障页面元素以正确的程序重叠,这时候就会呈现层合成(composite),从而正确处理通明元素和重叠元素的显示。对于有地位重叠的元素的页面,这个过程尤其重要,因为一旦图层的合并程序出错,将会导致元素显示异样。
浏览器如何创立新的渲染层
- 根元素 document
- 有明确的定位属性(relative、fixed、sticky、absolute)
- opacity < 1
- 有 CSS fliter 属性
- 有 CSS mask 属性
- 有 CSS mix-blend-mode 属性且值不为 normal
- 有 CSS transform 属性且值不为 none
- backface-visibility 属性为 hidden
- 有 CSS reflection 属性
- 有 CSS column-count 属性且值不为 auto 或者有 CSS column-width 属性且值不为 auto
- 以后有对于 opacity、transform、fliter、backdrop-filter 利用动画
-
overflow 不为 visible
:::24.路由原理 history 和 hash 两种路由形式的特点
:::tips
hash 模式
- location.hash 的值理论就是 URL 中#前面的货色 它的特点在于:hash 尽管呈现 URL 中,但不会被蕴含在 HTTP 申请中,对后端齐全没有影响,因而扭转 hash 不会从新加载页面。
- 能够为 hash 的扭转增加监听事件
window.addEventListener(“hashchange”, funcRef, false);
每一次扭转 hash(window.location.hash),都会在浏览器的拜访历史中减少一个记录利用 hash 的以上特点,就能够来实现前端路由“更新视图但不从新申请页面”的性能了
特点:兼容性好然而不美观
history 模式
利用了 HTML5 History Interface 中新增的 pushState() 和 replaceState() 办法。
这两个办法利用于浏览器的历史记录站,在以后已有的 back、forward、go 的根底之上,它们提供了对历史记录进行批改的性能。这两个办法有个独特的特点:当调用他们批改浏览器历史记录栈后,尽管以后 URL 扭转了,但浏览器不会刷新页面,这就为单页利用前端路由“更新视图但不从新申请页面”提供了根底。
特点:尽管好看,然而刷新会呈现 404 须要后端进行配置
:::
25.XMLHttpRequest与fetch的区别?
:::tips
(1).XMLHttpRequest 对象在所有古代的浏览器都反对,Fetch 是一种新的原生 JavaScript API,目前大多数浏览器都反对
(2).XMLHttpRequest基于onreadystatechange执行回调,Fetch API 应用 Promise,防止了回调。
(3).Fetch只对网络申请报错,对400,500都当做胜利的申请,须要封装去解决。
(4).Fetch 申请默认是不带 cookie 的,须要设置 fetch(url, {credentials: ‘include’})。
(5).Fetch不反对abort,因为Fetch返回的是一个promise,不反对超时管制,应用setTimeout及Promise.reject的实现的超时管制并不能阻止申请过程持续在后盾运行,造成了量的节约。
(6).fetch() 示例中,能够传递字符串定义 的URL 端点,也能够传递一个可配置的 Request 对象。
(7).在 XMLHttpRequest 中治理缓存很麻烦,Fetch 对象中内置了对缓存的反对:
(8).跨域申请中,Fetch 提供了一个模式属性,能够在参数中设置‘no-cors’属性。
(9).默认状况下,fetch() 和 XMLHttpRequest 都遵循服务器重定向。然而,fetch() 在参数中提供了可选项:
redirect
‘follow’ —— 遵循所有重定向(默认)
‘error’ —— 产生重定向时停止(回绝)
‘manual’ —— 返回手动解决的响应
(10).XMLHttpRequest 将整个响应读入内存缓冲区,然而 fetch() 能够流式传输申请和响应数据,这是一项新技术,流容许你在发送或接管时解决更小的数据块。
(11).Deno 和 Node 中齐全反对 Fetch,XMLHttpRequest 只在客户端被反对。
:::
26.前端如何实现大文件下载?
:::tips
(1).后端服务反对的状况下能够应用分块下载。
(2).云上文件能够采纳a标签形式,通过浏览器默认机制实现下载
(3).借助StreamAPI与Service Worker实现
:::
27.常见几种前端微服务及实现原理
:::tips
微前端架构将后端微服务的理念利用于浏览器端,行将 Web 利用由繁多的单体利用转变为多个小型前端利用聚合为一的利用。
微前端架构个别能够由以下几种形式进行:
- 路由散发
通过路由将不同的业务散发到不同的、独立前端利用上。其通常能够通过 HTTP 服务器的反向代理来实现,又或者是利用框架自带的路由来解决。
- 通过iframe容器
应用iframe创立一个全新的独立的宿主环境,运行各自独立的前端利用
- 前端微服务化
在页面适合的中央引入或者创立 DOM,用户拜访到对应URL时,加载对应的利用,并能卸载利用
- 利用微件化
也叫组合式集成,即通过软件工程的形式在构建前、构建时、构建后等步骤中,对利用进行一步的拆分,并重新组合
- 基于Web Components
应用 Web Components 技术构建独立于框架的组件,随后在对应的框架中引入这些组件
:::
28.前端部署都有哪些计划?
:::tips
前端部署的形式大抵有三种,
- 应用Nginx,Tomcat,IIS等web服务器部署
- Dokcer部署
-
OSS+CDN 部署,或COS
:::29.常见公布计划有几种
:::tips
- 蓝绿公布
蓝绿公布是指公布过程中新利用公布测试通过后,通过切换网关流量, 一键降级利用的公布形式
- 滚动公布
个别是进行一个或多个服务,执行更新,并从新将其投入使用,周而复始,直到微服务中所有的因公都更新成新版本。
- 灰度公布
是指在黑与白之间,可能平滑过渡的一种公布形式。AB test就是一种灰度公布形式,让一部分用户持续用A,一部分用户开始用B,如果用户对B没有什么拥护意见,那么逐渐扩大范围,把所有用户都迁徙到B下面来。灰度公布能够保障整体零碎的稳固,在初始灰度的时候就能够发现、调整问题,以保障其影响度,而咱们平时所说的金丝雀部署也就是灰度公布的一种形式。
:::
30.如何设计一套A/B计划
:::tips
A/B公布是一种比拟高级的流量调配计划,例如依据 URL 是否匹配申请不同的版本利用,或者依据 Header 下某个自定义参数进行用户的辨别,从而申请不同的版本利用
波及流量管理策略,Istio ,docker,k8s等技术
以后微服务、云原生的理念逐步深刻,现有前端的开发方式和前端架构也将跟随着一直变动,利用好以上技术可能实现更迅速地扩大,更稳固地交付,利用之间的分割也会更加严密,将来几年的前端也必将是微服务化的时代。
:::
结语:
看到这里不晓得你有没有失去播种呢?如果你还有更多的抗冻指南欢送你留到评论区,留给须要的敌人,如果下面的内容你还要问题也请留言交换,愿每一次的互联网寒冬都达不到任何一个有筹备的JY~
发表回复