三高Mysql – Mysql个性和将来倒退
引言
内容为慕课网的《高并发 高性能 高可用 Mysql 实战》视频的学习笔记内容和集体整顿扩大之后的笔记,这一节次要讲讲Mysql5.8比拟罕用的几个新个性以及针对外部服务器的优化介绍,实践局部的内容比拟多简略看看了解一下即可。
如果内容比拟难能够追随《Mysql是怎么样运行》集体读书笔记专栏补补课:
地址如下:从零开始学Mysql。
Mysql8.0新个性
Mysql为什么叫8.0?其实就是个数字游戏能够间接认为是5.8。
Mysql8.0有什么新个性:
窗口函数:rank()
- 列分隔,分为多个窗口
- 在窗口外面能够执行特定的函数
-- partition by 排名,案例指的是依照顾客领取金额排名。
-- rank() 窗口函数
select *,
rank() over ( partition by customer_id order by amount desc) as ranking
from
payment;
暗藏索引
- 临时暗藏某个索引。
- 能够暗藏和显示索引,测试索引作用,多用于开发的时候评估索引的可用性。
show index from payment;
-- 暗藏索引
alter table payment alter index fk_payment_rental Invisible;
-- 显示索引
alter table payment alter index fk_payment_rental Visible;降序索引
- 8.0 之前只有升序的索引,自8.0之后引入了降序索引的索引排序形式,用于进行某些非凡查问的状况下也能够走索引。
通用表达式(CTE)
- CTE表达式事后定义简单语句中重复应用的两头后果
- 能够简略认为是一个长期视图
select b,d
from (select a,b from table1) join (select a,b from table2)
where cte1.a = cte2.c;
-- 简化
with
cte1 as (select a,b from table1),
cte1 as (select a,b from table2)
select b,d
from cte1 join cte2
where cte.a = cte2.c;
UTF8编码
- UTF8mb4作为默认的字符集
-
DDL 事务
- 反对DDL事务,元数据操作能够回滚
-
对于不同数据库之间的DDL比照,能够看这篇文章:
https://juejin.cn/post/698654…
InnoDB Cluster:组复制不是说Mysql能够组集群了而是说保障强一致性的数据同步,上面是对于一些外围组件的解释:
- Mysql Router:路由
- 治理端绕过路由进行配置,能够实现主备的自在切换。
另外从下面这个图还能够看到在新的概念图外面个别不会把节点叫master/slave了,额,zzzq就完事了。
Mysql官网的组复制其实是借用了Percona XtraDB Cluster的设计思路,只不过加了一些辅助工具看起来比拟强一点而已,强一致性的组复制早就被实现过了,比方Percona XtraDB Cluster,设计思路也是来自于Zookeeper的一致性协定,能够认为是原理大同小异。
最初强一致性的最大问题那就是期待同步的工夫是否能够被零碎承受,所以看似组复制在尝试解决复制带来的数据同步问题实际上这种代价看上去还是比拟大的。
数据库的分类
对于数据库咱们能够做出上面的总结,市面上支流的数据库根本都能够依照上面的几种形式进行归类:用处归类,存储模式归类和架构分类。
用处分类:
- OLTP:在线事务处理
- OLAP:在线剖析解决
- HTAP:事务和剖析混合解决
OLTP:在线事务交易和解决零碎,SQL语句不简单大都用于事务的解决。并发量打,可用性的要求非常高。(Mysql / Postgres)
OLAP:在线剖析解决零碎,SQL语句简单,并且数据量非常大,单个事务为单位。(Hive)
HTAP:混合两种数据库长处,一种架构多功能。(设计思路优良,然而理论产出很可能相似新能源汽车,烧油不行烧点也不行)
存储模式分类
- 行存储:传统数据库的存储模式
- 列存储:针对传统OLTP数据库大数据量剖析而逐步呈现的一种格局,行格局利于数据存储和数据分析。
- K/V存储:无论是行还是列存储,仿佛都逃不过KV的概念,这一点读者能够自行思考了解。
架构分类
-
Share-Everything
- CPU、内存、硬盘,多合一,相似电脑(数据库不必)
-
Share-Memory
- 多CPU独立,内存,硬盘,超级计算机架构(多CPU同内存通信,同一片大内存超级计算机)
-
SHare-Disk
- 一个CPU绑定一个内存,硬盘独立,共享存储的架构。
-
Shared-Nothing
- CPU、内存、硬盘共享,常见集群的架构。
单体数据库之王
PostgresSQL说实话国内用的人太少了国内市场没有抉择并且被忽视的优良数据库,然而在国外Postgre SQL随着开源的一直倒退以及比Mysql更优良的设计市场占有率在逐年回升,同时Postgresql对于数据库设计者来说也是很好的范本,无论是学习还是钻研都是非常好的参考资料,最初Postgresql是开源的社区在国外也比拟沉闷,这一点很重要,惋惜国内只能老老实实钻研Mysql了。
Mysql随着Oracle的商业化逐步自闭式倒退提高也越来越小切实看不到他的将来。
Postgresql和Mysql相似的中央以及更加提高的中央:
- Mysql相似性能
- 性能更好,更稳固
- 代码品质更高
- 有赶超Mysql的劣势
-
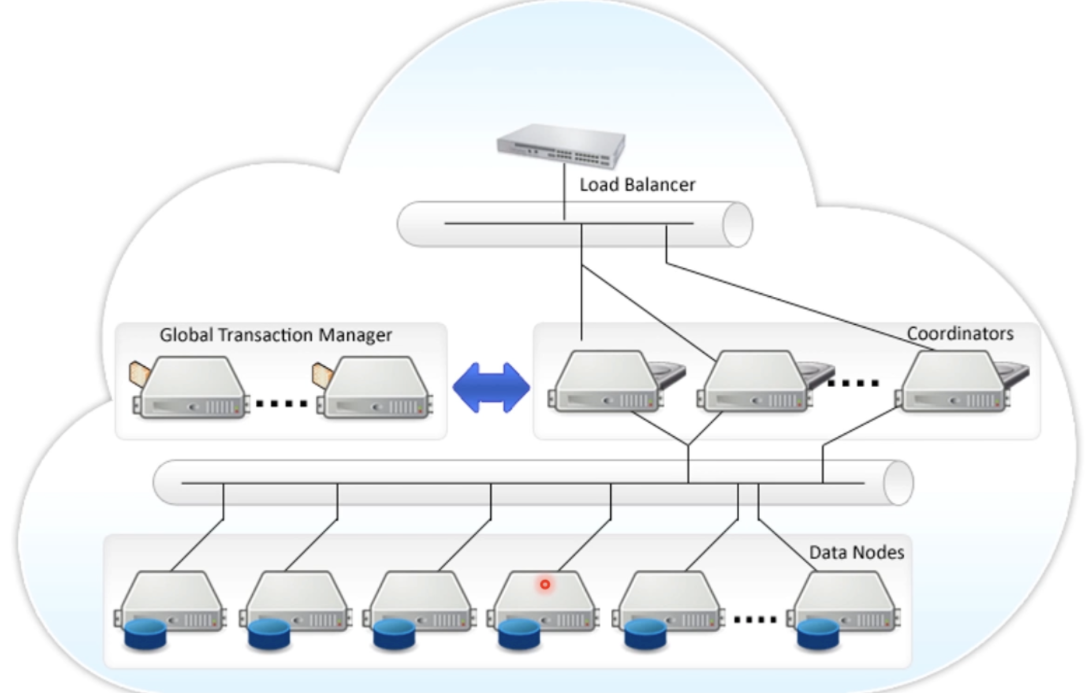
良好的插件,蕴含并不齐全列举比方上面的这些插件:
- Postgres-XL(OLTP)
- GTM治理每个事务的执行
- Coordinator解析SQL,制订执行打算,散发
- DataNode返回执行后果到Coordinator。
-
GreenPlum 是给予Postgres分布式剖析集群
- 高性能SQL优化器:GPORCA
- Slice的实现机制
Mysql如何魔改
首先看看PolarDB的改良,PolarDB是阿里巴巴的货色所以除了内部人员可能应用之外内部的技术人员根本接触不到这个货色,这里简略介绍相干的设计思路。
上面为相干的设计图:
在PorlarDB中蕴含上面的要害组件:
- ECS:客户端
- Read/Write Splitter 读写拆散中间件
- Mysql节点,文件系统, 数据路由和数据缓冲。主备服务器
- RMDA对立的治理
-
Data Chunk Server:数据的存储桶,存储服务器,集群的形式存储
- Raft:强一致性的存储服务器。
- 日志传送和共享存储
7. 备库如何查问数据
在传统的形式中,备库应用上面的形式进行解决
翻新和改良点:在读取事务改变的时候,应用了叠加redo log的形式解决,避免读写库的数据不统一的问题
如何撑持双十一?
双十一刚刚呈现的时候是一个非常炽热的话题,然而到了当初电商成熟的年代双十一仿佛变成了“日常流动”……,双十一的撑持依附非常外围的两头组件:OceanBase,也被称之为new sql数据库。
OceanBase属于行列互存的架构最大的特点是机房跨寰球。存储引擎的最上层是分片的分区层,Share-Nothing架构,数据分区应用的一主两备的构造。
数据如何更新?
数据更新依附上面的流程,看起来比拟负责,其实这里的设计思路有点相似谷歌在2006年的“Bigtable”设计,而SSTable于这篇论文中首次呈现,SSTable次要用于给予LSM-Tree数据结构的日志存储引擎。
如果不分明什么是LSM-Tree,能够浏览上面的文章理解:
《数据密集型型零碎设计》LSM-Tree VS BTree – 掘金 (juejin.cn)
国产混合数据库-TiDB
TiDB简介:
上面的内容援用自官网介绍:
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时反对在线事务处理与在线剖析解决 (Hybrid Transactional and Analytical Processing, HTAP) 的交融型分布式数据库产品,具备程度扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协定和 MySQL 生态等重要个性。指标是为用户提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案。TiDB 适宜高可用、强统一要求较高、数据规模较大等各种利用场景。
简略来说Tidb次要有上面的几个特点:
- 一键程度扩容或者缩容
- 金融级高可用
- 实时HTAP
HTAP数据库(Hybrid Transaction and Analytical Process,混合事务和剖析解决)。2014年Gartner的一份报告中应用混合事务剖析解决(HTAP)一词形容新型的应用程序框架,以突破OLTP和OLAP之间的隔膜,既能够利用于事务型数据库场景,亦能够利用于剖析型数据库场景。实现实时业务决策。这种架构具备不言而喻的劣势:岂但防止了繁琐且低廉的ETL操作,而且能够更快地对最新数据进行剖析。这种疾速剖析数据的能力将成为将来企业的外围竞争力之一。
- 云原生的分布式数据库
- 兼容Mysql5.7 协定和Mysql生态。
尽管TiDB被应用之后有许多令人诟病的毛病,同时因为是新型的数据库对于一些实际问题的解答材料也比拟少,然而作为一款十分有后劲的数据库还是值得咱们放弃关注的。
TiDB的架构设计如下:
- 纯分布式架构,领有良好的扩展性,反对弹性的扩缩容
- 反对 SQL,对外裸露 Mysql 的网络协议,并兼容大多数 Mysql 的语法,在大多数场景下能够间接替换 Mysql
- 默认反对高可用,在多数正本生效的状况下,数据库自身可能主动进行数据修复和故障转移,对业务通明
- 反对 ACID 事务,对于一些有强统一需要的场景敌对,例如:银行转账
- 具备丰盛的工具链生态,笼罩数据迁徙、同步、备份等多种场景
CockroachDB
小强数据库,2015启动,谷歌前员工发动。
CockroachDB,指标是打造一个开源、可伸缩、跨地区复制且兼容事务的 ACID 个性的分布式数据库,它不仅能实现全局(多数据中心)的一致性,而且保障了数据库极强的生存能力,就像 Cockroach(蟑螂)这个名字一样,是打不死的小强。
CockroachDB 的思路源自 Google 的全球性分布式数据库 Spanner。其理念是将数据分布在多数据中心的多台服务器上,实现一个可扩大,多版本,寰球分布式并反对同步复制的数据库。
小结
本节内容次要针对Mysql的一些新个性以及其余第三方如何对于数据库进行扩大的,同时介绍了数据库的分类,咱们能够发现数据库的分类最初都能够依照某种特定的类型进行划分。
写在最初
本节内容非常简单,读者能够依据相干的内容进行深刻学习即可。
发表回复