咱们晓得 Flink 有Table(表)、View(视图)、Function(函数/算子)、Database(数据库)的概念,绝对于这些耳熟能详的概念,Flink 里还有一个 Catalog(目录) 的概念。
本文将为大家带来 Flink Catalog 的介绍以及 Flink Catalog 在 ChunJun 中的实际之路。
Flink Catalog 简介
Catalog 提供元数据,如数据库、表、分区、视图,以及拜访存储在数据库或其余内部零碎中的数据所需的函数和信息。
Flink Catalog 作用
数据处理中最要害的一个方面是治理元数据:
· 可能是暂时性的元数据,如长期表,或针对表环境注册的 UDFs;
· 或者是永久性的元数据,比方 Hive 元存储中的元数据。
Catalog 提供了一个对立的 API 来治理元数据,并使其能够从表 API 和 SQL 查问语句中来拜访。
Catalog 使用户可能援用他们数据系统中的现有元数据,并主动将它们映射到 Flink 的相应元数据。例如,Flink 能够将 JDBC 表主动映射到 Flink 表,用户不用在 Flink 中手动重写 DDL。Catalog 大大简化了用户现有零碎开始应用 Flink 所需的步骤,并加强了用户体验。
Flink Catalog 的构造
● Flink Catalog 原生构造
• GenericInMemoryCatalog:基于内存实现的 Catalog
• Jdbc Catalog:能够将 Flink 通过 JDBC 协定连贯到关系数据库,目前 Flink 在1.12和1.13中有不同的实现,包含 MySql Catalog 和 Postgres Catalog
• Hive Catalog:作为原生 Flink 元数据的长久化存储,以及作为读写现有 Hive 元数据的接口
● Flink Iceberg Catalog
● Flink Hudi Catalog
HoodieCatalog、HoodieHiveCatalog
Flink Catalog 详解
GenericInMemoryCatalog
final CatalogManager catalogManager =
CatalogManager.newBuilder()
.classLoader(userClassLoader)
.config(tableConfig)
.defaultCatalog(
settings.getBuiltInCatalogName(),
new GenericInMemoryCatalog(
settings.getBuiltInCatalogName(),
settings.getBuiltInDatabaseName()))
.build();
defaultCatalog =
new GenericInMemoryCatalog(
defaultCatalogName, settings.getBuiltInDatabaseName());
CatalogManager catalogManager =
builder.defaultCatalog(defaultCatalogName, defaultCatalog).build();GenericInMemoryCatalog 所有的数据都保留在 HashMap 外面,无奈长久化。
JDBC Catalog
CREATE CATALOG my_catalog WITH(
'type' = 'jdbc',
'default-database' = '...',
'username' = '...',
'password' = '...',
'base-url' = '...'
);
`
USE CATALOG my_catalog;如果创立并应用 Postgres Catalog 或 MySQL Catalog,请配置 JDBC 连接器和相应的驱动。
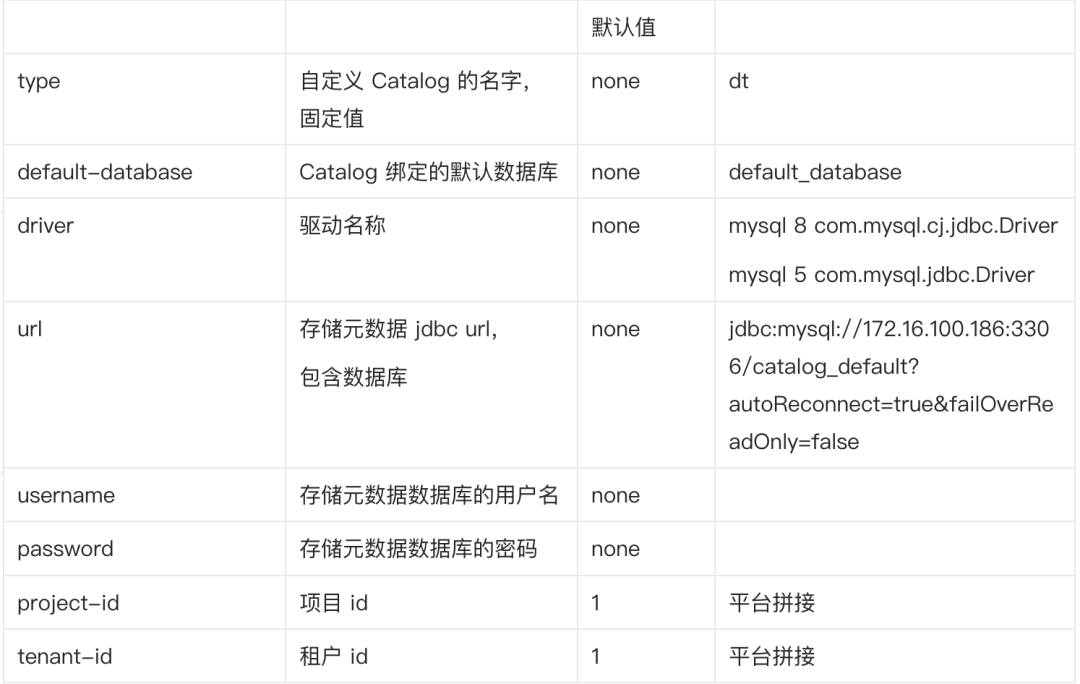
JDBC Catalog 反对以下参数:
• name:必填,Catalog 的名称
• default-database:必填,默认要连贯的数据库
• username:必填,Postgres/MySQL 账户的用户名
• password:必填,账户的明码
• base-url: 必填,(不应该蕴含数据库名)
对于 Postgres Catalog base-url 应为 "jdbc:postgresql://:" 的格局
对于 MySQL Catalog base-url 应为 "jdbc:mysql://:" 的格局
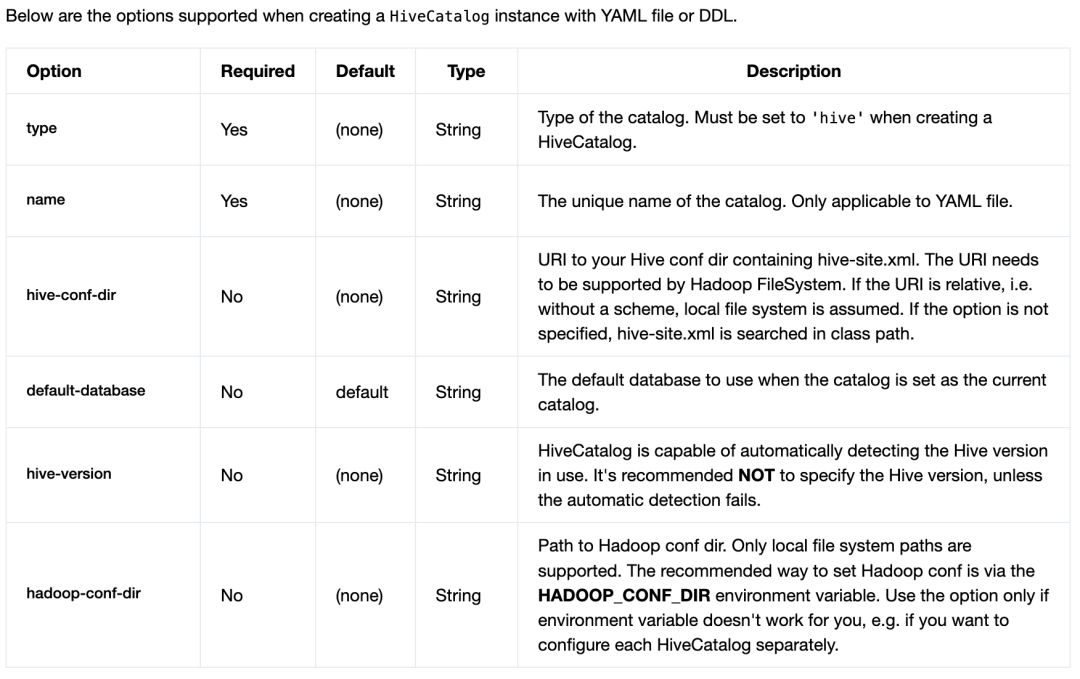
Hive Catalog
CREATE CATALOG myhive WITH (
'type' = 'hive',
'default-database' = 'mydatabase',
'hive-conf-dir' = '/opt/hive-conf'
);
-- set the HiveCatalog as the current catalog of the session
USE CATALOG myhive;
Iceberg Catalog
● Hive Catalog 治理 Iceberg 表
(Flink) default_database.flink_table ->
(Iceberg) default_database.flink_table
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
'connector'='iceberg',
'catalog-name'='hive_prod',
'uri'='thrift://localhost:9083',
'warehouse'='hdfs://nn:8020/path/to/warehouse'
);
(Flink)default_database.flink_table ->
(Iceberg) hive_db.hive_iceberg_table
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
'connector'='iceberg',
'catalog-name'='hive_prod',
'catalog-database'='hive_db',
'catalog-table'='hive_iceberg_table',
'uri'='thrift://localhost:9083',
'warehouse'='hdfs://nn:8020/path/to/warehouse'
);● Hadoop Catalog 治理 Iceberg 表
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
'connector'='iceberg',
'catalog-name'='hadoop_prod',
'catalog-type'='hadoop',
'warehouse'='hdfs://nn:8020/path/to/warehouse'
);● 自定义 Catalog 治理 Iceberg 表
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
'connector'='iceberg',
'catalog-name'='custom_prod',
'catalog-impl'='com.my.custom.CatalogImpl',
-- More table properties for the customized catalog
'my-additional-catalog-config'='my-value',
...
);• connector:iceberg
• catalog-name:用户指定的目录名称,这是必须的,因为连接器没有任何默认值
• catalog-type:内置目录的 hive 或 hadoop(默认为hive),或者对于应用 catalog-impl 的自定义目录实现,不做设置
• catalog-impl:自定义目录实现的全限定类名,如果 catalog-type 没有被设置,则必须被设置,更多细节请参见自定义目录
• catalog-database: 后盾目录中的 iceberg 数据库名称,默认应用以后的 Flink 数据库名称
• catalog-table: 后盾目录中的冰山表名,默认应用 Flink CREATE TABLE 句子中的表名
Hudi Catalog
create catalog hudi with(
'type' = 'hudi',
'mode' = 'hms',
'hive.conf.dir'='/etc/hive/conf'
);
--- 创立数据库供hudi应用
create database hudi.hudidb;
--- order表
CREATE TABLE hudi.hudidb.orders_hudi(
uuid INT,
ts INT,
num INT,
PRIMARY KEY(uuid) NOT ENFORCED
) WITH (
'connector' = 'hudi',
'table.type' = 'MERGE_ON_READ'
);
select * from hudi.hudidb.orders_hudi;
Flink Catalog 在 ChunJun 中的实际
上面将为大家介绍本文的重头戏,Flink Catalog 在 ChunJun 中的实际之路。
间接引入开源 Catalog
ChunJun 目前的所有 Catalog 为以下四种:
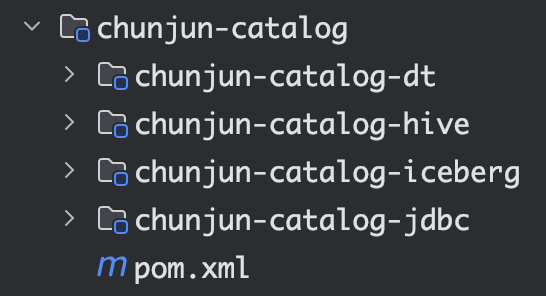
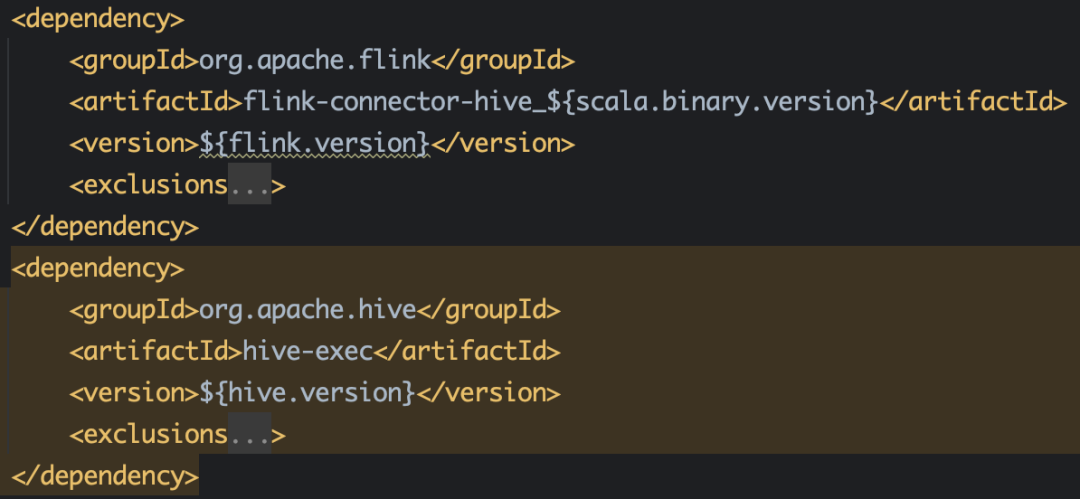
● Hive Catalog 须要的依赖
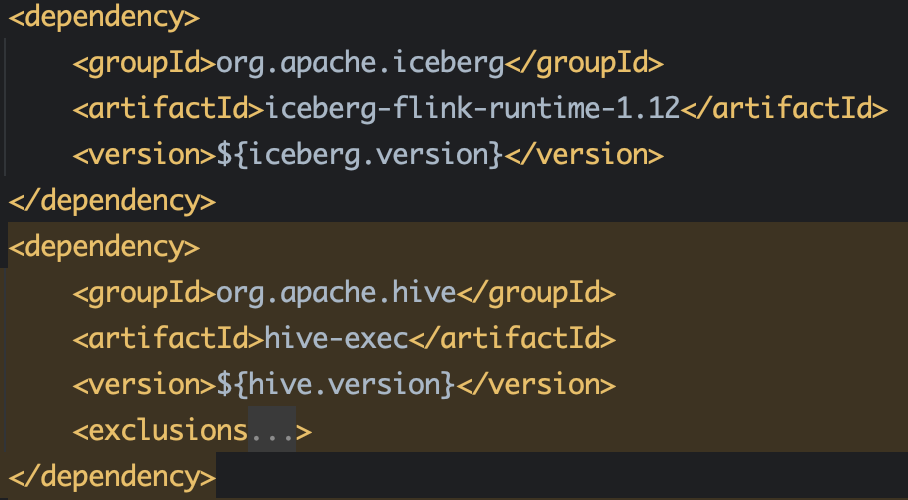
● Iceberg Catalog 须要的依赖
● JDBC Catalog
JDBC 因为 Flink 1.12 和 1.13 API 有变动,因而须要波及源码的改变,改变一些 API 后,从源码引入。
● DT Catalog
联合外部业务,自定义的一种 Catalog ,下文将会进行具体介绍。
DT Catalog -存储元数据表设计
● 创立 mysql 元数据表 database_info
-- 创立表的 sql
create table database_info
(
`id` bigint PRIMARY KEY NOT NULL AUTO_INCREMENT COMMENT '我的项目ID',-- database id
`catalog_name` varchar(255) COMMENT 'catalog 名字',
`database_name` varchar(255) COMMENT 'database 名字',
`catalog_type` varchar(30) COMMENT 'catalog 类型, eg: mysql,oracle...',
`project_id` int(11) NOT NULL COMMENT '我的项目ID',
`tenant_id` int(11) NOT NULL COMMENT '租户ID'
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;
-- 创立索引
CREATE INDEX idx_catalog_name_database_name_project_id_tenant_id ON database_info (`catalog_name`, `database_name`, `project_id`, `tenant_id`);● 创立 mysql 元数据表 table_info
-- 创立表的 sql
create table table_info
(
`id` bigint PRIMARY KEY NOT NULL AUTO_INCREMENT,
`database_id` bigint COMMENT 'database_info 表的 id',
`table_name` varchar(255) COMMENT '表名',
`project_id` int(11) NOT NULL COMMENT '我的项目ID',
`tenant_id` int(11) NOT NULL COMMENT '租户ID'
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;
-- 创立索引
CREATE INDEX idx_catalog_id_project_id_tenant_id ON table_info (`database_id`, `project_id`, `tenant_id`);
CREATE INDEX idx_database_id_table_name_project_id_tenant_id ON table_info (`database_id`, `table_name`, `project_id`, `tenant_id`);● 创立 mysql 元数据表 properties_info
create table properties_info
(
`id` bigint PRIMARY KEY NOT NULL AUTO_INCREMENT ,
`table_id` bigint(20) COMMENT 'table_info 表的 id',
`key` varchar(255) COMMENT '表的属性 key',
`value` varchar(255) COMMENT '表的属性 value'
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;
CREATE INDEX idx_table_id ON properties_info (table_id);● properties_info 外面存了什么?
schema.0.name=id,
schema.0.data-type=INT NOT NULL,
schema.1.name=name,
schema.1.data-type=VARCHAR(2147483647)
schema.2.name=age,
schema.2.data-type=BIGINT,
schema.primary-key.name=PK_3386,
schema.primary-key.columns=id,
connector=jdbc,
url=jdbc:mysql: //172.16.83.218:3306/wujuan?useSSL=false,
username=drpeco,
password=DT@Stack#123,
comment=,
scan.auto-commit=true,
lookup.cache.max-rows=20000,
scan.fetch-size=10,
lookup.cache.ttl=700000
table-name=t2,应用 DT Catalog
● 创立 DT Catalog
CREATE CATALOG catalog1
WITH (
'type' = 'dt',
'default-database' = 'default_database',
'driver' = 'com.mysql.cj.jdbc.Driver',
'url' = 'jdbc:mysql://xxx:3306/catalog_default',
'username' = 'drpeco',
'password' = 'DT@Stack#123',
'project-id' = '1',
'tenant-id' = '1'
);
● 创立 Database
DROP DATABASE [IF EXISTS] [catalog_name.]db_name [ (RESTRICT | CASCADE) ]
Drop a database with the given database name. If the database to drop does not exist, an exception is thrown.
IF EXISTS
If the database does not exist, nothing happens.
RESTRICT
Dropping a non-empty database triggers an exception. Enabled by default.
CASCADE
Dropping a non-empty database also drops all associated tables and functions.
create database if not exists catalog1.database1
drop database if exists catalog1.database1
-- 删除非空数据库,连通数据库中的所有表也一起删除
drop database if exists catalog1.database1 CASCADE● 创立 Table
1)Rename Table
ALTER TABLE [catalog_name.][db_name.]table_name RENAME TO new_table_name
Rename the given table name to another new table name2)Set or Alter Table Properties
ALTER TABLE [catalog_name.][db_name.]table_name SET (key1=val1, key2=val2, ...)
Set one or more properties in the specified table. If a particular property is already set in the table, override the old value with the new one.-- 创立表
CREATE TABLE if not exists catalog1.default_database.table1
(
id int,
name string,
age bigint,
primary key ( id) not enforced
) with (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://172.16.83.218:3306/wujuan?useSSL=false',
'table-name' = 't2',
'username' = 'drpeco',
'password' = 'DT@Stack#123'
);-- 删除表
drop table if exists mysql_catalog2.wujuan_database2.wujuan_table
-- 重命名表名
ALTER TABLE catalog1.default_database.table1 RENAME TO table2;
-- 设置表属性
ALTER TABLE catalog1.default_database.table1
SET (
'tablename'='t2',
'url'='dbc:mysql://172.16.83.218:3306/wujuan?useSSL=false'
)应用 DTCatalog 的具体场景和实现原理
● 全副是 DDL,只有 Catalog 的创立
CREATE CATALOG catalog1
WITH (
'type' = 'DT',
'default-database' = 'default_database',
'driver' = 'com.mysql.cj.jdbc.Driver',
'url' = 'jdbc:mysql://172.16.100.186:3306/catalog_default?autoReconnect=true&failOverReadOnly=false',
'username' = 'drpeco',
'password' = 'DT@Stack#123',
'project-id' = '1',
'tenant-id' = '1'
);· 能够执行,然而没有意义,ChunJun 不会存储 Catalog 信息,只有平台存储;
· 不反对语法校验。
● 全副是 DDL,蕴含 Catalog、Database、Table 的创立
— 初始化 Catalog
CREATE CATALOG catalog1
WITH (
'type' = 'dt',
'default-database' = 'default_database',
'driver' = 'com.mysql.cj.jdbc.Driver',
'url' = 'jdbc:mysql://172.16.100.186:3306/catalog_default',
'username' = 'drpeco',
'password' = 'DT@Stack#123',
'project-id' = '1',
'tenant-id' = '1');
— 创立数据库
create database if not exists database1
— 创立表
CREATE TABLE if not exists catalog1.default_database.table1
(
id int,
name string,
age bigint,
primary key ( id) not enforced) with (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://172.16.83.218:3306/wujuan?useSSL=false',
'table-name' = 't2',
'username' = 'drpeco',
'password' = 'DT@Stack#123');
· 无论创立数据库、表,删除数据库、表,必须蕴含 create catalog 语句;
· 能够执行,能够创立数据库和表;
· 不反对语法校验。
// 抛出异样的逻辑
StatementSet statementSet = SqlParser.parseSql(job, jarUrlList, tEnv);
TableResult execute = statementSet.execute(); –>
tableEnvironment.executeInternal(operations); –>
Pipeline pipeline = execEnv.createPipeline(transformations, tableConfig, jobName); –>
StreamGraph streamGraph = ExecutorUtils.generateStreamGraph(getExecutionEnvironment(), transformations); –>
// 抛出异样的办法
public static StreamGraph generateStreamGraph(StreamExecutionEnvironment execEnv, List<Transformation<?>> transformations){
if (transformations.size() <= 0) {
throw new IllegalStateException(
"No operators defined in streaming topology. Cannot generate StreamGraph.");
}
...
return generator.generate();}
// 如果没有 insert 语句的时候,无奈生成 JobGraph,然而 DDL 是执行胜利的。
// 因而捕捉 FlinkX 抛出的非凡异样,此语句的异样 Message 是 FlinkX 外面解决的。
try {
PackagedProgramUtils.createJobGraph(program, flinkConfig, 1, false);} catch (ProgramInvocationException e) {
// 仅执行 DDL FlinkX 抛出的异样
if (!e.getMessage().contains("OnlyExecuteDDL")) {
throw e;
}}
● DDL + DML,蕴含 create + insert 语句
1)初始化 Catalog
CREATE CATALOG catalog1
WITH (
'type' = 'dt',
'default-database' = 'default_database',
'driver' = 'com.mysql.cj.jdbc.Driver',
'url' = 'jdbc:mysql://172.16.100.186:3306/catalog_default',
'username' = 'drpeco',
'password' = 'DT@Stack#123',
'project-id' = '1',
'tenant-id' = '1');
2.1)创立数据库
create database if not exists database1
2.2)创立源表
CREATE TABLE if not exists catalog1.default_database.table1
(
id int,
name string,
age bigint,
primary key ( id) not enforced) with (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://172.16.83.218:3306/wujuan?useSSL=false',
'table-name' = 't2',
'username' = 'drpeco',
'password' = 'DT@Stack#123');
3.1)创立数据库create database if not exists catalog1.database2;
3.2)创立后果表CREATE TABLE if not exists catalog1.database2.table2
(
id int,
name string,
age bigint,
primary key ( id) not enforced) with (
‘connector’ = ‘print’
);
4)执行工作insert into catalog1.database2.table2 select * from catalog1.database1.table1
· 不能够执行,能够提交;
· 反对语法校验。
● DML,只有 Insert 语句
— 初始化 Catalog
CREATE CATALOG catalog1
WITH (
‘type’ = ‘dt’,
‘default-database’ = ‘default_database’,
‘driver’ = ‘com.mysql.cj.jdbc.Driver’,
‘url’ = ‘jdbc:mysql://172.16.100.186:3306/catalog_default’,
‘username’ = ‘drpeco’,
‘password’ = ‘DT@Stack#123’,
‘project-id’ = ‘1’,
‘tenant-id’ = ‘1’
);
— 执行工作
insert into catalog1.database2.table2 select * from catalog1.database1.table1
· 如果 Catalog 的 数据库和表都曾经创立好了,那么间接写 insert 就能够提交工作;
· 不能够执行,能够提交;
· 反对语法校验。
想理解或征询更多无关袋鼠云大数据产品、行业解决方案、客户案例的敌人,浏览袋鼠云官网:https://www.dtstack.com/?src=szsf
同时,欢送对大数据开源我的项目有趣味的同学退出「袋鼠云开源框架钉钉技术qun」,交换最新开源技术信息,qun号码:30537511,我的项目地址:https://github.com/DTStack
发表回复