目前所做的我的项目须要用到正则表达式,从新总结一下正则表达式。
正则表达式看似简略,实则门路颇多,究其原因也就是其太灵便了。齐全把握还是须要消耗一些功夫的。
一、正则表达式原字符
读者需对正则表达式元字符有一个初步的印象,理论利用时能够查阅文档。
正则表达式能够分为六类:限定符、抉择匹配符、分组组合和反向援用符、字符匹配符、定位符、特殊字符
1、限定符、本义符
| 字符 | 形容 |
|---|---|
| \ | 转义字符 |
| ^ | 匹配输出字符串的开始地位 |
| $ | 匹配输出字符串的完结地位 |
| * | 匹配后面的子表达式零次或屡次,等价于{0,} |
| + | 匹配后面的子表达式一次或屡次,等价于{1,} |
| ? | 匹配后面的子表达式零次或一次,等价于{0,1} |
| {n} | 匹配确定的n次 |
| {n,} | 至多匹配n次 |
| {n,m} | 起码匹配n次且最多匹配m次 |
| {?} | 当该字符紧跟在任何一个其余限制符(*,+,?,{n},{n,},{n,m})前面时,匹配模式是非贪心的 |
| {n,} | 至多匹配n次 |
| {\b} | 匹配一个单词边界 |
| {\B} | 匹配非单词边界 |
2、字符匹配符
| 字符 | 阐明 |
|---|---|
| [xyz] | 匹配所蕴含的任意一个字符 |
| 1 | 匹配未蕴含的任意字符 |
| [a-z] | 匹配指定范畴内的任意字符 |
| 2 | 匹配任何不在指定范畴内的任意字符 |
3、捕捉分组、非捕捉分组
| 字符 | 形容 |
|---|---|
| (pattern) | 匹配pattern并获取这一匹配 |
| (?:pattern) | 匹配pattern但不获取匹配后果,也就是说这是一个非获取匹配 |
| (?=pattern) | 在任何匹配pattern的字符串开始处匹配查找字符串 |
4、特殊字符
| 字符 | 形容 | |
|---|---|---|
| . | 匹配任何单词字符,除\n以外,要匹配包含“\n”在内的任何字符,请应用像“(. | \n)”的模式 |
| \d | 匹配一个数字字符。等价于[0-9] | |
| \D | 匹配一个数字字符。等价于[0-9] | |
| \r | 匹配一个换行 | |
| \s | 匹配任何空白字符 | |
| \S | 匹配任何非空白字符 | |
| \w | 匹配包含下划线的任何单词字符 | |
| \W | 匹配任何非单词字符 | |
| \t | 匹配一个制表符 | |
| \W | 匹配任何非单词字符 |
5、抉择匹配符
x|y 匹配x或y
6、罕用正则表达式
| 作用 | 表达式 | |
|---|---|---|
| 电子邮箱 | /^#?([a-f0-9]{6} | [a-f0-9]{3})$/ |
| URL | /^(https?://)?([\da-z.-]+).([a-z.]{2,6})([/\w .-])/?$/ |
二、java中表达式的利用
java中对正则表达式的利用次要是两个类,上面是列出的一些罕用办法,其中须要指明的是,这些都是静态方法。
1、Pattern类
compile(String regex) 将给定的正则表达式编译为Matcher。
matches(String regex, CharSequence input)间接匹配以后字符串
##### 2、Matcher类
find(int start) 查找是否存在匹配
group(int group) 获取匹配分组
matches() 匹配以后字符串
start() 匹配开始地位
end(int group) 匹配完结地位
replaceAll(String replacement) 匹配替换
三、实例
1、应用java的正则表达式的一个简略利用
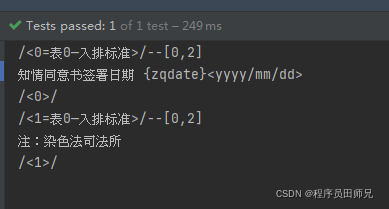
要求:提取出{abc}中的内容
@Test
public void test11(){
String str = "知情同意书签订日期 {zqdate}<yyyy/mm/dd>";
String reg = "\\{+[a-z]?+\\}"; // /<0=表0—入排规范>/--[0,2]
//将规定封装成对象。
Pattern p = Pattern.compile(reg);
//让正则对象和要作用的字符串相关联。获取匹配器对象。
Matcher m = p.matcher(str);
while(m.find())
{
System.out.println(m.group());
}
}后果
1、再整一个难活
有这样一串字符串
仔细观察这段字符串是 a–a–a模式的 我要的是–局部,而后我这样写。
发现提取进去只有一部分。
仔细分析后发现,java默认是采纳的贪心模式。而这段字符串是 a–a–a模式的,它把我第
一个a和最初一个a当做是匹配的一整个。
解决这个问题也很简略,只须要这样写
在限定符*前面加一个?标识这是一个非贪心模式,后果失常了,作为两局部返回了。
四、总结
置信读者能把这两个例子看懂正则表达式也能有一个初步的把握,而成为一个正则表达式高手就须要靠你了。
把握正则表达式肯定要多写,只有写的多了才能够熟记于心,不会的多查阅文档。
学常识要知其然,知其所以然。
过来出问题了只会在百度搜寻,而后在后果中一个个的尝试。
当初有问题了,一步步debug源码寻找问题的本源。心愿读者都能逐步转变学习形式。
即便看不懂源码的每一步,也能对整个过程有一个初步的意识,对于当前学习源码有极大的帮忙。
有问题小伙伴们评论区见喔。
- xyz ↩
- a-z ↩
发表回复