举荐:应用NSDT场景编辑器助你疾速搭建可编辑的3D利用场景
什么是 SQL 中的连贯?
SQL 联接容许您基于公共列合并来自多个数据库表的数据。这样,您就能够将信息合并在一起,并在相干数据集之间创立有意义的连贯。
SQL 中的连贯类型
有几种类型的 SQL 联接:
- 内联接
- 左外连贯
- 右外连贯
- 齐全内部联接
- 穿插连贯
让咱们解释每种类型。
SQL 外部联接
外部联接仅返回在要联接的两个表中存在匹配项的行。它基于共享键或列合并两个表中的行,抛弃不匹配的行。咱们通过以下形式对此进行可视化。
在 SQL 中,这种类型的连贯是应用关键字 JOIN 或 INNER JOIN 执行的。
SQL 左内部联接
左外连贯返回左侧(或第一个)表中的所有行和右侧(或第二个)表中的匹配行。如果没有匹配项,则返回右侧表中列的 NULL 值。咱们能够这样设想它。
如果要在 SQL 中应用此联接,能够应用 LEFT OUTER JOIN 或 LEFT JOIN 关键字来实现。这是一篇探讨左联接与左外联接的文章。
SQL 右外联接
右联接与左联接相同。它返回右侧表中的所有行和左侧表中的匹配行。如果没有匹配项,则返回左侧表中列的 NULL 值。
在 SQL 中,此连贯类型是应用关键字 RIGHT OUTER JOIN 或 RIGHT JOIN 执行的。
SQL 齐全内部联接
齐全内部联接返回两个表中的所有行,尽可能匹配行,并为不匹配的行填充 NULL 值。
SQL 中此联接的关键字是“齐全内部联接”或“齐全联接”。
SQL 穿插联接
这种类型的联接将一个表中的所有行与第二个表中的所有行合并在一起。换句话说,它返回笛卡尔积,即两个表行的所有可能组合。这是可视化成果,使其更容易了解。
在 SQL 中穿插联接时,关键字是 CROSS JOIN。
理解 SQL 联接语法
要在 SQL 中执行联接,您须要指定要联接的表、用于匹配的列以及要执行的联接类型。在 SQL 中联接表的根本语法如下:
SELECT columns
FROM table1
JOIN table2
ON table1.column = table2.column;此示例演示如何应用 JOIN。
援用 FROM 子句中的第一个(或左侧)表。而后,应用 JOIN 追随它并援用第二个(或右侧)表。
而后是 ON 子句中的连贯条件。您能够在此处指定将用于联接两个表的列。通常,它是一个共享列,它是一个表中的主键和第二个表中的外键。
留神:主键是表中每条记录的惟一标识符。外键在两个表之间建设链接,即它是第二个表中援用第一个表的列。咱们将在示例中向您展现这意味着什么。
如果你想应用左联接、右联接或齐全联接,你只需应用这些关键字而不是 JOIN ——代码中的其余所有都完全相同!穿插连贯的状况略有不同。
其性质是联接两个表中的所有行组合。这就是为什么不须要 ON 子句,语法如下所示。
SELECT columns
FROM table1
CROSS JOIN table2;换句话说,您只需在 FROM 中援用一个表,在 CROSS JOIN 中援用第二个表。
或者,您能够在 FROM 中援用这两个表并用逗号分隔它们 – 这是 CROSS JOIN 的简写。
`SELECT columns
FROM table1, table2;`
自连贯:SQL 中一种非凡类型的连贯
还有一种连贯表的特定办法 – 将表与本身连贯。这也称为自联表。它不齐全是一种独特的联接类型,因为后面提到的任何联接类型也可用于自联接。自联接的语法与我之前向您展现的语法相似。次要区别在于 FROM 和 JOIN 中援用了雷同的表。
SELECT columns
FROM table1 t1
JOIN table1 t2
ON t1.column = t2.column;此外,您须要为表提供两个别名以辨别它们。您正在做的是将表与本身联接,并将其视为两个表。
我只是想在这里提到这一点,但我不会进一步具体介绍。如果您对自退出感兴趣,请参阅这本对于 SQL 中自退出的图解指南。
SQL 联接示例
是时候向您展现我提到的所有内容在实践中是如何工作的了。我将应用 StrataScratch 中的 SQL JOIN 面试问题来展现 SQL 中每种不同类型的连贯。
- 连贯示例Microsoft的这个问题心愿您列出每个我的项目并按员工计算我的项目的估算。低廉的我的项目“给定映射到每个我的项目的我的项目和员工列表,按调配给每个员工的我的项目估算金额计算。输入应包含我的项目题目和我的项目估算,四舍五入到最靠近的整数。首先按每位员工估算最高的我的项目对列表进行排序。数据这个问题给出了两个表格。
ms_projects编号:国内
题目:瓦尔查尔
估算:国内
ms_emp_projects
emp_id:国内
project_id:国内当初,表 ms_projects 中的列 id 是表的主键。能够在表ms_emp_projects中找到雷同的列,只管名称不同:project_id。这是表的外键,援用第一个表。我将应用这两列来联接解决方案中的表。
法典
SELECT title AS project,
ROUND((budget/COUNT(emp_id)::FLOAT)::NUMERIC, 0) AS budget_emp_ratio
FROM ms_projects a
JOIN ms_emp_projects b
ON a.id = b.project_id
GROUP BY title, budget
ORDER BY budget_emp_ratio DESC;我应用 JOIN 连贯了两个表。表 ms_projects 在 FROM 中援用,而ms_emp_projects在 JOIN 之后援用。我为两个表提供了一个别名,这样我当前就不会应用该表的长名称。
当初,我须要指定要联接表的列。我曾经提到哪些列是一个表中的主键,哪些列是另一个表中的外键,所以我将在这里应用它们。
我相等这两列,因为我想获取我的项目 ID 雷同的所有数据。我还在每列后面应用了表的别名。
当初我能够拜访两个表中的数据,我能够在 SELECT 中列出列。第一列是项目名称,第二列是计算的。
此计算应用 COUNT() 函数来计算每个我的项目的员工人数。而后,我将每个我的项目的估算除以员工人数。我还将后果转换为十进制值并将其四舍五入到零小数位。
输入上面是查问返回的内容。
2. 左连贯示例
让咱们在Airbnb面试问题上练习这个退出。它心愿您找到每个城市的订单数量、客户数量和订单总成本。
客户订单和详细信息
“查找每个城市的订单数量、客户数量和订单总成本。仅包含至多下了 5 个订单的城市,并计算每个城市的所有客户,即便他们没有下订单。输入每个计算以及相应的城市名称。
数据您将取得客户和订单的表格。
客户
编号:国内
first_name:瓦尔查尔
last_name:瓦尔查尔
城市:瓦尔查尔
地址:瓦尔查尔
phone_number:瓦尔查尔
订单
编号:国内
cust_id:国内
order_date:日期工夫
order_details:瓦尔查尔
total_order_cost:国内共享列是来自表客户的 id,cust_id来自表订单。我将应用这些列来联接表。
法典
以下是应用左联接解决此问题的办法。
SELECT c.city,
COUNT(DISTINCT o.id) AS orders_per_city,
COUNT(DISTINCT c.id) AS customers_per_city,
SUM(o.total_order_cost) AS orders_cost_per_city
FROM customers c
LEFT JOIN orders o ON c.id = o.cust_id
GROUP BY c.city
HAVING COUNT(o.id) >=5;我在 FROM(这是咱们的左表)中援用表客户,并在客户 ID 列上将其与订单左连贯。
当初我能够抉择城市,应用 COUNT() 按城市获取订单和客户数量,并应用 SUM() 按城市计算总订单老本。
为了按城市取得所有这些计算,我按城市对输入进行分组。
问题中还有一个额定的要求:“仅包含至多下了 5 个订单的城市……”我应用“必须”仅显示具备五个或更多订单的城市来实现此目标。
问题是,为什么我应用了 LEFT JOIN 而不是 JOIN?线索在问题中:“…并计算每个城市的所有客户,即便他们没有下订单。可能并非所有客户都下了订单。这意味着我想显示表客户中的所有客户,这完全符合左连贯的定义。
如果我应用 JOIN,后果将是谬误的,因为我会错过没有下任何订单的客户。
留神:SQL 中连贯的复杂性并不反映在它们的语法上,而是反映在它们的语义上! 如您所见,每个联接的编写形式雷同,只是关键字产生了变动。然而,每个联接的工作形式不同,因而能够依据数据输入不同的后果。因而,您必须齐全理解每个联接的作用,并抉择可能精确返回您想要的联接!
输入
当初,让咱们看一下输入。
3. 右连贯示例
右联接是左联接的镜像。这就是为什么我能够应用RIGHT JOIN轻松解决之前的问题。让我通知你怎么做。数据表格放弃不变;我将只应用不同类型的联接。
法典
SELECT c.city,
COUNT(DISTINCT o.id) AS orders_per_city,
COUNT(DISTINCT c.id) AS customers_per_city,
SUM(o.total_order_cost) AS orders_cost_per_city
FROM orders o
RIGHT JOIN customers c ON o.cust_id = c.id
GROUP BY c.city
HAVING COUNT(o.id) >=5;以下是更改的内容。当我应用 RIGHT JOIN 时,我切换了表的程序。当初,表订单变为左订单,表客户订单变为右侧订单。连贯条件放弃不变。我只是切换了列的程序以反映表的程序,但没有必要这样做。
通过切换表的程序并应用 RIGHT JOIN,我将再次输入所有客户,即便他们没有下任何订单。
查问的其余部分与上一示例中雷同。输入也是如此。
留神:在实践中,右联接绝对较少应用。对于SQL用户来说,LEFT JOIN仿佛更天然,因而他们更频繁地应用它。任何能够用 RIGHT JOIN 实现的事件也能够用 LEFT JOIN 实现。因而,没有特定状况可能首选 RIGHT JOIN。
输入
4. 齐全连贯示例
Salesforce和特斯拉的问题心愿你计算2020年推出的产品公司数量与前一年推出的产品公司数量之间的净差别。
新产品“你会失去一个按公司按年份列出的产品公布表。编写一个查问来计算 2020 年推出的产品公司数量与上一年推出的产品公司数量之间的净差额。输入公司名称以及与上一年相比公布的2020年净产品净差额。
数据
该问题提供了一个蕴含以下列的表。
car_launches
年:国内
company_name:瓦尔查尔
product_name:瓦尔查尔
当只有一个表时,我将如何连贯表?嗯,让咱们也看看吧!法典这个查问有点简单,所以我会逐步揭示它。
SELECT company_name,
product_name AS brand_2020
FROM car_launches
WHERE YEAR = 2020;第一个 SELECT 语句查找 2020 年的公司和产品名称。此查问稍后将转换为子查问。
这个问题心愿你找到2020年和2019年之间的区别。因而,让咱们为2019年编写雷同的查问。`
SELECT company_name,
product_name AS brand_2019FROM car_launches
WHERE YEAR = 2019;
当初,我将把这些查问变成子查问,并应用齐全内部联接来联接它们。
SELECT *
FROM
(SELECT company_name,
product_name AS brand_2020FROM car_launches
WHERE YEAR = 2020) a
FULL OUTER JOIN
(SELECT company_name,
product_name AS brand_2019FROM car_launches
WHERE YEAR = 2019) b
ON a.company_name = b.company_name;
子查问能够被视为表,因而能够连贯。我给第一个子查问一个别名,并将其放在 FROM 子句中。而后,我应用“齐全内部联接”将其与公司名称列上的第二个子查问联接。
通过应用这种类型的 SQL 联接,我将在 2020 年的所有公司和产品与 2019 年的所有公司和产品合并。
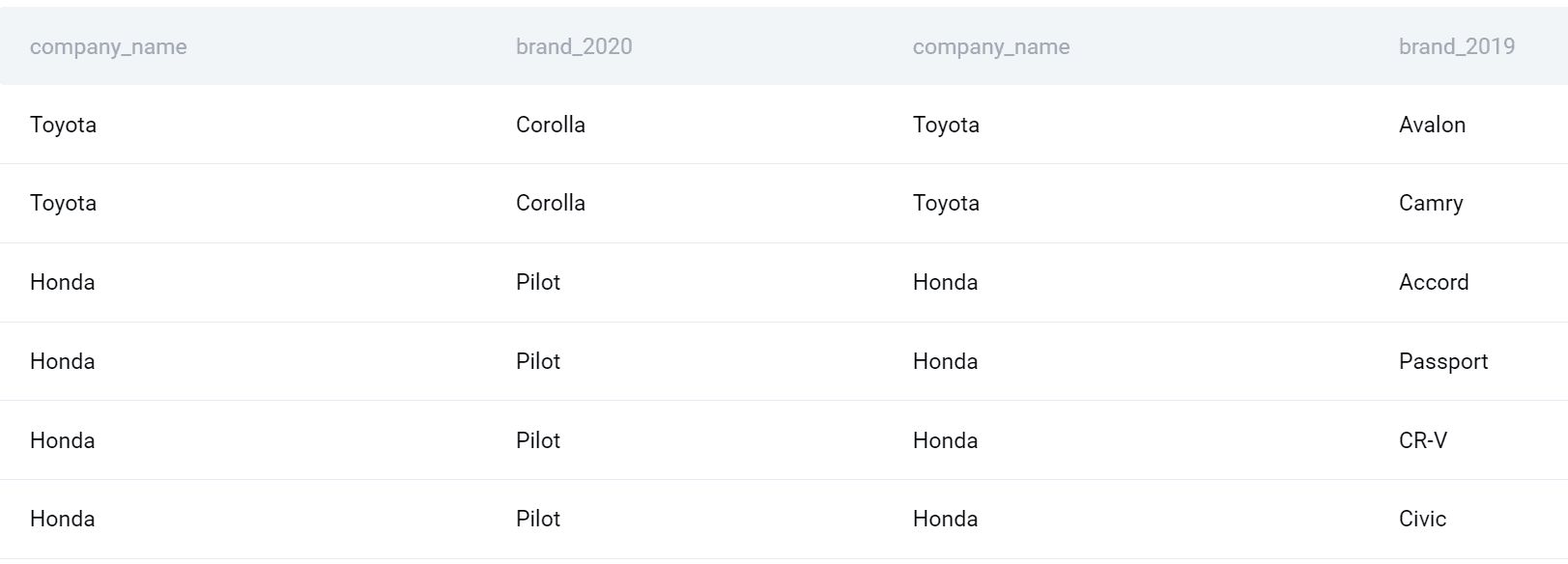
当初我能够实现我的查问了。让咱们抉择公司名称。此外,我将应用 COUNT() 函数查找每年推出的产品数量,而后减去它以取得差额。最初,我将按公司对输入进行分组,并按公司字母程序对其进行排序。
这是整个查问。
SELECT a.company_name,
(COUNT(DISTINCT a.brand_2020)-COUNT(DISTINCT b.brand_2019)) AS net_productsFROM
(SELECT company_name,
product_name AS brand_2020FROM car_launches
WHERE YEAR = 2020) a
FULL OUTER JOIN
(SELECT company_name,
product_name AS brand_2019FROM car_launches
WHERE YEAR = 2019) b
ON a.company_name = b.company_name
GROUP BY a.company_name
ORDER BY company_name;
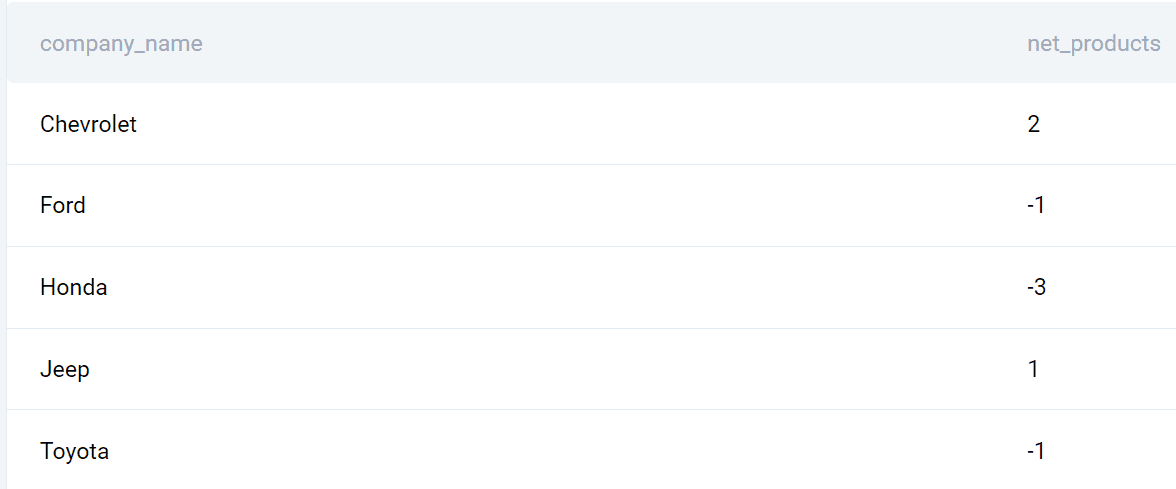
## 输入
以下是 2020 年和 2019 年之间的公司列表和推出的产品差别。
## 5. 穿插连贯示例
德勤的这个问题非常适合展现CROSS JOIN的工作原理。
最多两个数字“给定一列数字,思考两个数字的所有可能排列,假如数字对(x,y)和(y,x)是两个不同的排列。而后,对于每个排列,找到两个数字中的最大值。
输入三列:第一列、第二个数字和两列中的最大值。
该问题心愿您找到两个数字的所有可能排列,假如数字对 (x,y) 和 (y,x) 是两个不同的排列。而后,咱们须要找到每个排列的最大值。
## 数据
这个问题给了咱们一个带有一列的表格。
deloitte_numbers
数:国内
## 法典
此代码是 CROSS JOIN 的一个示例,也是自连贯的示例。
SELECT dn1.number AS number1,
dn2.number AS number2,
CASE
WHEN dn1.number > dn2.number THEN dn1.number
ELSE dn2.number
END AS max_numberFROM deloitte_numbers AS dn1
CROSS JOIN deloitte_numbers AS dn2;
我在 FROM 中援用该表并给它一个别名。而后,我通过在穿插连贯后援用它并为表提供另一个别名来将其与本身穿插连贯。
当初能够应用一个表,因为它们是两个。我从每个表中抉择列号。而后,我应用 CASE 语句设置一个条件,该条件将显示两个数字的最大数量。
为什么在这里应用穿插连贯?请记住,它是一种 SQL 联接类型,将显示所有表中所有行的所有组合。这正是问题要问的!
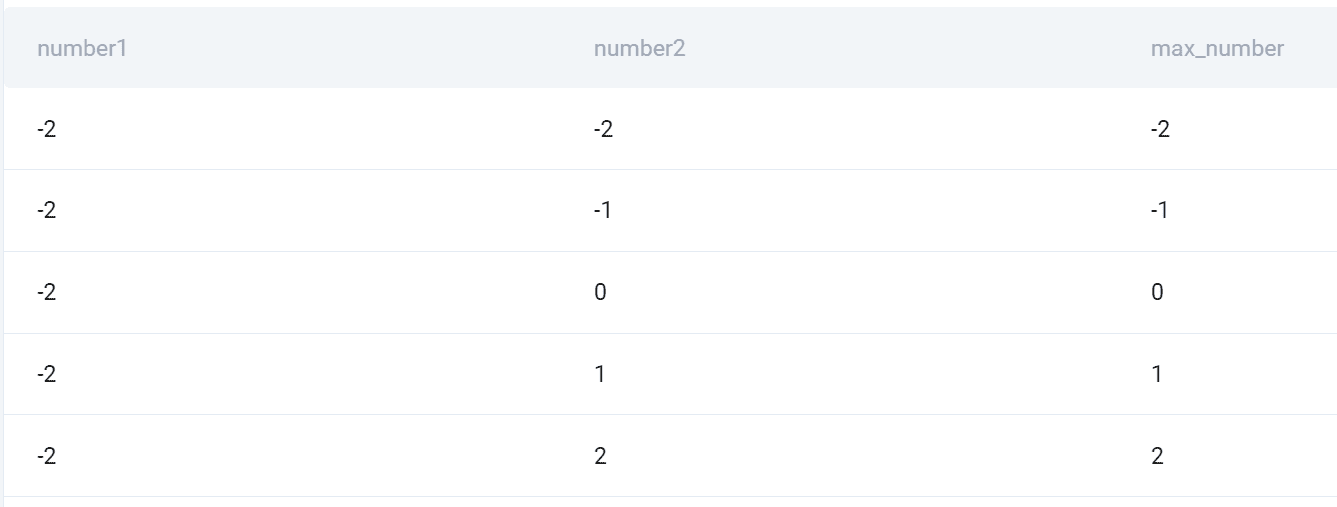
## 输入
这是所有组合的快照以及两者的较高数字。
## 将 SQL 联接用于数据迷信
当初您曾经晓得如何应用 SQL 联接,问题是如何在数据迷信中利用这些常识。
SQL 联接在数据迷信工作(如数据浏览、数据清理和特色工程)中起着至关重要的作用。
上面是如何利用 SQL 联接的几个示例:合并数据:通过联接表,能够将不同的数据源会集在一起,从而剖析多个数据集之间的关系和相关性。例如,将客户表与交易表联接能够提供对客户行为和购买模式的见解。
数据验证:联接可用于验证数据品质和完整性。通过比拟来自不同表的数据,能够辨认不统一、缺失值或异样值。这有助于您进行数据清理,并确保用于剖析的数据精确牢靠。
特色工程:联接有助于为机器学习模型创立新性能。通过合并相干表,您能够提取有意义的信息并生成捕捉数据中重要关系的特色。这能够加强模型的预测能力。
聚合和剖析:联接使您可能跨多个表执行简单的聚合和剖析。通过组合来自各种起源的数据,您能够全面理解数据并取得有价值的见解。例如,将销售表与产品表联接能够帮忙您按产品类别或区域分析销售业绩。
## SQL 联接的最佳做法
正如我曾经提到的,联接的复杂性并没有体现在它们的语法中。您看到语法绝对简略。
联接的最佳实际也反映了这一点,因为它们不关怀编码自身,而是联接的作用和性能。
若要充分利用 SQL 中的联接,请思考以下最佳做法。
* 理解您的数据: 相熟数据中的构造和关系。这将帮忙您抉择适当的联接类型,并抉择正确的列进行匹配。
*
* 应用索引:如果表很大或常常联接,请思考在用于联接的列上增加索引。索引能够显著进步查问性能。
*
* 留神性能:联接大型表或多个表的计算成本可能很高。通过筛选数据、应用适当的联接类型并思考应用长期表或子查问来优化查问。
*
* 测试和验证:始终验证联接后果以确保正确性。执行健全性查看并验证联接的数据是否合乎您的预期和业务逻辑。
论断
SQL 联接是一个基本概念,使数据科学家可能合并和剖析来自多个源的数据。通过理解不同类型的 SQL 联接、把握其语法并无效利用它们,数据科学家能够解锁有价值的见解、验证数据品质并推动数据驱动的决策。
我用五个例子向您展现了如何做到这一点。当初,您能够利用 SQL 的弱小性能并退出您的数据迷信我的项目并获得更好的后果。
原文链接[SQL 数据迷信:理解和利用连贯](https://www.mvrlink.com/sql-data-science-understanding-and-utilizing-joins/)
发表回复