原文链接:http://tecdat.cn/?p=18726
原文出处:拓端数据部落公众号
_自组织_映射神经网络(SOM)是一种无监督的数据可视化技术,可用于可视化低维(通常为 2 维)示意模式的高维数据集。在本文中,咱们钻研了如何应用 R 创立用于客户细分的 SOM。
SOM 由 1982 年在芬兰的 Teuvo Kohonen 首次形容,而 Kohonen 在该畛域的工作使他成为世界上被援用最多的芬兰科学家。通常,SOM 的可视化是六边形节点的黑白 2D 图。
SOM
SOM 可视化由多个“节点”组成。每个节点向量具备:
- 在 SOM 网格上的地位
- 与输出空间维度雷同的权重向量。(例如,如果您的输出数据代表人,则可能具备变量“年龄”,“性别”,“身高”和“体重”,网格上的每个节点也将具备这些变量的值)
- 输出数据中的关联样本。输出空间中的每个样本都“映射”或“链接”到网格上的节点。一个节点能够代表多个输出样本。
SOM 的要害特色是原始输出数据的拓扑特色保留在图上。这意味着将类似的输出样本(其中相似性是依据输出变量(年龄,性别,身高,体重)定义的)一起搁置在 SOM 网格上。例如,所有高度大概为 1.6m 的 55 岁女性将被映射到网格同一区域中的节点。思考到所有变量,身材矮小的人将被映射到其余中央。在身材上,高个的男性比小个的胖男性更靠近高个头的女性,因为他们“类似”得多。
SOM 热图
典型的 SOM 可视化是“热图”。热图显示了变量在 SOM 中的散布。现实状况下,类似年龄的人应该汇集在同一地区。
下图应用两个热图阐明均匀教育程度和失业率之间的关系。
SOM 算法
从样本数据集生成 SOM 的算法可总结如下:
- 抉择地图的大小和类型。形态能够是六边形或正方形,具体取决于所需节点的形态。通常,最好应用六边形网格,因为每个节点都具备 6 个近邻。
- 随机初始化所有节点权重向量。
- 从训练数据中抉择一个随机数据点,并将其出现给 SOM。
- 在地图上找到“最佳匹配单位”(BMU)–最类似的节点。应用欧几里德间隔公式计算类似度。
- 确定 BMU“街坊”内的节点。
–邻域的大小随每次迭代而减小。 - 所选数据点调整 BMU 邻域中节点的权重。
–学习率随着每次迭代而升高。
–调整幅度与节点与 BMU 的靠近水平成正比。 - 反复步骤 2 -5,进行 N 次迭代 / 收敛。
R 中的 SOM
训练
R 能够创立 SOM 和可视化。
# 在 R 中创立自组织映射
# 创立训练数据集(行是样本,列是变量
# 在这里,我抉择“数据”中可用的变量子集
data_train <- data\[, c(3,4,5,8)\]
#将带有训练数据的数据框更改为矩阵
#同时对所有变量进行标准化
#SOM 训练过程。data\_train\_matrix <- as.matrix(scale(data_train))
#创立 SOM 网格
#在训练 SOM 之前先训练网格
grid(xdim = 20, ydim=20, topo="hexagonal")
#最初,训练 SOM,迭代次数选项,#学习率
model <- som(data\_train\_matrix)可视化
可视化能够检察生成 SOM 的品质,并摸索数据集中变量之间的关系。
-
训练过程:
随着 SOM 训练迭代的进行,从每个节点的权重到该节点示意的样本的间隔将减小。现实状况下,该间隔应达到最小。此图选项显示了随着工夫的进度。如果曲线一直减小,则须要更多的迭代。#SOM 的训练进度 plot(model, type="changes")
-
节点计数
咱们能够可视化映射到地图上每个节点的样本数。此度量能够用作图品质的度量 - 现实状况下,样本分布绝对平均。抉择图大小时,每个节点至多要有 5 -10 个样本。# 节点数 plot(model, type="count")
-
街坊间隔
通常称为“U 矩阵”,此可视化示意每个节点与其街坊之间的间隔。通常应用灰度查看,街坊间隔低的区域示意类似的节点组。间隔较大的区域示意节点相异得多。U 矩阵可用于辨认 SOM 映射内的类别。# U-matrix 可视化
-
代码 / 权重向量
节点权重向量由用于生成 SOM 的原始变量值。每个节点的权重向量代表 / 类似于映射到该节点的样本。通过可视化整个地图上的权重向量,咱们能够看到样本和变量散布中的模型。权重向量的默认可视化是一个“扇形图”,其中为每个节点显示了权重向量中每个变量的大小的各个扇形示意。# 权重矢量视图
-
热图
** 热 ** 图是兴许是自组织图中最重要的可能的可视化。通常,SOM 过程创立多个热图,而后比拟这些热图以辨认图上乏味的区域。在这种状况下,咱们将 SOM 的均匀教育程度可视化。``` # 热图创立 ``` 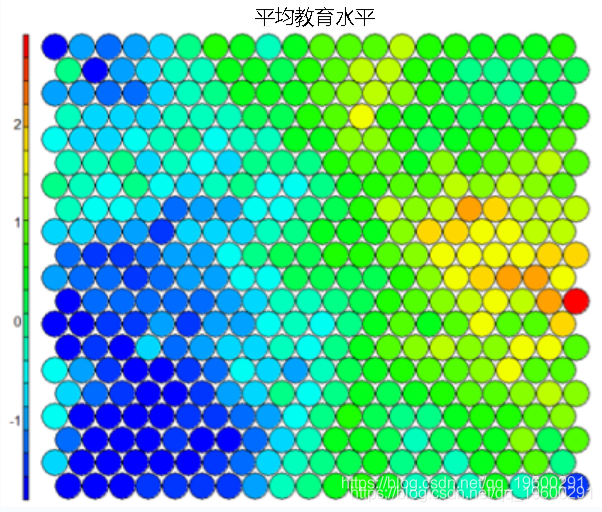
应该留神的是,该默认可视化绘制了感兴趣变量的标准化版本。```
# 未标准化的热图
#定义要绘制的变量
aggregate(as.numeric(data\_train, by=list(som\_model$unit.classi FUN=mean)
```
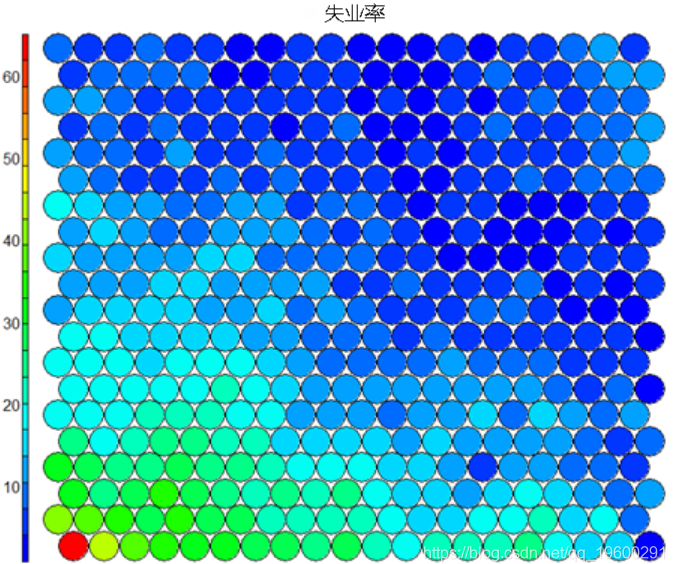
值得注意的是,下面的热图显示了失业率与教育程度之间的正比关系。并排显示的其余热图可用于构建不同区域及其特色的图片。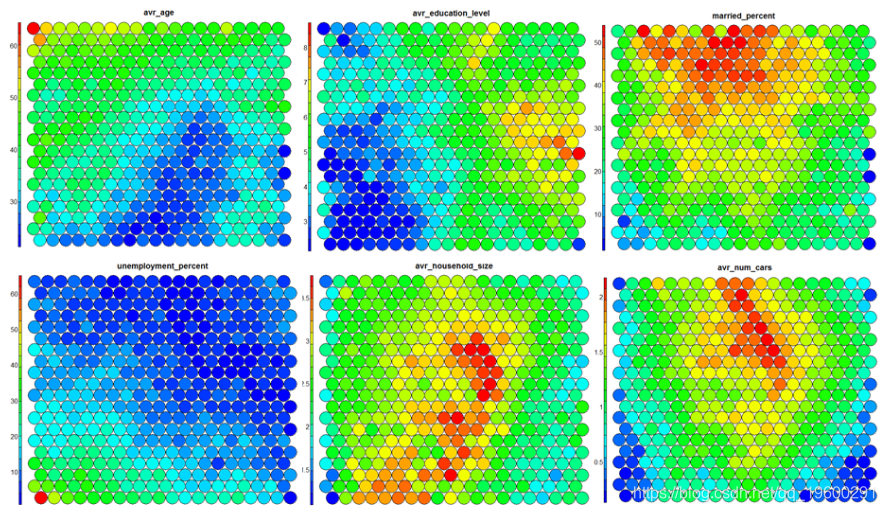
**SOM 网格中具备空节点的热图 **
在某些状况下,您的 SOM 训练可能会导致 SOM 图中的节点为空。通过几行,咱们能够找到 som_model $ unit.classif 中短少的节点,并将其替换为 NA 值–此步骤将避免空节点扭曲您的热图。```
# 当 SOM 中有空节点时绘制未标准化的变量
var\_unscaled <- aggregate(as.numeric(data\_train\_raw), by=list(som\_model$unit.classif), FUN=mean)
# 为未调配的节点增加 NA 值
missingNodes <- which(!(seq(1,nrow(som_model$codes) %in% varunscaled$Node))
# 将它们增加到未标准化的数据框
var\_unscaled <- rbind(var\_unscaled, data.frame(Node=missingNodes, Value=NA))
# 后果数据框
var_unscaled
# 当初仅应用正确的“值”创立热图。plot(som_model, type =d)
```
自组织图的聚类和宰割
能够在 SOM 节点上执行聚类,以发现具备类似度量的样本组。能够应用 kmeans 算法并查看“类内平方和之内”图中的“肘点”来确定适合的聚类数预计。
# 查看 WCSS 的 kmeans
for (i in 2:15) {wss\[i\] <- sum(kmeans(mydata, centers=i)$withinss)
}
# 可视化聚类后果
## 应用分层聚类对向量进行聚类
cutree(hclust(dist(som_model$codes)), 6)
# 绘制这些后果:plot(som\_model, t"mappinol =ty\_pal
现实状况下,发现的类别在图外表上是间断的。为了取得间断的聚类,能够应用仅在 SOM 网格上仅将类似 AND 的节点组合在一起的档次聚类算法。
将聚类映射回原始样本
当依照下面的代码示例利用聚类算法时,会将聚类调配给 SOM 映射上的每个 节点 ,而不是 数据集中的原始 样本。
# 为每个原始数据样本获取具备聚类值的向量
som\_clust\[som\_modl$unit.clasf\]
# 为每个原始数据样本获取具备聚类值的向量
data$cluster <- cluster_assignment应用每个聚类中训练变量的统计信息和散布来构建聚类特色的有意义的图片 - 这既是艺术又是迷信,聚类和可视化过程通常是一个迭代过程。
论断
自组织映射(SOM)是数据迷信中的一个弱小工具。劣势包含:
- 发现客户细分材料的直观办法。
- 绝对简略的算法,易于向非数据科学家解释后果
- 能够将新的数据点映射到经过训练的模型以进行预测。
毛病包含:
- 因为训练数据集是迭代的,因而对于十分大的数据集不足并行化性能
- 很难在二维立体上示意很多变量
- SOM 训练须要清理后的,数值的数据,这些数据很难取得。
最受欢迎的见解
1.R 语言 k -Shape 算法股票价格工夫序列聚类
2.R 语言中不同类型的聚类办法比拟
3.R 语言对用电负荷工夫序列数据进行 K -medoids 聚类建模和 GAM 回归
4.r 语言鸢尾花 iris 数据集的档次聚类
5.Python Monte Carlo K-Means 聚类实战
6. 用 R 进行网站评论文本开掘聚类
7. 用于 NLP 的 Python:应用 Keras 的多标签文本 LSTM 神经网络
8.R 语言对 MNIST 数据集剖析 摸索手写数字分类数据
9.R 语言基于 Keras 的小数据集深度学习图像分类