一、前言
老周这里编译 Kafka 的版本是 2.7,为啥采纳这个版本来搭建源码的浏览环境呢?因为该版本相对来说比拟新。而我为啥不必 2.7 后的版本呢?比方 2.8,这是因为去掉了 ZooKeeper,还不太稳固,生产环境也不太倡议应用,所以以 2.7 版本进行源码搭建并钻研。
二、环境筹备
- JDK:1.8.0_241
- Scala:2.12.8
- Gradle:6.6
- Zookeeper:3.4.14
三、环境搭建
3.1 JDK 环境搭建
这个就不必我说了吧,搞 Java 的本机都有 JDK 环境。
3.2 Scala 环境搭建
下载链接:https://www.scala-lang.org/download/2.12.8.html
这里老周是 Mac OS 零碎,这里大家看着本人的零碎来下就好了哈。
3.2.1 配置 Scala 环境变量
终端输出以下命令进行编辑:
vim ~/.bash_profile
# 这里的门路是你装置
SCALA_HOME=/Users/Riemann/Tools/scala-2.12.8
export SCALA_HOME
export PATH=$PATH:$SCALA_HOME/bin
# 使环境变量失效,在命令行执行。
source ~/.bash_profile3.2.2 验证
终端输出以下命令:
scala -version呈现以下提醒,阐明 Scala 环境搭建胜利。
3.3 Gradle 环境搭建
首先来到 Gradle官网:https://services.gradle.org/distributions/
如下图:
咱们抉择想要装置的公布版本,gradle-x.x-bin.zip 是须要下载的装置公布版,gradle-x.x-src.zip 是源码,gradle-x.x-all.zip 则是下载全副的文件。 我本地为 gradle-6.6。
Gradle下载的源码不须要装置,咱们将下载的压缩包在本机的目录下间接解压即可,解压后的目录如下图所示。
3.3.1 配置 Gradle 环境变量
终端输出以下命令进行编辑:
vim ~/.bash_profile
# 这里的门路是你装置
GRADLE_HOME=/Users/Riemann/Tools/gradle-6.6
export GRADLE_HOME
export PATH=$PATH:$GRADLE_HOME/bin
# 使环境变量失效,在命令行执行。
source ~/.bash_profile3.3.2 验证
终端输出以下命令:
gradle -v呈现以下提醒,阐明 Gradle 环境搭建胜利。
3.4 Zookeeper 环境搭建
Zookeeper 环境老周在 Linux 环境曾经搭建好了的,间接用。这里我也给出搭建的步骤,不论你是啥零碎,都是相似的~
3.4.1 下载
wget http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz3.4.2 解压
tar -zxvf zookeeper-3.4.14.tar.gz3.4.3 进入 zookeeper-3.4.14 目录,创立 data 文件夹
cd zookeeper-3.4.14
mkdir data3.4.4 批改配置文件
cd conf
mv zoo_sample.cfg zoo.cfg3.4.5 批改 zoo.cfg 中的 data 属性
dataDir=/root/zookeeper-3.4.14/data3.4.6 zookeeper 服务启动
进入 bin 目录,启动服务输出命令
./zkServer.sh start输入以下内容示意启动胜利
3.5 Kafka 源码环境搭建
官网下载对应版本的源码包,网址:http://kafka.apache.org/downloads
下载完后解压,这个源码文件还须要导入依赖 jar 包,集体应用 IDEA 来 import 导入我的项目,导入完后需应用后面配置好的 gradle 作为 Gradle home 地址。
3.5.1 导入 Kafka 源码至 IDEA
3.5.2 批改 build.gradle
接下来还不能导 jar 包,须要把镜像文件下载服务器更换为国内的私服,否则会相当慢,间接导致 “time out” 报错。
进入 kafka 源码包,批改 build.gradle 文件,在原来配置上,增加 ali 私服配置。
buildscript {
repositories {
maven {
url 'http://maven.aliyun.com/nexus/content/groups/public/'
}
maven {
url 'http://maven.aliyun.com/nexus/content/repositories/jcenter'
}
}
}
allprojects {
repositories {
maven {
url 'http://maven.aliyun.com/nexus/content/groups/public/'
}
maven {
url 'http://maven.aliyun.com/nexus/content/repositories/jcenter'
}
}
}
3.5.3 代码构建
能够用命令来构建,也能够在 idea 图形界面的 gradle 来构建,这里必定是 idea 图形化界面操作更简略,但这里也提供 gradle 的命令来构建。
./gradlew clean build -x test去找一下间接下载 Wrapper 所需的 Jar 包,手动把这个 Jar 文件拷贝到 kafka 门路下的 gradle/wrapper 子目录下,而后从新执行 gradlew build 命令去构建工程。
链接: https://pan.baidu.com/s/1W6EHysWY3ZWQZRWNdNZn3Q 提取码: hpj5
gradle 其它命令:
# 构建 jar包并运行
./gradlew jar
# 构建我的项目,看你是idea工具还是eclipse
./gradlew idea
./gradlew eclipse
# 构建源码包
./gradlew srcJar
# 构建javadoc文档
./gradlew aggregatedJavadoc
# 清理并构建
./gradlew clean四、代码构造
4.1 代码安装包构造
- bin 目录:保留 Kafka 工具行脚本,咱们熟知的 kafka-server-start 和 kafka-console-producer 等脚本都寄存在这里。
-
checkstyle 目录:代码标准,自动化检测。
Checkstyle 是什么,对于格式化的探讨就未曾中断过,到底什么才是正确的,什么才是谬误的,到当初也没有残缺的定论。但随着工夫倒退,慢慢衍生出一套标准进去。没有什么相对的正确和谬误,关键在于标准的定义。最闻名的就是 google style guide,Checkstyle 就是以这种格调开发出的一个自动化插件,来辅助判断代码格局是否满足标准。
该目录下的文件定义了工程代码格局的标准,咱们能够在 build.gradle 中看到相干 checkstyle 的配置和自动化代码格式化配置:
checkstyle 配置:
scala 自动化代码格式化配置:
- clients 目录:保留 Kafka 客户端代码,比方生产者和消费者的代码都在该目录下。
- config 目录:保留 Kafka 的配置文件,其中比拟重要的配置文件是 server.properties。
- connect 目录:保留 Connect 组件的源代码。 Kafka Connect 组件是用来实现 Kafka 与内部零碎之间的实时数据传输的。
- core 目录:保留 Broker 端代码。Kafka 服务器端代码全副保留在该目录下。
- docs 目录:Kafka 设计文档以及组件相干结构图。
- examples 目录:Kafka 样例相干目录。
-
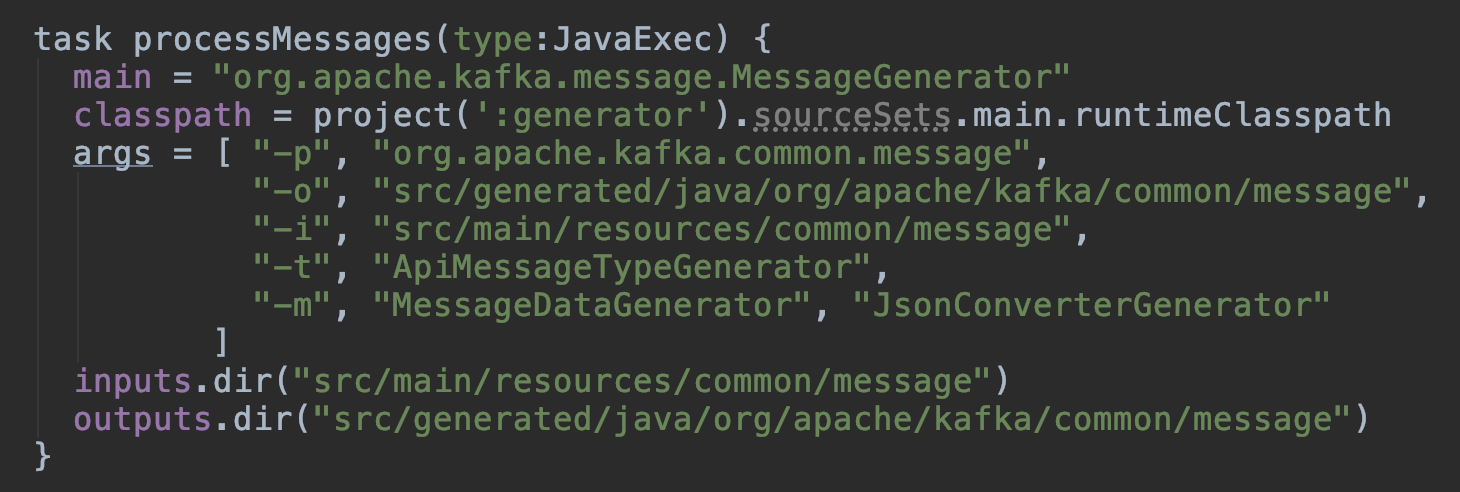
generator 目录:Kafka 音讯类解决模块,次要是依据 clients 模块下的 message json 文件生成对应的 java 类,在 build.gradle 文件中,能够看到定义了一个工作 processMessages:
 - gradle 目录:gradle 的脚本和依赖包定义等相干文件。
-
jmh-benchmarks 目录:Kafka 代码微基准测试相干类。
JMH,即 Java Microbenchmark Harness,是专门用于代码微基准测试的工具套件。何谓 Micro Benchmark 呢?简略的来说就是基于办法层面的基准测试,精度能够达到微秒级。当你定位到热点办法,心愿进一步优化办法性能的时候,就能够应用 JMH 对优化的后果进行量化的剖析。
JMH 比拟典型的利用场景有:
- 想精确的晓得某个办法须要执行多长时间,以及执行工夫和输出之间的相关性;
- 比照接口不同实现在给定条件下的吞吐量,找到最优实现。
- kafka-logs 目录:server.properties 文件中配置 log.dirs 生成的目录。
-
log4j-appender 目录:
A log4j appender that produces log messages to Kafka
这个目录外面就一个 KafkaLog4jAppender 类。
- raft 目录:raft 一致性协定相干。
-
streams 目录:
Kafka Streams is a client library for building applications and microservices, where the input and output data are stored in Kafka clusters.
提供一个基于 Kafka 的流式解决类库,间接提供具体的类给开发者调用,整个利用的运行形式次要由开发者管制,方便使用和调试。
Kafka Streams 是一个用来构建流处理程序的库,特地是其输出是一个 Kafka topic,输入是另一个 Kafka topic 的程序(或者是调用内部服务,或者是更新数据库,或者其它)。它使得你以一种分布式以及容错的形式来做这件事件。
- tests 目录:此目录的内容介绍如何进行 Kafka 系统集成和性能测试。
- tools 目录:工具类模块。
-
vagrant 目录:介绍如何在 Vagrant 虚构环境中运行 Kafka,提供了相干的脚本文件和阐明文档。
Vagrant 是一个基于 Ruby 的工具,用于创立和部署虚拟化开发环境。它应用 Oracle 的开源 VirtualBox 虚拟化零碎,应用 Chef 创立自动化虚拟环境。
4.2 我的项目构造
我的项目构造的话次要关注 core 目录,core 目录 是 Kafka 外围包,有集群治理,分区治理,存储管理,正本治理,消费者组治理,网络通信,生产治理等外围类。
- admin 包:执行治理命令的性能;
- api 包:封装申请和响应 DTO 对象;
- cluster 包:集群对象,例如 Replica 类代表一个分区正本,Partition 类代表一个分区;
- common 包:通用 jar 包;
- controller包: 和kafkaController(kc)相干的类,重点模块,一个kafka集群只有一个leader kc,该kc负责 分区治理,正本治理,并保障集群信息在集群中同步;
- coordinator 包:保留了消费者端的 GroupCoordinator 代码和用于事务的 TransactionCoordinator 代码。对 coordinator 包进行剖析,特地是对消费者端的 GroupCoordinator 代码进行剖析,是 Broker 端协调者组件设计原理的要害。
- log 包:保留了 Kafka 最外围的日志构造代码,包含日志、日志段、索引文件等, 另外,该包下还封装了 Log Compaction 的实现机制,是十分重要的源码包。
- network 包:封装了 Kafka 服务器端网络层的代码,特地是 SocketServer.scala 这个文件,是 Kafka 实现 Reactor 模式的具体操作类,十分值得一读。
- consumer 包:前面会抛弃该包,用 clients 包下 consumer 相干类代替。
- server 包:顾名思义,它是 Kafka 的服务器端主代码,外面的类十分多,很多要害的 Kafka 组件都寄存在这里,比方状态机、Purgatory 延时机制等。
- tools 包:工具类。
五、环境验证
上面咱们来验证一下 Kafka 源码环境是否搭建胜利。
5.1 首先,咱们在 core/src/main 目录下新建 resources 目录,再将 conf 目录下的 log4j.properties 配置文件拷贝到 resources 目录下。
如下图所示:
5.2 批改 conf 目录下的 server.properties 文件
log.dirs=/Users/Riemann/Code/framework-source-code-analysis/kafka-2.7.0-src/kafka-logsserver.properties 文件中的其余配置临时不必批改。
5.3 在 IDEA 中配置 kafka.Kafka 这个入口类
具体配置如下图所示:
5.4 启动 Kafka Broker
启动胜利的话,控制台输入没有异样,且能看到如下输入:
5.5 可能呈现以下异样
5.5.1 异样1
log4j:WARN No appenders could be found for logger (kafka.utils.Log4jControllerRegistration$).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.在 project structure 中退出 slf4j-log4j12-1.7.30.jar 和 log4j-1.2.17.jar 两个日志包,当然也能够在 build.gradle 中增加对应的配置来增加包。
办法1:
办法2:
compile group: 'log4j', name: 'log4j', version: '1.2.17'
compile group: 'org.slf4j', name: 'slf4j-api', version: '1.7.30'
compile group: 'org.slf4j', name: 'slf4j-log4j12', version: '1.7.30'加到 build.gradle 文件中的 core 模块:
5.5.2 异样2
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
5.6 发送、生产 message
咱们这里应用 Kafka 自带的脚本工具来验证下面搭建的 Kafka 源码环境
首先,咱们进入到 ${KAFKA_HOME}/bin 目录,通过 kafka-topics.sh 命令来创立一个名为 topic_test 的 topic:
执行成果如下图所示:
而后咱们通过 kafka-console-consumer.sh 命令启动一个命令行的 consumer 来生产 topic_test 这个 topic,如下:
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic_test
接下来,咱们通过 kafka-console-producer.sh 命令启动一个命令行的 producer 向 topic_test 这个 topic 中生成数据,如下:
当咱们输出一条 message 并回车之后,message 会发送到 topic_test 这个 topic 中。
咱们输出完 message 并回车之后,就能够在 consumer 处收到该 message 了,成果如下图所示:
功败垂成,后续会陆续剖析 Kafka Broker 端的源码,纵情期待~
发表回复