实现 LRU 淘汰算法
LRU 缓存算法是一个十分经典的算法,在很多面试中常常问道,不仅仅包含前端面试
LRU英文全称是Least Recently Used,英译过去就是”最近起码应用“的意思。LRU是一种罕用的页面置换算法,抉择最近最久未应用的页面予以淘汰。该算法赋予每个页面一个拜访字段,用来记录一个页面自上次被拜访以来所经验的工夫t,当须淘汰一个页面时,抉择现有页面中其t值最大的,即最近起码应用的页面予以淘汰
艰深的解释:
如果咱们有一块内存,专门用来缓存咱们最近发拜访的网页,拜访一个新网页,咱们就会往内存中增加一个网页地址,随着网页的一直减少,内存存满了,这个时候咱们就须要思考删除一些网页了。这个时候咱们找到内存中最早拜访的那个网页地址,而后把它删掉。这一整个过程就能够称之为
LRU算法
上图就很好的解释了 LRU 算法在干嘛了,其实非常简单,无非就是咱们往内存外面增加或者删除元素的时候,遵循 最近起码应用准则
应用场景
LRU 算法应用的场景十分多,这里简略举几个例子即可:
- 咱们操作系统底层的内存治理,其中就包含有
LRU算法 - 咱们常见的缓存服务,比方
redis等等 - 比方浏览器的最近浏览记录存储
vue中的keep-alive组件应用了LRU算法
梳理实现 LRU 思路
-
特点剖析:
- 咱们须要一块无限的存储空间,因为有限的化就没必要应用
LRU算发删除数据了。 - 咱们这块存储空间外面存储的数据须要是有序的,因为咱们必须要程序来删除数据,所以能够思考应用
Array、Map数据结构来存储,不能应用Object,因为它是无序的。 - 咱们可能删除或者增加以及获取到这块存储空间中的指定数据。
- 存储空间存满之后,在增加数据时,会主动删除工夫最长远的那条数据。
- 咱们须要一块无限的存储空间,因为有限的化就没必要应用
-
实现需求:
- 实现一个
LRUCache类型,用来充当存储空间 - 采纳
Map数据结构存储数据,因为它的存取时间复杂度为O(1),数组为O(n) - 实现
get和set办法,用来获取和增加数据 - 咱们的存储空间有长度限度,所以无需提供删除办法,存储满之后,主动删除最长远的那条数据
- 当应用
get获取数据后,该条数据须要更新到最后面
- 实现一个
具体实现
class LRUCache {constructor(length) {
this.length = length; // 存储长度
this.data = new Map(); // 存储数据}
// 存储数据,通过键值对的形式
set(key, value) {
const data = this.data;
if (data.has(key)) {data.delete(key)
}
data.set(key, value);
// 如果超出了容量,则须要删除最久的数据
if (data.size > this.length) {const delKey = data.keys().next().value;
data.delete(delKey);
}
}
// 获取数据
get(key) {
const data = this.data;
// 未找到
if (!data.has(key)) {return null;}
const value = data.get(key); // 获取元素
data.delete(key); // 删除元素
data.set(key, value); // 从新插入元素
return value // 返回获取的值
}
}
var lruCache = new LRUCache(5);set 办法:往map外面增加新数据,如果增加的数据存在了,则先删除该条数据,而后再增加。如果增加数据后超长了,则须要删除最长远的一条数据。data.keys().next().value便是获取最初一条数据的意思。get 办法:首先从map对象中拿出该条数据,而后删除该条数据,最初再从新插入该条数据,确保将该条数据挪动到最后面
// 测试
// 存储数据 set:lruCache.set('name', 'test');
lruCache.set('age', 10);
lruCache.set('sex', '男');
lruCache.set('height', 180);
lruCache.set('weight', '120');
console.log(lruCache);持续插入数据,此时会超长,代码如下:
lruCache.set('grade', '100');
console.log(lruCache);此时咱们发现存储工夫最久的 name 曾经被移除了,新插入的数据变为了最后面的一个。
咱们应用 get 获取数据,代码如下:
咱们发现此时 sex 字段曾经跑到最后面去了
总结
LRU算法其实逻辑十分的简略,明确了原理之后实现起来十分的简略。最次要的是咱们须要应用什么数据结构来存储数据,因为map的存取十分快,所以咱们采纳了它,当然数组其实也能够实现的。还有一些小伙伴应用链表来实现LRU,这当然也是能够的。
将虚构 Dom 转化为实在 Dom
{
tag: 'DIV',
attrs:{id:'app'},
children: [
{
tag: 'SPAN',
children: [{ tag: 'A', children: [] }
]
},
{
tag: 'SPAN',
children: [{ tag: 'A', children: [] },
{tag: 'A', children: [] }
]
}
]
}
把下面虚构 Dom 转化成下方实在 Dom
<div id="app">
<span>
<a></a>
</span>
<span>
<a></a>
<a></a>
</span>
</div>实现
// 真正的渲染函数
function _render(vnode) {
// 如果是数字类型转化为字符串
if (typeof vnode === "number") {vnode = String(vnode);
}
// 字符串类型间接就是文本节点
if (typeof vnode === "string") {return document.createTextNode(vnode);
}
// 一般 DOM
const dom = document.createElement(vnode.tag);
if (vnode.attrs) {
// 遍历属性
Object.keys(vnode.attrs).forEach((key) => {const value = vnode.attrs[key];
dom.setAttribute(key, value);
});
}
// 子数组进行递归操作
vnode.children.forEach((child) => dom.appendChild(_render(child)));
return dom;
}实现一个迭代器生成函数
ES6 对迭代器的实现
JS 原生的汇合类型数据结构,只有 Array(数组)和Object(对象);而ES6 中,又新增了 Map 和Set。四种数据结构各自有着本人特地的外部实现,但咱们仍期待以同样的一套规定去遍历它们,所以 ES6 在推出新数据结构的同时也推出了一套 对立的接口机制 ——迭代器(Iterator)。
ES6约定,任何数据结构只有具备Symbol.iterator属性(这个属性就是Iterator的具体实现,它实质上是以后数据结构默认的迭代器生成函数),就能够被遍历——精确地说,是被for...of...循环和迭代器的 next 办法遍历。事实上,for...of...的背地正是对next办法的重复调用。
在 ES6 中,针对 Array、Map、Set、String、TypedArray、函数的 arguments 对象、NodeList 对象这些原生的数据结构都能够通过for...of... 进行遍历。原理都是一样的,此处咱们拿最简略的数组进行举例,当咱们用 for...of... 遍历数组时:
const arr = [1, 2, 3]
const len = arr.length
for(item of arr) {console.log(` 以后元素是 ${item}`)
}之所以可能按程序一次一次地拿到数组里的每一个成员,是因为咱们借助数组的
Symbol.iterator生成了它对应的迭代器对象,通过重复调用迭代器对象的next办法拜访了数组成员,像这样:
const arr = [1, 2, 3]
// 通过调用 iterator,拿到迭代器对象
const iterator = arr[Symbol.iterator]()
// 对迭代器对象执行 next,就能一一拜访汇合的成员
iterator.next()
iterator.next()
iterator.next()丢进控制台,咱们能够看到 next 每次会按程序帮咱们拜访一个汇合成员:
而
for...of...做的事件,根本等价于上面这通操作:
// 通过调用 iterator,拿到迭代器对象
const iterator = arr[Symbol.iterator]()
// 初始化一个迭代后果
let now = {done: false}
// 循环往外迭代成员
while(!now.done) {now = iterator.next()
if(!now.done) {console.log(` 当初遍历到了 ${now.value}`)
}
}能够看出,
for...of...其实就是iterator循环调用换了种写法。在 ES6 中咱们之所以可能开心地用for...of...遍历各种各种的汇合,全靠迭代器模式在背地给力。
ps:此处举荐浏览迭代协定 (opens new window),置信大家读过后会对迭代器在 ES6 中的实现有更深的了解。
实现深拷贝
简洁版本
简略版:
const newObj = JSON.parse(JSON.stringify(oldObj));局限性:
- 他无奈实现对函数、RegExp 等非凡对象的克隆
- 会摈弃对象的
constructor, 所有的构造函数会指向Object - 对象有循环援用, 会报错
面试简版
function deepClone(obj) {
// 如果是 值类型 或 null,则间接 return
if(typeof obj !== 'object' || obj === null) {return obj}
// 定义后果对象
let copy = {}
// 如果对象是数组,则定义后果数组
if(obj.constructor === Array) {copy = []
}
// 遍历对象的 key
for(let key in obj) {
// 如果 key 是对象的自有属性
if(obj.hasOwnProperty(key)) {
// 递归调用深拷贝办法
copy[key] = deepClone(obj[key])
}
}
return copy
} 调用深拷贝办法,若属性为值类型,则间接返回;若属性为援用类型,则递归遍历。这就是咱们在解这一类题时的外围的办法。
进阶版
- 解决拷贝循环援用问题
- 解决拷贝对应原型问题
// 递归拷贝 (类型判断)
function deepClone(value,hash = new WeakMap){ // 弱援用,不必 map,weakMap 更适合一点
// null 和 undefiend 是不须要拷贝的
if(value == null){return value;}
if(value instanceof RegExp) {return new RegExp(value) }
if(value instanceof Date) {return new Date(value) }
// 函数是不须要拷贝
if(typeof value != 'object') return value;
let obj = new value.constructor(); // [] {}
// 阐明是一个对象类型
if(hash.get(value)){return hash.get(value)
}
hash.set(value,obj);
for(let key in value){ // in 会遍历以后对象上的属性 和 __proto__指代的属性
// 补拷贝 对象的__proto__上的属性
if(value.hasOwnProperty(key)){
// 如果值还有可能是对象 就持续拷贝
obj[key] = deepClone(value[key],hash);
}
}
return obj
// 辨别对象和数组 Object.prototype.toString.call
}// test
var o = {};
o.x = o;
var o1 = deepClone(o); // 如果这个对象拷贝过了 就返回那个拷贝的后果就能够了
console.log(o1);实现残缺的深拷贝
1. 简易版及问题
JSON.parse(JSON.stringify());预计这个 api 能笼罩大多数的利用场景,没错,谈到深拷贝,我第一个想到的也是它。然而实际上,对于某些严格的场景来说,这个办法是有微小的坑的。问题如下:
- 无奈解决
循环援用的问题。举个例子:
const a = {val:2};
a.target = a;拷贝
a会呈现零碎栈溢出,因为呈现了有限递归的状况。
- 无奈拷贝一些非凡的对象,诸如
RegExp, Date, Set, Map等 - 无奈拷贝
函数(划重点)。
因而这个 api 先 pass 掉,咱们从新写一个深拷贝,简易版如下:
const deepClone = (target) => {if (typeof target === 'object' && target !== null) {const cloneTarget = Array.isArray(target) ? []: {};
for (let prop in target) {if (target.hasOwnProperty(prop)) {cloneTarget[prop] = deepClone(target[prop]);
}
}
return cloneTarget;
} else {return target;}
}当初,咱们以刚刚发现的三个问题为导向,一步步来欠缺、优化咱们的深拷贝代码。
2. 解决循环援用
当初问题如下:
let obj = {val : 100};
obj.target = obj;
deepClone(obj);// 报错: RangeError: Maximum call stack size exceeded这就是循环援用。咱们怎么来解决这个问题呢?
创立一个 Map。记录下曾经拷贝过的对象,如果说曾经拷贝过,那间接返回它行了。
const isObject = (target) => (typeof target === 'object' || typeof target === 'function') && target !== null;
const deepClone = (target, map = new Map()) => {if(map.get(target))
return target;
if (isObject(target)) {map.set(target, true);
const cloneTarget = Array.isArray(target) ? []: {};
for (let prop in target) {if (target.hasOwnProperty(prop)) {cloneTarget[prop] = deepClone(target[prop],map);
}
}
return cloneTarget;
} else {return target;}
}当初来试一试:
const a = {val:2};
a.target = a;
let newA = deepClone(a);
console.log(newA)//{val: 2, target: { val: 2, target: [Circular] } }如同是没有问题了, 拷贝也实现了。但还是有一个潜在的坑, 就是 map 上的 key 和 map 形成了强援用关系,这是相当危险的。我给你解释一下与之绝对的弱援用的概念你就明确了
在计算机程序设计中,弱援用与强援用绝对,
被弱援用的对象能够在任何时候被回收,而对于强援用来说,只有这个强援用还在,那么对象无奈被回收。拿下面的例子说,map 和 a 始终是强援用的关系,在程序完结之前,a 所占的内存空间始终不会被开释。
怎么解决这个问题?
很简略,让 map 的 key 和 map 形成弱援用即可。ES6 给咱们提供了这样的数据结构,它的名字叫 WeakMap,它是一种非凡的 Map, 其中的键是弱援用的。其键必须是对象,而值能够是任意的
略微革新一下即可:
const deepClone = (target, map = new WeakMap()) => {//...}3. 拷贝非凡对象
可持续遍历
对于非凡的对象,咱们应用以下形式来甄别:
Object.prototype.toString.call(obj);梳理一下对于可遍历对象会有什么后果:
["object Map"]
["object Set"]
["object Array"]
["object Object"]
["object Arguments"]以这些不同的字符串为根据,咱们就能够胜利地甄别这些对象。
const getType = Object.prototype.toString.call(obj);
const canTraverse = {'[object Map]': true,
'[object Set]': true,
'[object Array]': true,
'[object Object]': true,
'[object Arguments]': true,
};
const deepClone = (target, map = new Map()) => {if(!isObject(target))
return target;
let type = getType(target);
let cloneTarget;
if(!canTraverse[type]) {
// 解决不能遍历的对象
return;
}else {
// 这波操作相当要害,能够保障对象的原型不失落!let ctor = target.prototype;
cloneTarget = new ctor();}
if(map.get(target))
return target;
map.put(target, true);
if(type === mapTag) {
// 解决 Map
target.forEach((item, key) => {cloneTarget.set(deepClone(key), deepClone(item));
})
}
if(type === setTag) {
// 解决 Set
target.forEach(item => {target.add(deepClone(item));
})
}
// 解决数组和对象
for (let prop in target) {if (target.hasOwnProperty(prop)) {cloneTarget[prop] = deepClone(target[prop]);
}
}
return cloneTarget;
}不可遍历的对象
const boolTag = '[object Boolean]';
const numberTag = '[object Number]';
const stringTag = '[object String]';
const dateTag = '[object Date]';
const errorTag = '[object Error]';
const regexpTag = '[object RegExp]';
const funcTag = '[object Function]';对于不可遍历的对象,不同的对象有不同的解决。
const handleRegExp = (target) => {const { source, flags} = target;
return new target.constructor(source, flags);
}
const handleFunc = (target) => {// 待会的重点局部}
const handleNotTraverse = (target, tag) => {
const Ctor = targe.constructor;
switch(tag) {
case boolTag:
case numberTag:
case stringTag:
case errorTag:
case dateTag:
return new Ctor(target);
case regexpTag:
return handleRegExp(target);
case funcTag:
return handleFunc(target);
default:
return new Ctor(target);
}
}4. 拷贝函数
- 尽管函数也是对象,然而它过于非凡,咱们独自把它拿进去拆解。
- 提到函数,在 JS 种有两种函数,一种是一般函数,另一种是箭头函数。每个一般函数都是
- Function 的实例,而箭头函数不是任何类的实例,每次调用都是不一样的援用。那咱们只须要
- 解决一般函数的状况,箭头函数间接返回它自身就好了。
那么如何来辨别两者呢?
答案是: 利用原型。箭头函数是不存在原型的。
const handleFunc = (func) => {
// 箭头函数间接返回本身
if(!func.prototype) return func;
const bodyReg = /(?<={)(.|\n)+(?=})/m;
const paramReg = /(?<=\().+(?=\)\s+{)/;
const funcString = func.toString();
// 别离匹配 函数参数 和 函数体
const param = paramReg.exec(funcString);
const body = bodyReg.exec(funcString);
if(!body) return null;
if (param) {const paramArr = param[0].split(',');
return new Function(...paramArr, body[0]);
} else {return new Function(body[0]);
}
}5. 残缺代码展现
const getType = obj => Object.prototype.toString.call(obj);
const isObject = (target) => (typeof target === 'object' || typeof target === 'function') && target !== null;
const canTraverse = {'[object Map]': true,
'[object Set]': true,
'[object Array]': true,
'[object Object]': true,
'[object Arguments]': true,
};
const mapTag = '[object Map]';
const setTag = '[object Set]';
const boolTag = '[object Boolean]';
const numberTag = '[object Number]';
const stringTag = '[object String]';
const symbolTag = '[object Symbol]';
const dateTag = '[object Date]';
const errorTag = '[object Error]';
const regexpTag = '[object RegExp]';
const funcTag = '[object Function]';
const handleRegExp = (target) => {const { source, flags} = target;
return new target.constructor(source, flags);
}
const handleFunc = (func) => {
// 箭头函数间接返回本身
if(!func.prototype) return func;
const bodyReg = /(?<={)(.|\n)+(?=})/m;
const paramReg = /(?<=\().+(?=\)\s+{)/;
const funcString = func.toString();
// 别离匹配 函数参数 和 函数体
const param = paramReg.exec(funcString);
const body = bodyReg.exec(funcString);
if(!body) return null;
if (param) {const paramArr = param[0].split(',');
return new Function(...paramArr, body[0]);
} else {return new Function(body[0]);
}
}
const handleNotTraverse = (target, tag) => {
const Ctor = target.constructor;
switch(tag) {
case boolTag:
return new Object(Boolean.prototype.valueOf.call(target));
case numberTag:
return new Object(Number.prototype.valueOf.call(target));
case stringTag:
return new Object(String.prototype.valueOf.call(target));
case symbolTag:
return new Object(Symbol.prototype.valueOf.call(target));
case errorTag:
case dateTag:
return new Ctor(target);
case regexpTag:
return handleRegExp(target);
case funcTag:
return handleFunc(target);
default:
return new Ctor(target);
}
}
const deepClone = (target, map = new WeakMap()) => {if(!isObject(target))
return target;
let type = getType(target);
let cloneTarget;
if(!canTraverse[type]) {
// 解决不能遍历的对象
return handleNotTraverse(target, type);
}else {
// 这波操作相当要害,能够保障对象的原型不失落!let ctor = target.constructor;
cloneTarget = new ctor();}
if(map.get(target))
return target;
map.set(target, true);
if(type === mapTag) {
// 解决 Map
target.forEach((item, key) => {cloneTarget.set(deepClone(key, map), deepClone(item, map));
})
}
if(type === setTag) {
// 解决 Set
target.forEach(item => {cloneTarget.add(deepClone(item, map));
})
}
// 解决数组和对象
for (let prop in target) {if (target.hasOwnProperty(prop)) {cloneTarget[prop] = deepClone(target[prop], map);
}
}
return cloneTarget;
}实现 map 办法
- 回调函数的参数有哪些,返回值如何解决
- 不批改原来的数组
Array.prototype.myMap = function(callback, context){
// 转换类数组
var arr = Array.prototype.slice.call(this),// 因为是 ES5 所以就不必... 开展符了
mappedArr = [],
i = 0;
for (; i < arr.length; i++){// 把以后值、索引、以后数组返回去。调用的时候传到函数参数中 [1,2,3,4].map((curr,index,arr))
mappedArr.push(callback.call(context, arr[i], i, this));
}
return mappedArr;
}实现 Array.of 办法
Array.of()办法用于将一组值,转换为数组
- 这个办法的次要目标,是补救数组构造函数
Array()的有余。因为参数个数的不同,会导致Array()的行为有差别。 Array.of()基本上能够用来代替Array()或new Array(),并且不存在因为参数不同而导致的重载。它的行为十分对立
Array.of(3, 11, 8) // [3,11,8]
Array.of(3) // [3]
Array.of(3).length // 1实现
function ArrayOf(){return [].slice.call(arguments);
}参考 前端进阶面试题具体解答
实现一下 hash 路由
根底的 html 代码:
<html>
<style>
html, body {
margin: 0;
height: 100%;
}
ul {
list-style: none;
margin: 0;
padding: 0;
display: flex;
justify-content: center;
}
.box {
width: 100%;
height: 100%;
background-color: red;
}
</style>
<body>
<ul>
<li>
<a href="#red"> 红色 </a>
</li>
<li>
<a href="#green"> 绿色 </a>
</li>
<li>
<a href="#purple"> 紫色 </a>
</li>
</ul>
</body>
</html>简略实现:
<script>
const box = document.getElementsByClassName('box')[0];
const hash = location.hash
window.onhashchange = function (e) {const color = hash.slice(1)
box.style.background = color
}
</script>封装成一个 class:
<script>
const box = document.getElementsByClassName('box')[0];
const hash = location.hash
class HashRouter {constructor (hashStr, cb) {
this.hashStr = hashStr
this.cb = cb
this.watchHash()
this.watch = this.watchHash.bind(this)
window.addEventListener('hashchange', this.watch)
}
watchHash () {let hash = window.location.hash.slice(1)
this.hashStr = hash
this.cb(hash)
}
}
new HashRouter('red', (color) => {box.style.background = color})
</script>实现 apply 办法
思路: 利用
this的上下文个性。apply其实就是改一下参数的问题
Function.prototype.myApply = function(context = window, args) {
// this-->func context--> obj args--> 传递过去的参数
// 在 context 上加一个惟一值不影响 context 上的属性
let key = Symbol('key')
context[key] = this; // context 为调用的上下文,this 此处为函数,将这个函数作为 context 的办法
// let args = [...arguments].slice(1) // 第一个参数为 obj 所以删除, 伪数组转为数组
let result = context[key](...args); // 这里和 call 传参不一样
// 革除定义的 this 不删除会导致 context 属性越来越多
delete context[key];
// 返回后果
return result;
}// 应用
function f(a,b){console.log(a,b)
console.log(this.name)
}
let obj={name:'张三'}
f.myApply(obj,[1,2]) //arguments[1]实现单例模式
外围要点: 用闭包和
Proxy属性拦挡
function proxy(func) {
let instance;
let handler = {constructor(target, args) {if(!instance) {instance = Reflect.constructor(fun, args);
}
return instance;
}
}
return new Proxy(func, handler);
}对象数组如何去重
依据每个对象的某一个具体属性来进行去重
const responseList = [{ id: 1, a: 1},
{id: 2, a: 2},
{id: 3, a: 3},
{id: 1, a: 4},
];
const result = responseList.reduce((acc, cur) => {const ids = acc.map(item => item.id);
return ids.includes(cur.id) ? acc : [...acc, cur];
}, []);
console.log(result); // -> [{ id: 1, a: 1}, {id: 2, a: 2}, {id: 3, a: 3} ]数组去重办法汇总
首先: 我晓得多少种去重形式
1. 双层 for 循环
function distinct(arr) {for (let i=0, len=arr.length; i<len; i++) {for (let j=i+1; j<len; j++) {if (arr[i] == arr[j]) {arr.splice(j, 1);
// splice 会扭转数组长度,所以要将数组长度 len 和下标 j 减一
len--;
j--;
}
}
}
return arr;
}思维: 双重
for循环是比拟蠢笨的办法,它实现的原理很简略:先定义一个蕴含原始数组第一个元素的数组,而后遍历原始数组,将原始数组中的每个元素与新数组中的每个元素进行比对,如果不反复则增加到新数组中,最初返回新数组;因为它的工夫复杂度是O(n^2),如果数组长度很大,效率会很低
2. Array.filter() 加 indexOf/includes
function distinct(a, b) {let arr = a.concat(b);
return arr.filter((item, index)=> {//return arr.indexOf(item) === index
return arr.includes(item)
})
}思维: 利用
indexOf检测元素在数组中第一次呈现的地位是否和元素当初的地位相等,如果不等则阐明该元素是反复元素
3. ES6 中的 Set 去重
function distinct(array) {return Array.from(new Set(array));
}思维: ES6 提供了新的数据结构 Set,Set 构造的一个个性就是成员值都是惟一的,没有反复的值。
4. reduce 实现对象数组去反复
var resources = [{ name: "张三", age: "18"},
{name: "张三", age: "19"},
{name: "张三", age: "20"},
{name: "李四", age: "19"},
{name: "王五", age: "20"},
{name: "赵六", age: "21"}
]
var temp = {};
resources = resources.reduce((prev, curv) => {
// 如果长期对象中有这个名字,什么都不做
if (temp[curv.name]) { }else {
// 如果长期对象没有就把这个名字加进去,同时把以后的这个对象退出到 prev 中
temp[curv.name] = true;
prev.push(curv);
}
return prev
}, []);
console.log("后果", resources);这种办法是利用高阶函数
reduce进行去重,这里只须要留神initialValue得放一个空数组[],不然没法push
实现 reduce 办法
- 初始值不传怎么解决
- 回调函数的参数有哪些,返回值如何解决。
Array.prototype.myReduce = function(fn, initialValue) {var arr = Array.prototype.slice.call(this);
var res, startIndex;
res = initialValue ? initialValue : arr[0]; // 不传默认取数组第一项
startIndex = initialValue ? 0 : 1;
for(var i = startIndex; i < arr.length; i++) {// 把初始值、以后值、索引、以后数组返回去。调用的时候传到函数参数中 [1,2,3,4].reduce((initVal,curr,index,arr))
res = fn.call(null, res, arr[i], i, this);
}
return res;
}二叉树深度遍历
// 二叉树深度遍历
class Node {constructor(element, parent) {
this.parent = parent // 父节点
this.element = element // 以后存储内容
this.left = null // 左子树
this.right = null // 右子树
}
}
class BST {constructor(compare) {
this.root = null // 树根
this.size = 0 // 树中的节点个数
this.compare = compare || this.compare
}
compare(a,b) {return a - b}
add(element) {if(this.root === null) {this.root = new Node(element, null)
this.size++
return
}
// 获取根节点 用以后增加的进行判断 放右边还是放左边
let currentNode = this.root
let compare
let parent = null
while (currentNode) {compare = this.compare(element, currentNode.element)
parent = currentNode // 先将父亲保存起来
// currentNode 要不停的变动
if(compare > 0) {currentNode = currentNode.right} else if(compare < 0) {currentNode = currentNode.left} else {currentNode.element = element // 相等时 先笼罩后续解决}
}
let newNode = new Node(element, parent)
if(compare > 0) {parent.right = newNode} else if(compare < 0) {parent.left = newNode}
this.size++
}
// 前序遍历
preorderTraversal(visitor) {
const traversal = node=>{if(node === null) return
visitor.visit(node.element)
traversal(node.left)
traversal(node.right)
}
traversal(this.root)
}
// 中序遍历
inorderTraversal(visitor) {
const traversal = node=>{if(node === null) return
traversal(node.left)
visitor.visit(node.element)
traversal(node.right)
}
traversal(this.root)
}
// 后序遍历
posterorderTraversal(visitor) {
const traversal = node=>{if(node === null) return
traversal(node.left)
traversal(node.right)
visitor.visit(node.element)
}
traversal(this.root)
}
// 反转二叉树:无论先序、中序、后序、层级都能够反转
invertTree() {
const traversal = node=>{if(node === null) return
let temp = node.left
node.left = node.right
node.right = temp
traversal(node.left)
traversal(node.right)
}
traversal(this.root)
return this.root
}
}先序遍历
二叉树的遍历形式
// 测试
var bst = new BST((a,b)=>a.age-b.age) // 模仿 sort 办法
bst.add({age: 10})
bst.add({age: 8})
bst.add({age:19})
bst.add({age:6})
bst.add({age: 15})
bst.add({age: 22})
bst.add({age: 20})
// 先序遍历
// console.log(bst.preorderTraversal(),'先序遍历')
// console.log(bst.inorderTraversal(),'中序遍历')
// 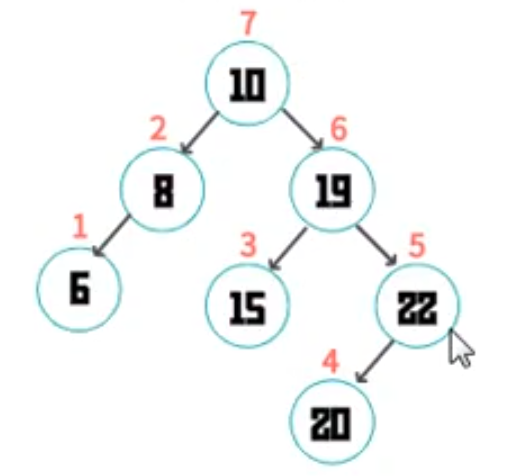
// console.log(bst.posterorderTraversal(),'后序遍历')
// 深度遍历:先序遍历、中序遍历、后续遍历
// 广度遍历:档次遍历(同层级遍历)// 都可拿到树中的节点
// 应用访问者模式
class Visitor {constructor() {this.visit = function (elem) {elem.age = elem.age*2}
}
}
// bst.posterorderTraversal({// visit(elem) {
// elem.age = elem.age*10
// }
// })
// 不能通过索引操作 拿到节点去操作
// bst.posterorderTraversal(new Visitor())
console.log(bst.invertTree(),'反转二叉树')实现有并行限度的 Promise 调度器
题目形容:JS 实现一个带并发限度的异步调度器 Scheduler,保障同时运行的工作最多有两个
addTask(1000,"1");
addTask(500,"2");
addTask(300,"3");
addTask(400,"4");
的输入程序是:2 3 1 4
整个的残缺执行流程:一开始 1、2 两个工作开始执行
500ms 时,2 工作执行结束,输入 2,工作 3 开始执行
800ms 时,3 工作执行结束,输入 3,工作 4 开始执行
1000ms 时,1 工作执行结束,输入 1,此时只剩下 4 工作在执行
1200ms 时,4 工作执行结束,输入 4 实现代码如下:
class Scheduler {constructor(limit) {this.queue = [];
this.maxCount = limit;
this.runCounts = 0;
}
add(time, order) {const promiseCreator = () => {return new Promise((resolve, reject) => {setTimeout(() => {console.log(order);
resolve();}, time);
});
};
this.queue.push(promiseCreator);
}
taskStart() {for (let i = 0; i < this.maxCount; i++) {this.request();
}
}
request() {if (!this.queue || !this.queue.length || this.runCounts >= this.maxCount) {return;}
this.runCounts++;
this.queue
.shift()()
.then(() => {
this.runCounts--;
this.request();});
}
}
const scheduler = new Scheduler(2);
const addTask = (time, order) => {scheduler.add(time, order);
};
addTask(1000, "1");
addTask(500, "2");
addTask(300, "3");
addTask(400, "4");
scheduler.taskStart();树形构造转成列表(解决菜单)
[
{
id: 1,
text: '节点 1',
parentId: 0,
children: [
{
id:2,
text: '节点 1_1',
parentId:1
}
]
}
]
转成
[
{
id: 1,
text: '节点 1',
parentId: 0 // 这里用 0 示意为顶级节点
},
{
id: 2,
text: '节点 1_1',
parentId: 1 // 通过这个字段来确定子父级
}
...
]实现代码如下:
function treeToList(data) {let res = [];
const dfs = (tree) => {tree.forEach((item) => {if (item.children) {dfs(item.children);
delete item.children;
}
res.push(item);
});
};
dfs(data);
return res;
}二叉树搜寻
// 二叉搜寻树
class Node {constructor(element, parent) {
this.parent = parent // 父节点
this.element = element // 以后存储内容
this.left = null // 左子树
this.right = null // 右子树
}
}
class BST {constructor(compare) {
this.root = null // 树根
this.size = 0 // 树中的节点个数
this.compare = compare || this.compare
}
compare(a,b) {return a - b}
add(element) {if(this.root === null) {this.root = new Node(element, null)
this.size++
return
}
// 获取根节点 用以后增加的进行判断 放右边还是放左边
let currentNode = this.root
let compare
let parent = null
while (currentNode) {compare = this.compare(element, currentNode.element)
parent = currentNode // 先将父亲保存起来
// currentNode 要不停的变动
if(compare > 0) {currentNode = currentNode.right} else if(compare < 0) {currentNode = currentNode.left} else {currentNode.element = element // 相等时 先笼罩后续解决}
}
let newNode = new Node(element, parent)
if(compare > 0) {parent.right = newNode} else if(compare < 0) {parent.left = newNode}
this.size++
}
}// 测试
var bst = new BST((a,b)=>b.age-a.age) // 模仿 sort 办法
bst.add({age: 10})
bst.add({age: 8})
bst.add({age:19})
bst.add({age:20})
bst.add({age: 5})
console.log(bst)reduce 用法汇总
语法
array.reduce(function(total, currentValue, currentIndex, arr), initialValue);
/*
total: 必须。初始值, 或者计算完结后的返回值。currentValue:必须。以后元素。currentIndex:可选。以后元素的索引;arr:可选。以后元素所属的数组对象。initialValue: 可选。传递给函数的初始值,相当于 total 的初始值。*/
reduceRight()该办法用法与reduce()其实是雷同的,只是遍历的程序相同,它是从数组的最初一项开始,向前遍历到第一项
1. 数组求和
const arr = [12, 34, 23];
const sum = arr.reduce((total, num) => total + num);
// 设定初始值求和
const arr = [12, 34, 23];
const sum = arr.reduce((total, num) => total + num, 10); // 以 10 为初始值求和
// 对象数组求和
var result = [{ subject: 'math', score: 88},
{subject: 'chinese', score: 95},
{subject: 'english', score: 80}
];
const sum = result.reduce((accumulator, cur) => accumulator + cur.score, 0);
const sum = result.reduce((accumulator, cur) => accumulator + cur.score, -10); // 总分扣除 10 分2. 数组最大值
const a = [23,123,342,12];
const max = a.reduce((pre,next)=>pre>cur?pre:cur,0); // 3423. 数组转对象
var streams = [{name: '技术', id: 1}, {name: '设计', id: 2}];
var obj = streams.reduce((accumulator, cur) => {accumulator[cur.id] = cur; return accumulator;}, {});4. 扁平一个二维数组
var arr = [[1, 2, 8], [3, 4, 9], [5, 6, 10]];
var res = arr.reduce((x, y) => x.concat(y), []);5. 数组去重
实现的基本原理如下:① 初始化一个空数组
② 将须要去重解决的数组中的第 1 项在初始化数组中查找,如果找不到(空数组中必定找不到),就将该项增加到初始化数组中
③ 将须要去重解决的数组中的第 2 项在初始化数组中查找,如果找不到,就将该项持续增加到初始化数组中
④ ……
⑤ 将须要去重解决的数组中的第 n 项在初始化数组中查找,如果找不到,就将该项持续增加到初始化数组中
⑥ 将这个初始化数组返回var newArr = arr.reduce(function (prev, cur) {prev.indexOf(cur) === -1 && prev.push(cur);
return prev;
},[]);6. 对象数组去重
const dedup = (data, getKey = () => {}) => {const dateMap = data.reduce((pre, cur) => {const key = getKey(cur)
if (!pre[key]) {pre[key] = cur
}
return pre
}, {})
return Object.values(dateMap)
}7. 求字符串中字母呈现的次数
const str = 'sfhjasfjgfasjuwqrqadqeiqsajsdaiwqdaklldflas-cmxzmnha';
const res = str.split('').reduce((pre,next)=>{pre[next] ? pre[next]++ : pre[next] = 1
return pre
},{})// 后果
-: 1
a: 8
c: 1
d: 4
e: 1
f: 4
g: 1
h: 2
i: 2
j: 4
k: 1
l: 3
m: 2
n: 1
q: 5
r: 1
s: 6
u: 1
w: 2
x: 1
z: 18. compose 函数
redux compose源码实现
function compose(...funs) {if (funs.length === 0) {return arg => arg;}
if (funs.length === 1) {return funs[0];
}
return funs.reduce((a, b) => (...arg) => a(b(...arg)))
}类数组转化为数组的办法
const arrayLike=document.querySelectorAll('div')
// 1. 扩大运算符
[...arrayLike]
// 2.Array.from
Array.from(arrayLike)
// 3.Array.prototype.slice
Array.prototype.slice.call(arrayLike)
// 4.Array.apply
Array.apply(null, arrayLike)
// 5.Array.prototype.concat
Array.prototype.concat.apply([], arrayLike)对象数组列表转成树形构造(解决菜单)
[
{
id: 1,
text: '节点 1',
parentId: 0 // 这里用 0 示意为顶级节点
},
{
id: 2,
text: '节点 1_1',
parentId: 1 // 通过这个字段来确定子父级
}
...
]
转成
[
{
id: 1,
text: '节点 1',
parentId: 0,
children: [
{
id:2,
text: '节点 1_1',
parentId:1
}
]
}
]实现代码如下:
function listToTree(data) {let temp = {};
let treeData = [];
for (let i = 0; i < data.length; i++) {temp[data[i].id] = data[i];
}
for (let i in temp) {if (+temp[i].parentId != 0) {if (!temp[temp[i].parentId].children) {temp[temp[i].parentId].children = [];}
temp[temp[i].parentId].children.push(temp[i]);
} else {treeData.push(temp[i]);
}
}
return treeData;
}实现 findIndex 办法
var users = [{id: 1, name: '张三'},
{id: 2, name: '张三'},
{id: 3, name: '张三'},
{id: 4, name: '张三'}
]
Array.prototype.myFindIndex = function (callback) {// var callback = function (item, index) {return item.id === 4}
for (var i = 0; i < this.length; i++) {if (callback(this[i], i)) {
// 这里返回
return i
}
}
}
var ret = users.myFind(function (item, index) {return item.id === 2})
console.log(ret)