## Redis内存模型
### Redis内存调配
- 数据 :Redis存储的数据对象 字符串、哈希、列表、汇合、有序汇合
- 过程自身所需内存 : Redis过程本人运行所须要的内存,比方代码,占用内存,常量池等
- 缓存内存:
+ 客户端缓冲区 : 连贯客户端输入输出的缓存
+ 复制积压缓冲区: 在主从同步时,非全量复制时,所须要的缓存区
+ 复制积压缓冲区: AOF写入时的缓存
- 内存碎片:内存碎片是Redis在调配、回收物理内存过程中产生的
### Redis内存分配器 (jemalloc)
+ jemalloc 将空间分为 小(Small)、大(Large)、微小(Huge)三种

### Redis内存统计
- used_memory (Redis内存分配器调配的内存)
> 存储的数据的内存
- used_memory_rss (Redis占操作系统的内存)
> 包含存储的数据内存还有内存碎片以及Redis自身占用内存
### Redis数据的存储过程
- RedisObject
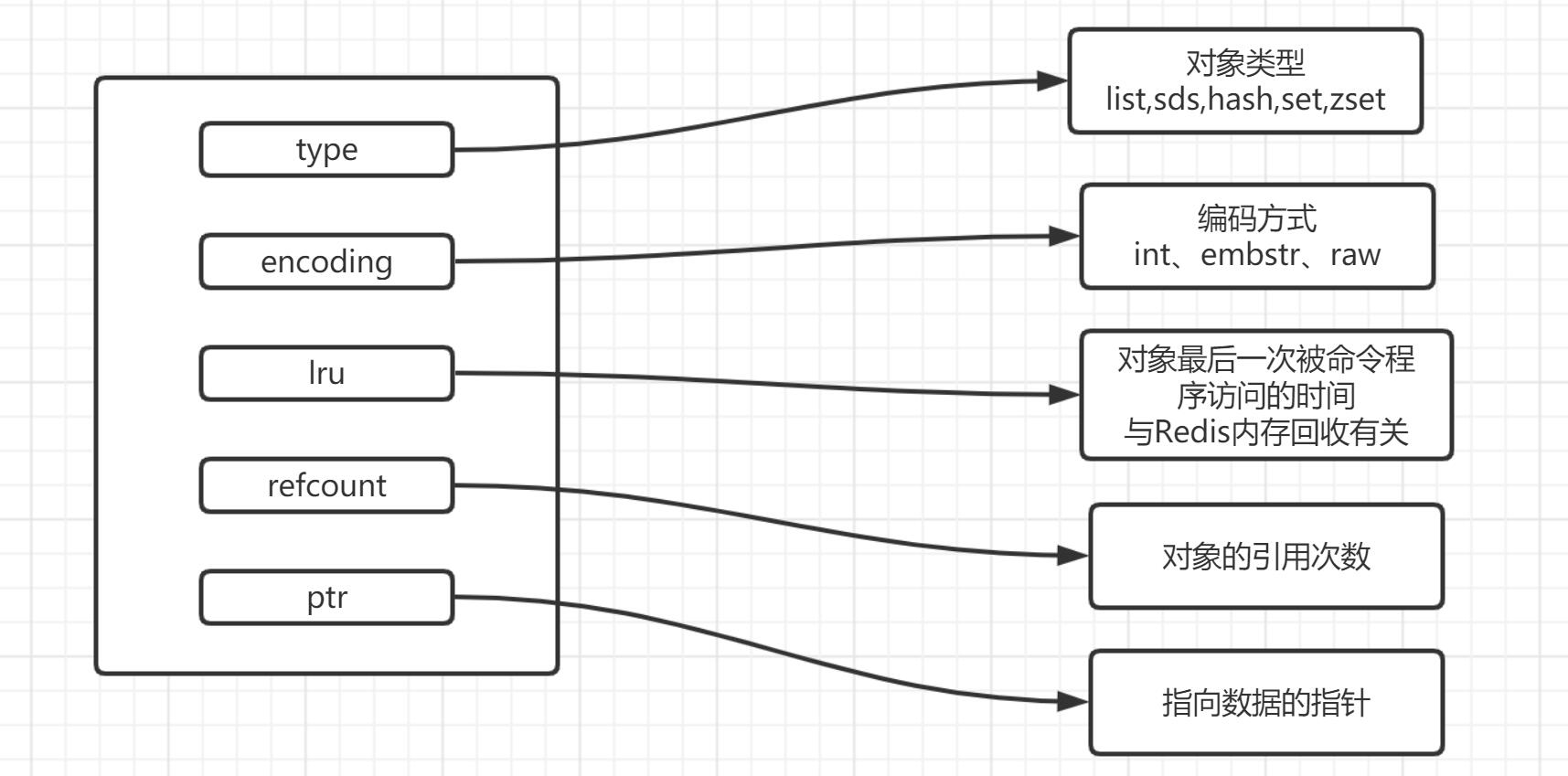
- 数据类型
+ SDS
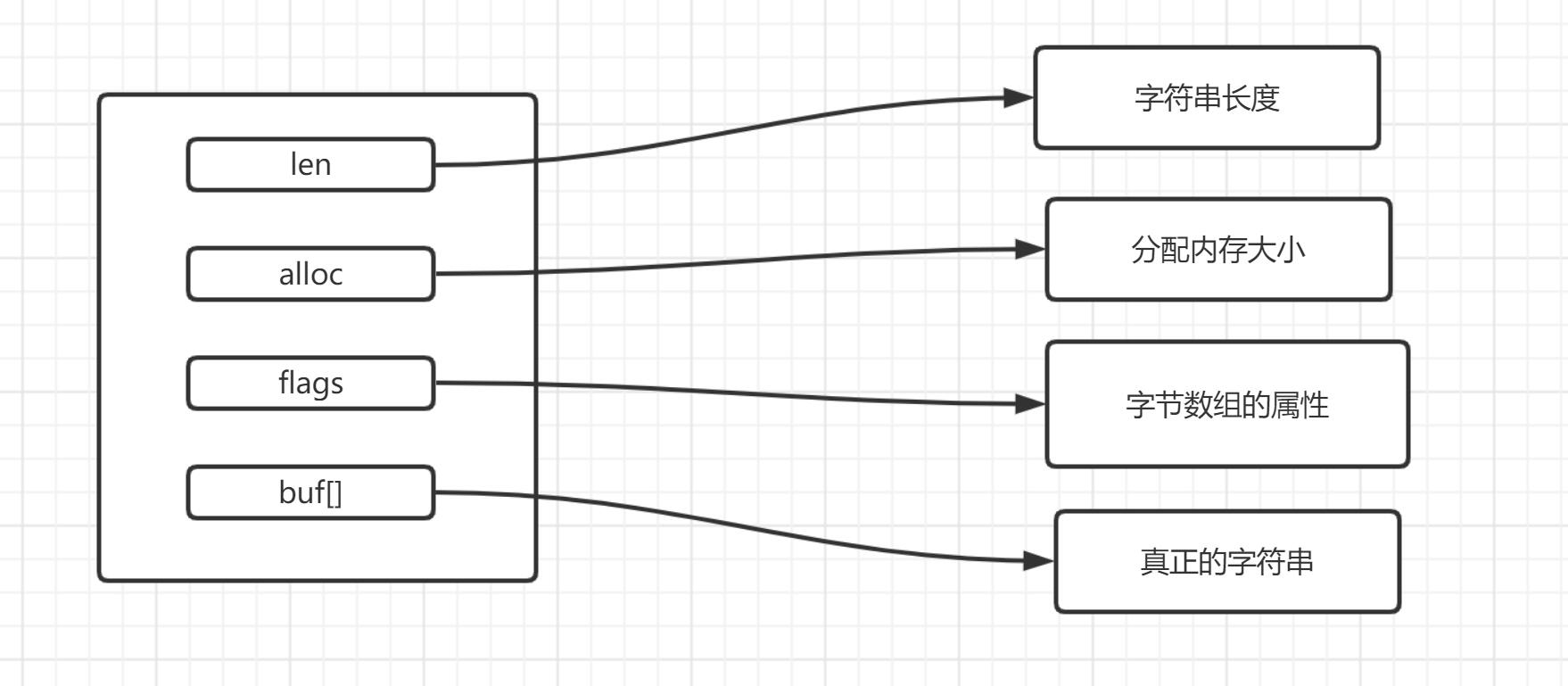
- 空间预调配
sdscat =》给字符串前面再拼接一个字符串
当sdscat 之后内存小于 1M,字符串长度*2+1 (’\0’)
当sdscat 之后内存大于 1M, 字符串长度 + 1M + 1(’\0’)
- 空间懒调配
如果sdstrim(缩小字符串),则不急着回收空间,下次如果须要增加长度,间接应用多余的空间。
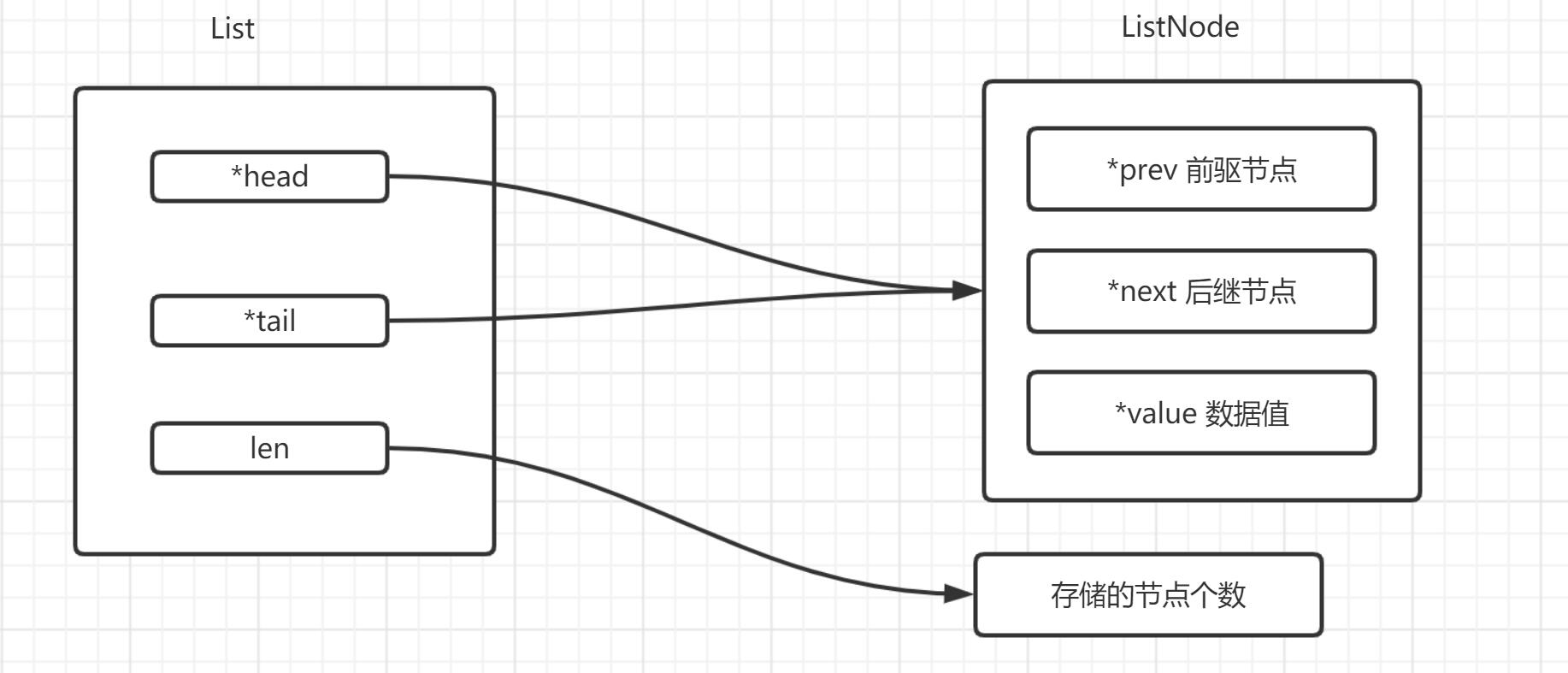
+ List
+ Hash
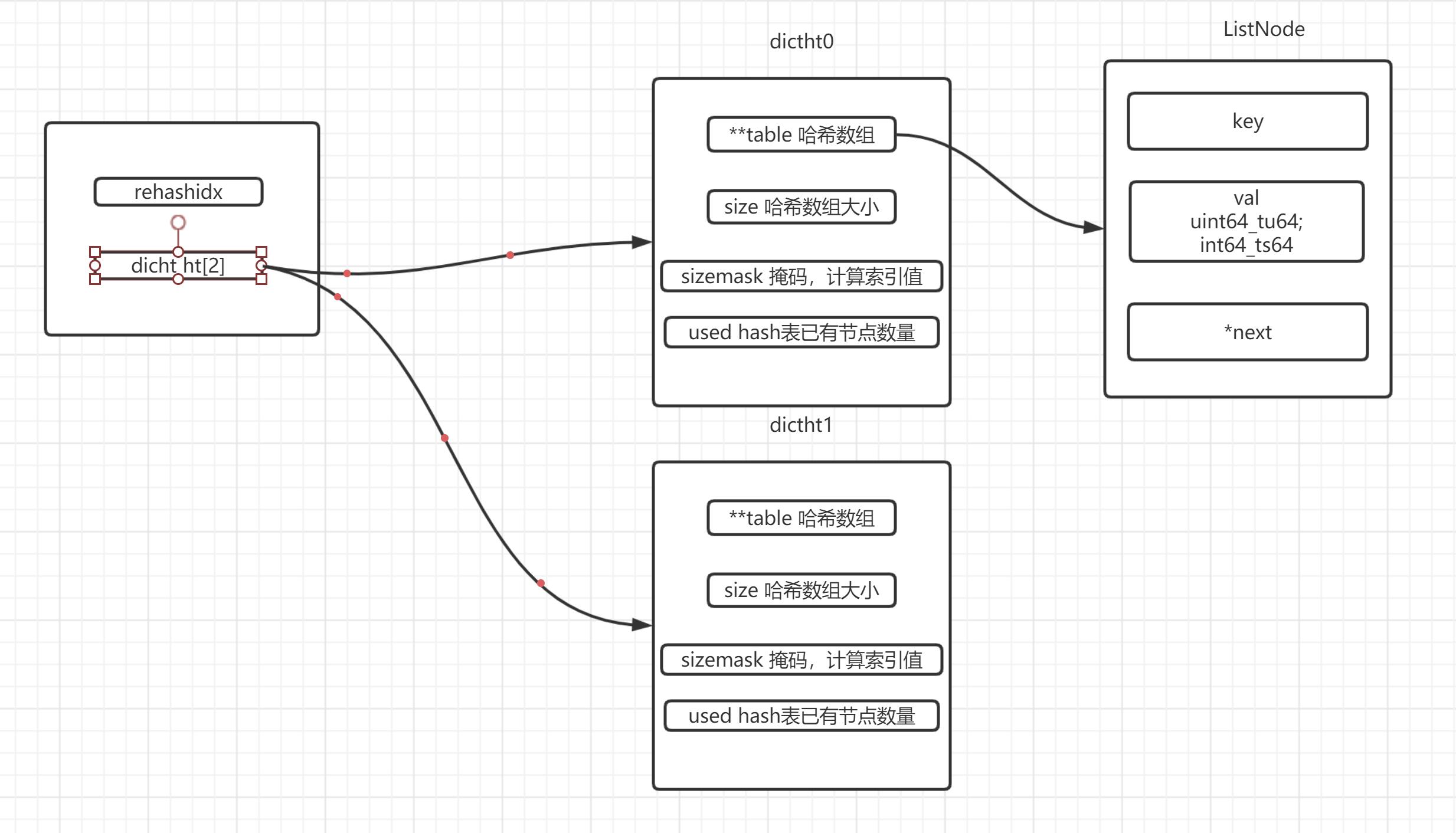
在字典中存在dictht数组,表明是两个hash表
ht[1]的容量是ht[0]的两倍
把ht[0]中的元素rehash复制到ht[1]中
+ set
+ zset
- 数据存储过程
> RedisObject -> 具体的数据类型
### Redis内存回收策略
+ noeviction:返回谬误当内存限度达到并且客户端尝试执行会让更多内存被应用的命令(大部分的写入指令,但DEL和几个例外)
+ allkeys-lru:尝试回收起码应用的键(LRU) ,使得新增加的数据有空间寄存。
+ volatile-lru:尝试回收起码应用的键(LRU) ,但仅限于在过期汇合的键,使得新增加的数据有空间寄存。
+ allkeys-random:回收随机的键使得新增加的数据有空间寄存。
+ volatile-random:回收随机的键使得新增加的数据有空间寄存,但仅限于在过期汇合的键。
+ volatile-ttl:回收在过期汇合的键,并且优先回收存活工夫(TTL) 较短的键,使得新增加的数据有空间寄存。
## Redis的原子性保障
+ 单指令原子性
> Redis是单线程的,一个线程只能执行一个指令,因而具备原子性
+ Lua原子性
> 官网解释来看,Lua脚本和Redis的事务一样,被exec/mutl包裹,redis保障每次只能执行一个lua脚本,别的lua脚本不会被执行,由此保障了原子性。
## 分布式锁
### 次要命令
+ setnx 不存在key才能够操作
+ set 与set相同
### 锁续期
> 利用**Redission**,当胜利获取一个锁的时候,产生看门狗(watch dog)进行锁续期,一般来说是10s查看一次
> 外围在于Redission应用了Lua脚本
### 分布式锁的极其状况
> 当服务A从Master中获取锁,A获取锁胜利后,还没来得及同步到从节点,master挂了,从节点
从新成为master,服务B过去后,发现该锁还未被获取,于是锁被反复获取
## Redis的冷备和热备
+ 热备 - AOF
- 数据文件比RDB更大
- 每秒都去长久化,数据失落少
- 存储的文件是每条的指令
- 先执行命令,之后才存储到磁盘(因为redis不是齐全保护,只有执行当前才晓得后果,单纯的语法监测是无用的)
- bgrewriteaof 能够对aof的日志文件进行瘦身,也就是fork一个子过程把原来的日志全副转化成redis命令存到一个新的日志中执行
+ 冷备 - RDB
- 须要fork子过程,数据量大的话会导致几秒的提早,对于秒杀场景危险
- 是段时间保留数据,一旦产生宕机,数据失落较多
- RDB复原的更快
## Redis集群
### 哨兵监控
+ 主观下线
> 从节点无奈ping通master,则主观认为master挂了
+ 主观下线(主节点的下线)
> 多个从节点都无奈ping通master,则从节点们主观认为master挂了,**须要从新选举**
+ 定时工作
+ 谬误转移
- 过滤不衰弱的节点
- 选举出新的节点
- 让从节点成为主节点
- 让原来的master成为从节点
+ 哨兵选举
> Raft : 谁先申请成为主节点,谁就是主节点
## 主从同步的过程
1. 从节点向master发送slaveof获取主节点的信息
+ 定时工作获取主节点信息
+ 从节点去ping主节点,主节点则返回pang和runid等信息
2. 从节点依据保留的Master runid判断是不是第一次同步复制
3. 如果是第一次psync?-1,则进行全量复制
+ 全量复制址启用用RDB生成快照
- 启动RDB会fork子过程,则子过程运行期间,新命令进入到缓存区
+ RDB生成到磁盘,之后在读取到内存,再进行数据同步
- 快照内容同步完当前,再将缓存的命令缓存到从节点
4. 如果不是第一次,则进行局部复制,从节点向master发送Psync runid offset
5. Master收到命令后会查看,runid是否统一,之后查看偏移量offset是否超过复制积压缓存区
+ 如果偏移量超过复制积压缓存区,则err,进行全量复制
+ 如果未超过,则offset+偏移量+命令长度进行局部复制
### 复制积压缓存区
> 在主从同步的期间,依然会有写命令在执行,这时命令在写入主节点的同时还会写入**复制积压缓存区**,同时记录偏移量,如果这期间缓存的命令过多,则没必要再进行局部复制,间接进行全量复制即可
## 缓存的常见问题
1. 缓存穿透
+ 歹意拜访不存在的数据,导致打入数据库
+ 减少认证(接口拜访性能)
2. 缓存击穿
+ 某热点数据忽然生效,打入数据库
+ 设置null值
3. 缓存雪崩
+ 大量数据同时生效
+ 设置随机工夫种子
## redis中的 HyperLogLog
### 场景剖析
> 拜访网站的独立访客UV,例如每个访客拜访某网站,拜访屡次,其实只能算作一次。
> 那么带来的间接问题是,如果每个用户都占用一个key,那么就会产生数据量微小的问题
### 解决方案拆分
+ 借鉴数据库的b+树
> 解决了插入和查找的问题,然而解决不了数据量大,占用内存的问题
+ bitmap
> 如果是一亿个数据,那么100_000_000(数据量)/ 8(字节)/ 1024(KB)/ 1024(MB) ≈ 12 M
### 概率统计
> 能够看到bitmap曾经是属于极致的优化了,然而还是不够,不管怎么说,为了一个统计性能,单一个对象就是12M,然而再多一些还是会很多
> 则应用 “预计的办法可能会好一些”,则应用 **概率统计**
#### redis的实现
HLL中理论存储的是一个长度为mm的大数组SS,将待统计的数据汇合划分成mm组,每组依据算法记录一个统计值存入数组中。数组的大小mm由算法实现方本人确定,redis中这个数组的大小是16834(2的14次方),m越大,基数统计的误差越小,但须要的内存空间也越大

#### hll的实现原理 - 伯努利试验
+ 伯努利实现也就是掷硬币实现,那么咱们说假如存在第一次掷出侧面所用的最多的次数为kmax,则能够提出假如
+ 假如:
- 掷出n次侧面所用的次数肯定少于n*kmax
- 掷出n次侧面所用的次数肯定有那么一次是等于kmax的(其实正好是1减去下面的概率)

+ 推断:
- 那么当n远大于kmax的时候,那么第一个不成立
- 那么当n远小于kmax的时候,那么第二个不成立
+ 持续推断
- 那么用kmax推断n的次数貌似是最好的状况
则 n = 2^kmax
+ 持续思考
- 如果很大的一段二进制,只用一个kmax误差比拟大
- 那么把一段很大的离开预计就好了,因而有**分桶原理**,也就是redis过程中对应的数组S的m
### 稠密存储和密集存储
1. 密集存储就是依照原来16834来存储
2. 稠密存储就是间断两个0作为统计接下来的 6bit 整数值加 1
### hll对象头struct hllhdr {
char magic[4]; /* 魔术字符串"HYLL" */
uint8_t encoding; /* 存储类型 HLL_DENSE or HLL_SPARSE. */
uint8_t notused[3]; /* 保留三个字节将来可能会应用 */
uint8_t card[8]; /* 总计数缓存 */
uint8_t registers[]; /* 所有桶的计数器 */};
## 订阅与公布
### PubSub
#### 毛病
+ 没有ack确认信息,不能保证数据间断
+ 不长久化音讯
#### PubSub
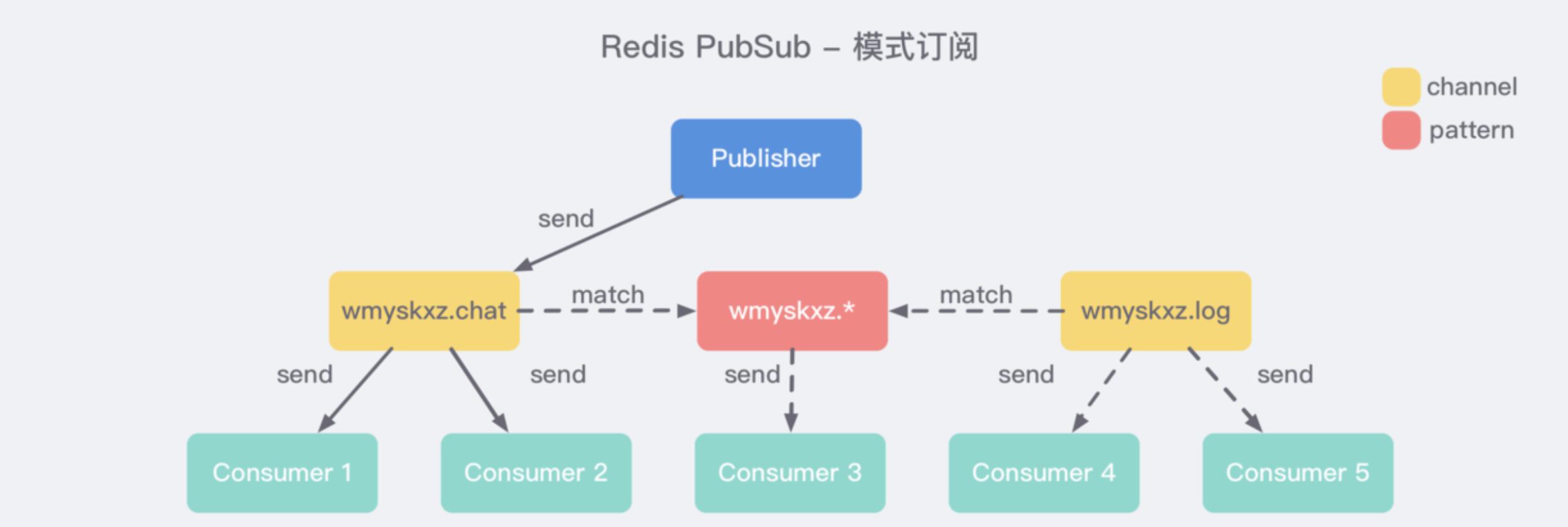
+ 准确匹配
> 订阅某个准确频道,则须要准确的晓得这个频道的key值,才能够订阅,比方client订阅redis频道
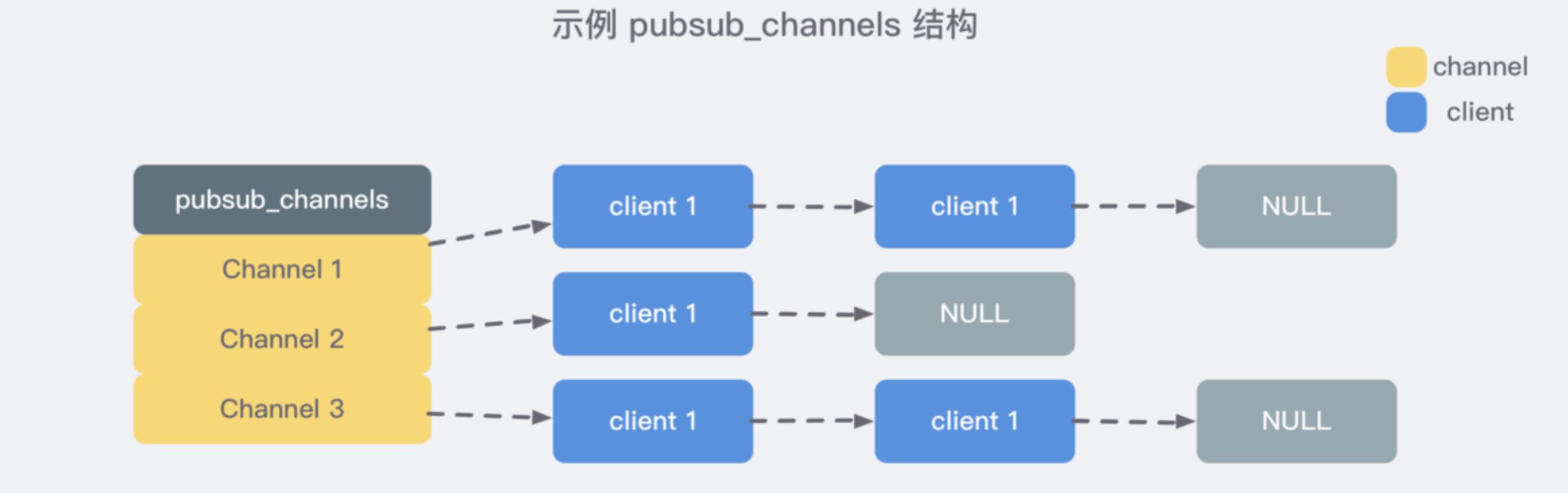
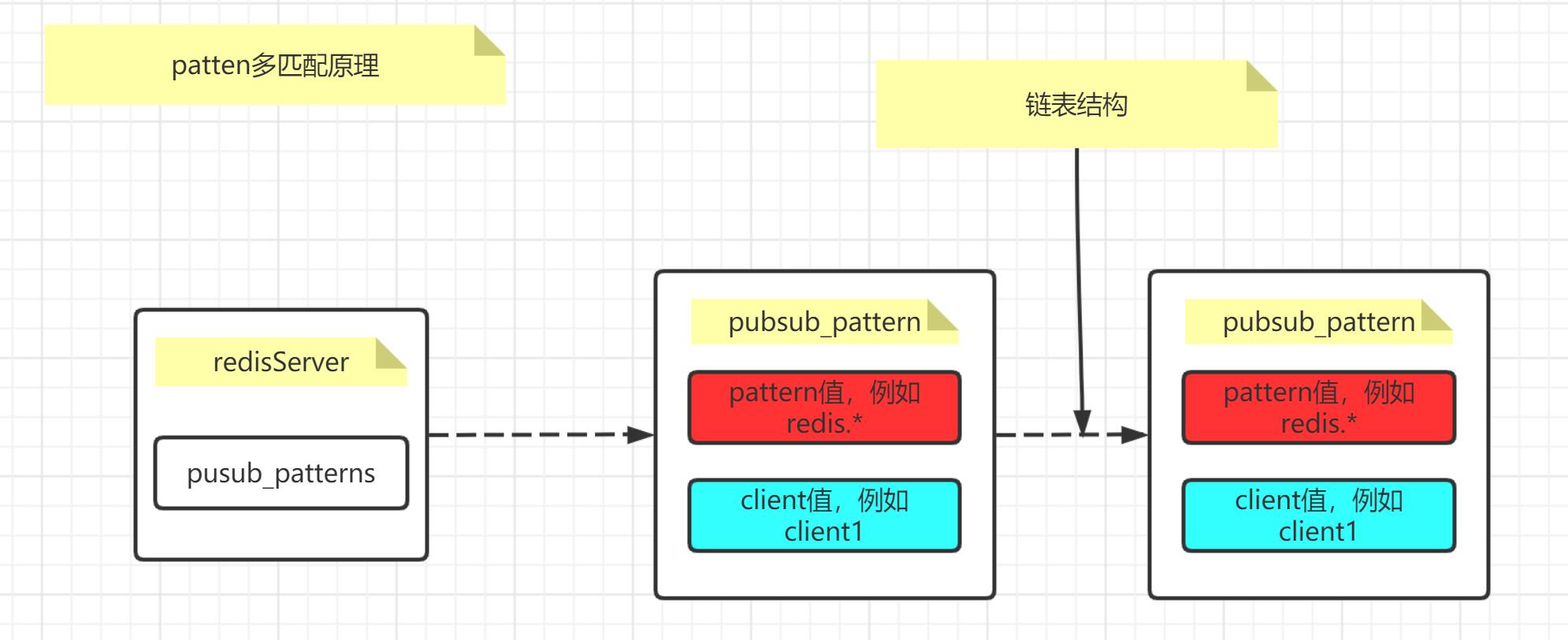
+ 前缀多匹配
> 订阅某种类型的全副频道,也就是说晓得某频道类型的前缀,则能够订阅该类型下的全副频道,例如**client订阅redis.*的频道**,
> 则会**订阅redis.log,redis.rdb等一系列合乎redis.*的一系列前缀频道**
#### steam
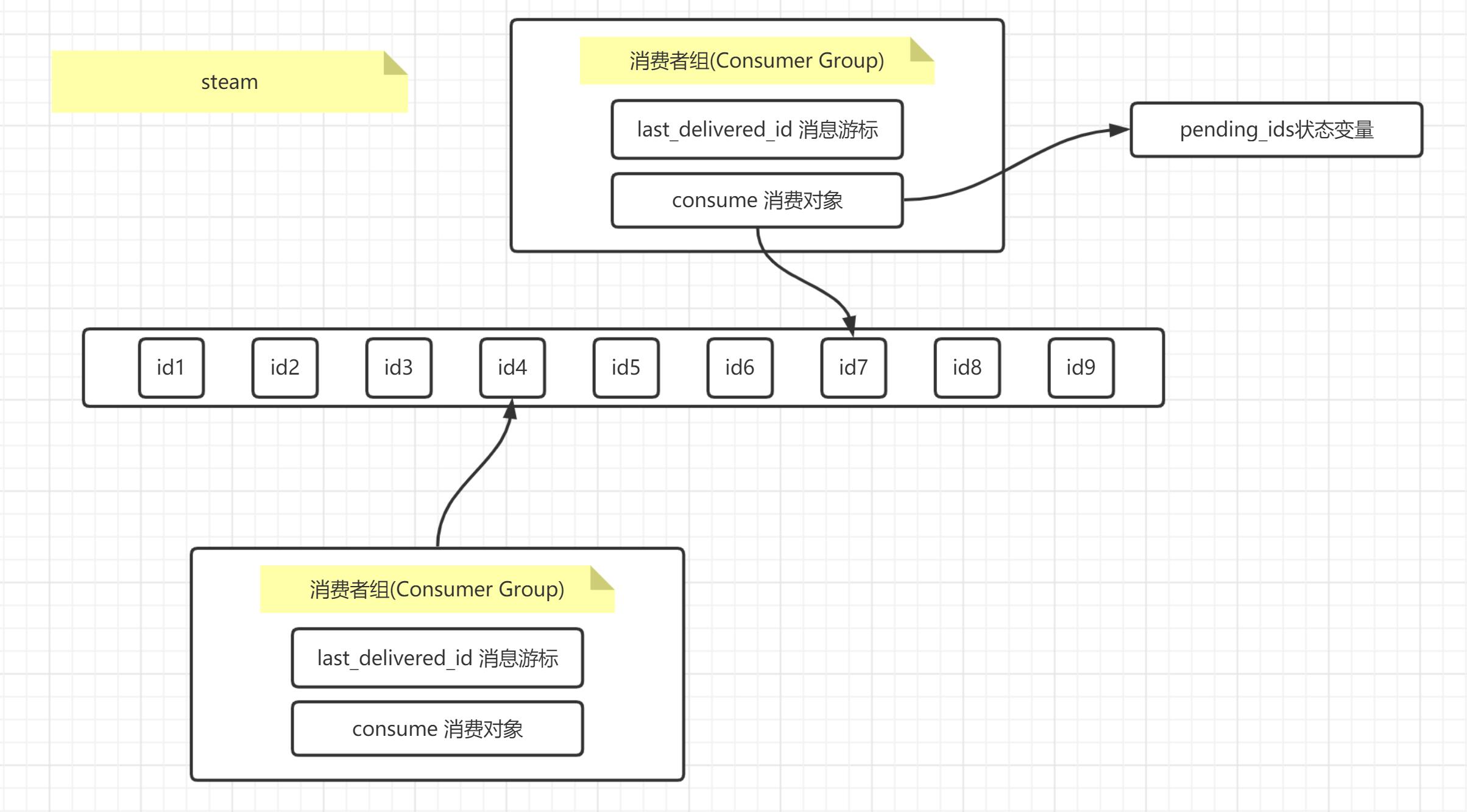
+ Consumer Group:消费者组
> 多个consumer须要某音讯的一个群组
+ last_delivered_id:音讯游标
> 群组须要哪个音讯,则指向这个音讯的id,音讯 ID 如果是由 XADD 命令返回主动创立的话,那么它的格局会像这样:timestampInMillis-sequence (毫秒工夫戳-序列号),例如 1527846880585-5,它示意以后的音讯是在毫秒工夫戳 1527846880585 时产生的,并且是该毫秒内产生的第 5 条音讯。
+ pending_ids:状态数组
> 记录未确认ack的音讯的数组,如果客户端发送ack则数组中的内容缩小,如果不发送则会始终减少
发表回复