当客户端 App 主过程创立 WKWebView 对象时,会创立另外两个子过程: 渲染过程与网络过程。主过程 WKWebView 发动申请时,先将申请转发给渲染过程,渲染过程再转发给网络过程,网络过程申请服务器。如果申请的是一个网页,网络过程会将服务器的响应数据 HTML 文件字符流吐给渲染过程。渲染过程拿到 HTML 文件字符流,首先要进行解析,将 HTML 文件字符流转换成 DOM 树,而后在 DOM 树的根底上,进行渲染操作,也就是布局、绘制。最初渲染过程告诉主过程 WKWebView 创立对应的 View 展示视图。整个流程如下图所示:
一、什么是 DOM 树
渲染过程获取到 HTML 文件字符流,会将 HTML 文件字符流转换成 DOM 树。下图中左侧是一个 HTML 文件,左边就是转换而成的 DOM 树。
能够看到 DOM 树的根节点是 HTMLDocument,代表整个文档。根节点上面的子节点与 HTML 文件中的标签是一一对应的,比方 HTML 中的 <head> 标签就对应 DOM 树中的 head 节点。同时 HTML 文件中的文本,也成为 DOM 树中的一个节点,比方文本 ‘Hello, World!’,在 DOM 树中就成为 div 节点的子节点。
在 DOM 树中每一个节点都是具备肯定办法与属性的对象,这些对象由对应的类创立进去。比方 HTMLDocument 节点,它对应的类是 class HTMLDocument,上面是 HTMLDocument 的局部源码:
class HTMLDocument : public Document { // 继承自 Document
...
WEBCORE_EXPORT int width();
WEBCORE_EXPORT int height();
...
}从源码中能够看到,HTMLDocument 继承自类 Document,Document 类的局部源码如下:
class Document
: public ContainerNode // Document 继承自 ContainerNode,ContainerNode 继承自 Node
, public TreeScope
, public ScriptExecutionContext
, public FontSelectorClient
, public FrameDestructionObserver
, public Supplementable<Document>
, public Logger::Observer
, public CanvasObserver {WEBCORE_EXPORT ExceptionOr<Ref<Element>> createElementForBindings(const AtomString& tagName); // 创立 Element 的办法
WEBCORE_EXPORT Ref<Text> createTextNode(const String& data); // 创立文本节点的办法
WEBCORE_EXPORT Ref<Comment> createComment(const String& data); // 创立正文的办法
WEBCORE_EXPORT Ref<Element> createElement(const QualifiedName&, bool createdByParser); // 创立 Element 办法
....
}下面源码能够看到 Document 继承自 Node,而且还能够看到前端非常相熟的 createElement、createTextNode 等办法,JavaScript 对这些办法的调用,最初都转换为对应 C++ 办法的调用。
类 Document 有这些办法,并不是没有起因的,而是 W3C 组织给出的标准规定的,这个规范就是 DOM(Document Object Model,文档对象模型)。DOM 定义了 DOM 树中每个节点须要实现的接口和属性,上面是 HTMLDocument、Document、HTMLDivElement 的局部 IDL(Interactive Data Language,接口描述语言,与具体平台和语言无关) 形容,残缺的 IDL 能够参看 W3C。
在 DOM 树中,每一个节点都继承自类 Node,同时 Node 还有一个子类 Element,有的节点间接继承自类 Node,比方文本节点,而有的节点继承自类 Element,比方 div 节点。因而针对下面图中的 DOM 树,执行上面的 JavaScript 语句返回的后果是不一样的:
document.childNodes; // 返回子 Node 汇合,返回 DocumentType 与 HTML 节点,都继承自 Node
document.children; // 返回子 Element 汇合,只返回 HTML 节点,DocumentType 不继承自 Element下图给出局部节点的继承关系图:
二、DOM 树构建
DOM 树的构建流程能够分为 4 个步骤: 解码、分词、创立节点、增加节点 。
2.1 解码
渲染过程从网络过程接管过去的是 HTML 字节流,而下一步分词是以字符为单位进行的。因为各种编码标准的存在,比方 ISO-8859-1、UTF-8 等,一个字符经常可能对应一个或者多个编码后的字节,解码的目标就是将 HTML 字节流转换成 HTML 字符流,或者换句话说,就是将原始的 HTML 字节流转换成字符串。
2.1.1 解码类图
从类图上看,类 HTMLDocumentParser 处于解码的外围地位,由这个类调用解码器将 HTML 字节流解码成字符流,存储到类 HTMLInputStream 中。
2.1.2 解码流程
整个解码流程当中,最关健的是如何找到正确的编码方式。只有找到了正确的编码方式,能力应用对应的解码器进行解码。解码产生的中央如上面源代码所示,这个办法在上图第 3 个栈帧被调用:
// HTMLDocumentParser 是 DecodedDataDocumentParser 的子类
void DecodedDataDocumentParser::appendBytes(DocumentWriter& writer, const uint8_t* data, size_t length)
{if (!length)
return;
String decoded = writer.decoder().decode(data, length); // 真正解码产生在这里
if (decoded.isEmpty())
return;
writer.reportDataReceived();
append(decoded.releaseImpl());
}下面代码第 7 行 writer.decoder() 返回一个 TextResourceDecoder 对象,解码操作由 TextResourceDecoder::decode 办法实现。上面逐渐查看 TextResourceDecoder::decode 办法的源码:
// 只保留了最重要的局部
String TextResourceDecoder::decode(const char* data, size_t length)
{
...
// 如果是 HTML 文件,就从 head 标签中寻找字符集
if ((m_contentType == HTML || m_contentType == XML) && !m_checkedForHeadCharset) // HTML and XML
if (!checkForHeadCharset(data, length, movedDataToBuffer))
return emptyString();
...
// m_encoding 存储者从 HTML 文件中找到的编码名称
if (!m_codec)
m_codec = newTextCodec(m_encoding); // 创立具体的编码器
...
// 解码并返回
String result = m_codec->decode(m_buffer.data() + lengthOfBOM, m_buffer.size() - lengthOfBOM, false, m_contentType == XML && !m_useLenientXMLDecoding, m_sawError);
m_buffer.clear(); // 清空存储的原始未解码的 HTML 字节流
return result;
}从源码中能够看到,TextResourceDecoder 首先从 HTML 的 <head> 标签中去找编码方式,因为 <head> 标签能够蕴含 <meta> 标签,<meta> 标签能够设置 HTML 文件的字符集:
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <!-- 字符集指定 -->
<title>DOM Tree</title>
<script>window.name = 'Lucy';</script>
</head>如果能找到对应的字符集,TextResourceDeocder 将其存储在成员变量 m\_encoding 当中,并且依据对应的编码创立真正的解码器存储在成员变量 m\_codec 中,最终应用 m\_codec 对字节流进行解码,并且返回解码后的字符串。如果带有字符集的 <meta> 标签没有找到,TextResourceDeocder 的 m\_encoding 有默认值 windows-1252(等同于 ISO-8859-1)。
上面看一下 TextResourceDecoder 寻找 <meta> 标签中字符集的流程,也就是下面源码中第 8 行对 checkForHeadCharset 函数的调用:
// 只保留了关健代码
bool TextResourceDecoder::checkForHeadCharset(const char* data, size_t len, bool& movedDataToBuffer)
{
...
// This is not completely efficient, since the function might go
// through the HTML head several times.
size_t oldSize = m_buffer.size();
m_buffer.grow(oldSize + len);
memcpy(m_buffer.data() + oldSize, data, len); // 将字节流数据拷贝到本人的缓存 m_buffer 外面
movedDataToBuffer = true;
// Continue with checking for an HTML meta tag if we were already doing so.
if (m_charsetParser)
return checkForMetaCharset(data, len); // 如果曾经存在了 meta 标签解析器,间接开始解析
....
m_charsetParser = makeUnique<HTMLMetaCharsetParser>(); // 创立 meta 标签解析器
return checkForMetaCharset(data, len);
}下面源代码中第 11 行,类 TextResourceDecoder 外部存储了须要解码的 HTML 字节流,这一步骤很重要,前面会讲到。先看第 17 行、21 行、22 行,这 3 行次要是应用 <meta> 标签解析器解析字符集,应用了懒加载的形式。上面看下 checkForMetaCharset 这个函数的实现:
bool TextResourceDecoder::checkForMetaCharset(const char* data, size_t length)
{if (!m_charsetParser->checkForMetaCharset(data, length)) // 解析 meta 标签字符集
return false;
setEncoding(m_charsetParser->encoding(), EncodingFromMetaTag); // 找到后设置字符编码名称
m_charsetParser = nullptr;
m_checkedForHeadCharset = true;
return true;
}下面源码第 3 行能够看到,整个解析 <meta> 标签的工作在类 HTMLMetaCharsetParser::checkForMetaCharset 中实现。
// 只保留了关健代码
bool HTMLMetaCharsetParser::checkForMetaCharset(const char* data, size_t length)
{if (m_doneChecking) // 标记位,防止反复解析
return true;
// We still don't have an encoding, and are in the head.
// The following tags are allowed in <head>:
// SCRIPT|STYLE|META|LINK|OBJECT|TITLE|BASE
//
// We stop scanning when a tag that is not permitted in <head>
// is seen, rather when </head> is seen, because that more closely
// matches behavior in other browsers; more details in
// <http://bugs.webkit.org/show_bug.cgi?id=3590>.
//
// Additionally, we ignore things that looks like tags in <title>, <script>
// and <noscript>; see <http://bugs.webkit.org/show_bug.cgi?id=4560>,
// <http://bugs.webkit.org/show_bug.cgi?id=12165> and
// <http://bugs.webkit.org/show_bug.cgi?id=12389>.
//
// Since many sites have charset declarations after <body> or other tags
// that are disallowed in <head>, we don't bail out until we've checked at
// least bytesToCheckUnconditionally bytes of input.
constexpr int bytesToCheckUnconditionally = 1024; // 如果解析了 1024 个字符还未找到带有字符集的 <meta> 标签,整个解析也算实现,此时没有解析到正确的字符集,就应用默认编码 windows-1252(等同于 ISO-8859-1)
bool ignoredSawErrorFlag;
m_input.append(m_codec->decode(data, length, false, false, ignoredSawErrorFlag)); // 对字节流进行解码
while (auto token = m_tokenizer.nextToken(m_input)) { // m_tokenizer 进行分词操作,找 meta 标签也须要进行分词,分词操作前面讲
bool isEnd = token->type() == HTMLToken::EndTag;
if (isEnd || token->type() == HTMLToken::StartTag) {AtomString tagName(token->name());
if (!isEnd) {m_tokenizer.updateStateFor(tagName);
if (tagName == metaTag && processMeta(*token)) { // 找到 meta 标签进行解决
m_doneChecking = true;
return true; // 如果找到了带有编码的 meta 标签,间接返回
}
}
if (tagName != scriptTag && tagName != noscriptTag
&& tagName != styleTag && tagName != linkTag
&& tagName != metaTag && tagName != objectTag
&& tagName != titleTag && tagName != baseTag
&& (isEnd || tagName != htmlTag)
&& (isEnd || tagName != headTag)) {m_inHeadSection = false;}
}
if (!m_inHeadSection && m_input.numberOfCharactersConsumed() >= bytesToCheckUnconditionally) { // 如果分词曾经进入了 <body> 标签范畴,同时分词数量曾经超过了 1024,也算胜利
m_doneChecking = true;
return true;
}
}
return false;
}下面源码第 29 行,类 HTMLMetaCharsetParser 也有一个解码器 m\_codec,解码器是在 HTMLMetaCharsetParser 对象创立时生成,这个解码器的实在类型是 TextCodecLatin1(Latin1 编码也就是 ISO-8859-1,等同于 windows-1252 编码)。之所以能够间接应用 TextCodecLatin1 解码器,是因为 <meta> 标签如果设置正确,都是英文字符,齐全能够应用 TextCodecLatin1 进行解析进去。这样就防止了为了找到 <meta> 标签,须要对字节流进行解码,而要解码就必须要找到 <meta> 标签这种鸡生蛋、蛋生鸡的问题。
代码第 37 行对找到的 <meta> 标签进行解决,这个函数比较简单,次要是解析 <meta> 标签当中的属性,而后查看这些属性名中有没有 charset。
bool HTMLMetaCharsetParser::processMeta(HTMLToken& token)
{
AttributeList attributes;
for (auto& attribute : token.attributes()) { // 获取 meta 标签属性
String attributeName = StringImpl::create8BitIfPossible(attribute.name);
String attributeValue = StringImpl::create8BitIfPossible(attribute.value);
attributes.append(std::make_pair(attributeName, attributeValue));
}
m_encoding = encodingFromMetaAttributes(attributes); // 从属性中找字符集设置属性 charset
return m_encoding.isValid();}下面剖析 TextResourceDecoder::checkForHeadCharset 函数时,讲过第 11 行 TextResourceDecoder 类存储 HTML 字节流的操作很重要。起因是可能整个 HTML 字节流外面可能的确没有设置 charset 的 <meta> 标签,此时 TextResourceDecoder::checkForHeadCharset 函数就要返回 false,导致 TextResourceDecoder::decode 函数返回空字符串,也就是不进行任何解码。是不是这样呢?实在的状况是,在接管 HTML 字节流整个过程中因为的确没有找到带有 charset 属性的 <meta> 标签,那么整个接管期间都不会解码。然而残缺的 HTML 字节流会被存储在 TextResourceDecoder 的成员变量 m\_buffer 外面,当整个 HTML 字节流接管完结的时,会有如下调用栈:
从调用栈能够看到,当 HTML 字节流接管实现,最终会调用 TextResourceDecoder::flush 办法,这个办法会将 TextResourceDecoder 中有 m\_buffer 存储的 HTML 字节流进行解码,因为在接管 HTML 字节流期间未胜利找到编码方式,因而 m\_buffer 外面存储的就是所有待解码的 HTML 字节流,而后在这里应用默认的编码 windows-1252 对全副字节流进行解码。因而,如果 HTML 字节流中蕴含汉字,那么如果不指定字符集,最终页面就会呈现乱码。解码实现后,会将解码之后的字符流存储到 HTMLDocumentParser 中。
void DecodedDataDocumentParser::flush(DocumentWriter& writer)
{String remainingData = writer.decoder().flush();
if (remainingData.isEmpty())
return;
writer.reportDataReceived();
append(remainingData.releaseImpl()); // 解码后的字符流存储到 HTMLDocumentParser
}2.1.3 解码总结
整个解码过程能够分为两种情景: 第一种情景是 HTML 字节流能够解析出带有 charset 属性的 <meta> 标签,这样就能够获取相应的编码方式,那么每接管到一个 HML 字节流,都能够应用相应的编码方式进行解码,将解码后的字符流增加到 HTMLInputStream 当中;第二种是 HTML 字节流不能解析带有 charset 属性的 <meta> 标签,这样每接管到一个 HTML 字节流,都缓存到 TextResourceDecoder 的 m\_buffer 缓存,等残缺的 HTML 字节流接管结束,就会应用默认的编码 windows-1252 进行解码。
2.2 分词
接管到的 HTML 字节流通过解码,成为存储在 HTMLInputStream 中的字符流。分词的过程就是从 HTMLInputStream 中顺次取出每一个字符,而后判断字符是否是非凡的 HTML 字符 ’ <‘、’/’、’>’、’=’ 等。依据这些特殊字符的宰割,就能解析出 HTML 标签名以及属性列表,类 HTMLToken 就是存储分词进去的后果。
2.2.1 分词类图
从类图中能够看到,分词最重要的是类 HTMLTokenizer 和类 HTMLToken。上面是类 HTMLToken 的次要信息:
// 只保留了次要信息
class HTMLToken {
public:
enum Type { // Token 的类型
Uninitialized, // Token 初始化时的类型
DOCTYPE, // 代表 Token 是 DOCType 标签
StartTag, // 代表 Token 是一个开始标签
EndTag, // 代表 Token 是一个完结标签
Comment, // 代表 Token 是一个正文
Character, // 代表 Token 是文本
EndOfFile, // 代表 Token 是文件结尾
};
struct Attribute { // 存储属性的数据结构
Vector<UChar, 32> name; // 属性名
Vector<UChar, 64> value; // 属性值
// Used by HTMLSourceTracker.
unsigned startOffset;
unsigned endOffset;
};
typedef Vector<Attribute, 10> AttributeList; // 属性列表
typedef Vector<UChar, 256> DataVector; // 存储 Token 名
...
private:
Type m_type;
DataVector m_data;
// For StartTag and EndTag
bool m_selfClosing; // Token 是注入 <img> 一样自完结标签
AttributeList m_attributes;
Attribute* m_currentAttribute; // 以后正在解析的属性
};2.2.2 分词流程
下面分词流程中 HTMLDocumentParser::pumpTokenizerLoop 办法是最重要的,从办法名字能够看出这个办法外面蕴含循环逻辑:
// 只保留关健代码
bool HTMLDocumentParser::pumpTokenizerLoop(SynchronousMode mode, bool parsingFragment, PumpSession& session)
{
do { // 分词循环体开始
...
if (UNLIKELY(mode == AllowYield && m_parserScheduler->shouldYieldBeforeToken(session))) // 防止长时间处于分词循环中,这里依据条件临时退出循环
return true;
if (!parsingFragment)
m_sourceTracker.startToken(m_input.current(), m_tokenizer);
auto token = m_tokenizer.nextToken(m_input.current()); // 进行分词操作,取出一个 token
if (!token)
return false; // 分词没有产生 token,就跳出循环
if (!parsingFragment)
m_sourceTracker.endToken(m_input.current(), m_tokenizer);
constructTreeFromHTMLToken(token); // 依据 token 构建 DOM 树
} while (!isStopped());
return false;
}下面代码中第 7 行会有一个 yield 退出操作,这是为了防止长时间处于分词循环,占用主线程。当退出条件为真时,会从分词循环中返回,返回值为 true。上面是退出判断代码:
// 只保留关健代码
bool HTMLParserScheduler::shouldYieldBeforeToken(PumpSession& session)
{
...
// numberOfTokensBeforeCheckingForYield 是动态变量,定义为 4096
// session.processedTokensOnLastCheck 示意从上一次退出为止,以及解决过的 token 个数
// session.didSeeScript 示意在分词过程中是否呈现过 script 标签
if (UNLIKELY(session.processedTokens > session.processedTokensOnLastCheck + numberOfTokensBeforeCheckingForYield || session.didSeeScript))
return checkForYield(session);
++session.processedTokens;
return false;
}
bool HTMLParserScheduler::checkForYield(PumpSession& session)
{
session.processedTokensOnLastCheck = session.processedTokens;
session.didSeeScript = false;
Seconds elapsedTime = MonotonicTime::now() - session.startTime;
return elapsedTime > m_parserTimeLimit; // m_parserTimeLimit 的值默认是 500ms,从分词开始超过 500ms 就要先 yield
}如果命中了下面的 yield 退出条件,那么什么时候再次进入分词呢?上面的代码展现了再次进入分词的过程:
// 保留要害代码
void HTMLDocumentParser::pumpTokenizer(SynchronousMode mode)
{
...
if (shouldResume) // 从 pumpTokenizerLoop 中 yield 退出时返回值为 true
m_parserScheduler->scheduleForResume();}
void HTMLParserScheduler::scheduleForResume()
{ASSERT(!m_suspended);
m_continueNextChunkTimer.startOneShot(0_s); // 触发 timer(0s 后触发),触发后的响应函数为 HTMLParserScheduler::continueNextChunkTimerFired
}
// 保留关健代码
void HTMLParserScheduler::continueNextChunkTimerFired()
{
...
m_parser.resumeParsingAfterYield(); // 从新 Resume 分词过程}
void HTMLDocumentParser::resumeParsingAfterYield()
{
// pumpTokenizer can cause this parser to be detached from the Document,
// but we need to ensure it isn't deleted yet.
Ref<HTMLDocumentParser> protectedThis(*this);
// We should never be here unless we can pump immediately.
// Call pumpTokenizer() directly so that ASSERTS will fire if we're wrong.
pumpTokenizer(AllowYield); // 从新进入分词过程,该函数会调用 pumpTokenizerLoop
endIfDelayed();}从下面代码能够看出,再次进入分词过程是通过触发一个 Timer 来实现的,尽管这个 Timer 在 0s 后触发,然而并不意味着 Timer 的响应函数会立即执行。如果在此之前主线程曾经有其余工作达到了执行机会,会有被执行的机会。
持续看 HTMLDocumentParser::pumpTokenizerLoop 函数的第 13 行,这一行进行分词操作,从解码后的字符流中分出一个 token。实现分词的代码位于 HTMLTokenizer::processToken:
// 只保留要害代码
bool HTMLTokenizer::processToken(SegmentedString& source)
{
...
if (!m_preprocessor.peek(source, isNullCharacterSkippingState(m_state))) // 取出 source 外部指向的字符,赋给 m_nextInputCharacter
return haveBufferedCharacterToken();
UChar character = m_preprocessor.nextInputCharacter(); // 获取 character
// https://html.spec.whatwg.org/#tokenization
switch (m_state) { // 进行状态转换,m_state 初始值为 DataState
...
}
return false;
}这个办法因为外部要做很多状态转换,总共有 1200 多行,前面会有 4 个例子来解释状态转换的逻辑。
首先来看 InputStreamPreprocessor::peek 办法:
// Returns whether we succeeded in peeking at the next character.
// The only way we can fail to peek is if there are no more
// characters in |source| (after collapsing \r\n, etc).
ALWAYS_INLINE bool InputStreamPreprocessor::peek(SegmentedString& source, bool skipNullCharacters = false)
{if (UNLIKELY(source.isEmpty()))
return false;
m_nextInputCharacter = source.currentCharacter(); // 获取字符流 source 外部指向的以后字符
// Every branch in this function is expensive, so we have a
// fast-reject branch for characters that don't require special
// handling. Please run the parser benchmark whenever you touch
// this function. It's very hot.
constexpr UChar specialCharacterMask = '\n' | '\r' | '\0';
if (LIKELY(m_nextInputCharacter & ~specialCharacterMask)) {
m_skipNextNewLine = false;
return true;
}
return processNextInputCharacter(source, skipNullCharacters); // 跳过空字符,将 \r\n 换行符合并成 \n
}
bool InputStreamPreprocessor::processNextInputCharacter(SegmentedString& source, bool skipNullCharacters)
{
ProcessAgain:
ASSERT(m_nextInputCharacter == source.currentCharacter());
// 针对 \r\n 换行符,上面 if 语句解决 \r 字符并且设置 m_skipNextNewLine=true,前面解决 \n 就间接疏忽
if (m_nextInputCharacter == '\n' && m_skipNextNewLine) {
m_skipNextNewLine = false;
source.advancePastNewline(); // 向前挪动字符
if (source.isEmpty())
return false;
m_nextInputCharacter = source.currentCharacter();}
// 如果是 \r\n 间断的换行符,那么第一次遇到 \r 字符,将 \r 字符替换成 \n 字符,同时设置标记 m_skipNextNewLine=true
if (m_nextInputCharacter == '\r') {
m_nextInputCharacter = '\n';
m_skipNextNewLine = true;
return true;
}
m_skipNextNewLine = false;
if (m_nextInputCharacter || isAtEndOfFile(source))
return true;
// 跳过空字符
if (skipNullCharacters && !m_tokenizer.neverSkipNullCharacters()) {source.advancePastNonNewline();
if (source.isEmpty())
return false;
m_nextInputCharacter = source.currentCharacter();
goto ProcessAgain; // 跳转到结尾
}
m_nextInputCharacter = replacementCharacter;
return true;
}因为 peek 办法会跳过空字符,同时合并 \r\n 字符为 \n 字符,所以一个字符流 source 如果蕴含了空格或者 \r\n 换行符,实际上解决起来如下图所示:
HTMLTokenizer::processToken 外部定义了一个状态机,上面以四种情景来进行解释。
Case1:标签
BEGIN_STATE(DataState) // 刚开始解析是 DataState 状态 if (character == '&') ADVANCE_PAST_NON_NEWLINE_TO(CharacterReferenceInDataState);if (character == '<') {// 整个字符流一开始是 '<',那么示意是一个标签的开始 if (haveBufferedCharacterToken()) RETURN_IN_CURRENT_STATE(true); ADVANCE_PAST_NON_NEWLINE_TO(TagOpenState); // 跳转到 TagOpenState 状态,并取去下一个字符是 '!" }if (character == kEndOfFileMarker)return emitEndOfFile(source); bufferCharacter(character); ADVANCE_TO(DataState);END_STATE()// ADVANCE_PAST_NON_NEWLINE_TO 定义 #define ADVANCE_PAST_NON_NEWLINE_TO(newState) \do {\if (!m_preprocessor.advancePastNonNewline(source, isNullCharacterSkippingState(newState))) {\ // 如果往下挪动取不到下一个字符 m_state = newState; \ // 保留状态 return haveBufferedCharacterToken(); \ // 返回 } \ character = m_preprocessor.nextInputCharacter(); \ // 先取出下一个字符 goto newState; \ // 跳转到指定状态} while (false)BEGIN_STATE(TagOpenState)if (character == '!') // 满足此条件 ADVANCE_PAST_NON_NEWLINE_TO(MarkupDeclarationOpenState); // 同理,跳转到 MarkupDeclarationOpenState 状态,并且取出下一个字符 'D'if (character == '/') ADVANCE_PAST_NON_NEWLINE_TO(EndTagOpenState);if (isASCIIAlpha(character)) {m_token.beginStartTag(convertASCIIAlphaToLower(character)); ADVANCE_PAST_NON_NEWLINE_TO(TagNameState); }if (character == '?') {parseError();// The spec consumes the current character before switching// to the bogus comment state, but it's easier to implement// if we reconsume the current character. RECONSUME_IN(BogusCommentState); } parseError(); bufferASCIICharacter('<'); RECONSUME_IN(DataState);END_STATE()BEGIN_STATE(MarkupDeclarationOpenState)if (character =='-') {auto result = source.advancePast("--");if (result == SegmentedString::DidMatch) {m_token.beginComment(); SWITCH_TO(CommentStartState); }if (result == SegmentedString::NotEnoughCharacters) RETURN_IN_CURRENT_STATE(haveBufferedCharacterToken()); } else if (isASCIIAlphaCaselessEqual(character,'d')) {// 因为 character =='D',满足此条件 auto result = source.advancePastLettersIgnoringASCIICase("doctype"); // 看解码后的字符流中是否有残缺的"doctype"if (result == SegmentedString::DidMatch) SWITCH_TO(DOCTYPEState); // 如果匹配,则跳转到 DOCTYPEState,同时取出以后指向的字符,因为下面 source 字符流曾经挪动了"doctype",因而此时取出的字符为'>'if (result == SegmentedString::NotEnoughCharacters) // 如果不匹配 RETURN_IN_CURRENT_STATE(haveBufferedCharacterToken()); // 保留状态,间接返回 } else if (character =='['&& shouldAllowCDATA()) {auto result = source.advancePast("[CDATA[");if (result == SegmentedString::DidMatch) SWITCH_TO(CDATASectionState);if (result == SegmentedString::NotEnoughCharacters) RETURN_IN_CURRENT_STATE(haveBufferedCharacterToken()); } parseError(); RECONSUME_IN(BogusCommentState);END_STATE()#define SWITCH_TO(newState) \do {\if (!m_preprocessor.peek(source, isNullCharacterSkippingState(newState))) {\ m_state = newState; \return haveBufferedCharacterToken(); \ } \ character = m_preprocessor.nextInputCharacter(); \ // 取出下一个字符 goto newState; \ // 跳转到指定的 state} while (false)#define RETURN_IN_CURRENT_STATE(expression) \do {\ m_state = currentState; \ // 保留以后状态 return expression; \} while (false)BEGIN_STATE(DOCTYPEState)if (isTokenizerWhitespace(character)) ADVANCE_TO(BeforeDOCTYPENameState);if (character == kEndOfFileMarker) {parseError(); m_token.beginDOCTYPE(); m_token.setForceQuirks();return emitAndReconsumeInDataState();} parseError(); RECONSUME_IN(BeforeDOCTYPENameState);END_STATE()#define RECONSUME_IN(newState) \do {\ // 间接跳转到指定 state goto newState; \} while (false) BEGIN_STATE(BeforeDOCTYPENameState)if (isTokenizerWhitespace(character)) ADVANCE_TO(BeforeDOCTYPENameState);if (character =='>') {// character =='>',匹配此处,到此 DOCTYPE 标签匹配结束 parseError(); m_token.beginDOCTYPE(); m_token.setForceQuirks();return emitAndResumeInDataState(source); }if (character == kEndOfFileMarker) {parseError(); m_token.beginDOCTYPE(); m_token.setForceQuirks();return emitAndReconsumeInDataState();} m_token.beginDOCTYPE(toASCIILower(character)); ADVANCE_PAST_NON_NEWLINE_TO(DOCTYPENameState);END_STATE()inline bool HTMLTokenizer::emitAndResumeInDataState(SegmentedString& source){saveEndTagNameIfNeeded(); m_state = DataState; // 重置状态为初始状态 DataState source.advancePastNonNewline(); // 挪动到下一个字符 return true;}DOCTYPE Token 经验了 6 个状态最终被解析进去,整个过程如下图所示:
当 Token 解析结束之后,分词状态又被重置为 DataState,同时须要留神的时,此时字符流 source 外部指向的是下一个字符 ‘<‘。
下面代码第 61 行在用字符流 source 匹配字符串 “doctype” 时,可能呈现匹配不上的情景。为什么会这样呢?这是因为整个 DOM 树的构建流程,并不是先要解码实现,解码实现之后获取到残缺的字符流才进行分词。从后面解码能够晓得,解码可能是一边接管字节流,一边进行解码的,因而分词也是这样,只有能解码出一段字符流,就会立刻进行分词。整个流程会呈现如下图所示:
因为这个起因,用来分词的字符流可能是不残缺的。对于呈现不残缺情景的 DOCTYPE 分词过程如下图所示:
下面介绍了解码、分词、解码、分词解决 DOCTYPE 标签的情景,能够看到从逻辑上这种情景与残缺解码再分词是一样的。后续介绍时都会只针对残缺解码再分词的情景,对于一边解码一边分词的情景,只须要正确的意识 source 字符流外部指针的挪动,并不难剖析。
Case2:标签
<html> 标签的分词过程和 <!DOCTYPE> 相似,其相干代码如下:
BEGIN_STATE(TagOpenState)
if (character == '!')
ADVANCE_PAST_NON_NEWLINE_TO(MarkupDeclarationOpenState);
if (character == '/')
ADVANCE_PAST_NON_NEWLINE_TO(EndTagOpenState);
if (isASCIIAlpha(character)) { // 在开标签状态下,以后字符为 'h'
m_token.beginStartTag(convertASCIIAlphaToLower(character)); // 将 'h' 增加到 Token 名中
ADVANCE_PAST_NON_NEWLINE_TO(TagNameState); // 跳转到 TagNameState,并挪动到下一个字符 't'
}
if (character == '?') {parseError();
// The spec consumes the current character before switching
// to the bogus comment state, but it's easier to implement
// if we reconsume the current character.
RECONSUME_IN(BogusCommentState);
}
parseError();
bufferASCIICharacter('<');
RECONSUME_IN(DataState);
END_STATE()
BEGIN_STATE(TagNameState)
if (isTokenizerWhitespace(character))
ADVANCE_TO(BeforeAttributeNameState);
if (character == '/')
ADVANCE_PAST_NON_NEWLINE_TO(SelfClosingStartTagState);
if (character == '>') // 在这个状态下遇到起始标签终止字符
return emitAndResumeInDataState(source); // 以后分词完结,重置分词状态为 DataState
if (m_options.usePreHTML5ParserQuirks && character == '<')
return emitAndReconsumeInDataState();
if (character == kEndOfFileMarker) {parseError();
RECONSUME_IN(DataState);
}
m_token.appendToName(toASCIILower(character)); // 将以后字符增加到 Token 名
ADVANCE_PAST_NON_NEWLINE_TO(TagNameState); // 持续跳转到以后状态,并挪动到下一个字符
END_STATE()
Case3:带有属性的标签 <div>
HTML 标签能够带有属性,属性由属性名和属性值组成,属性之间以及属性与标签名之间用空格分隔:
<!-- div 标签有两个属性,属性名为 class 和 align,它们的值都带有引号 -->
<div class="news" align="center">Hello,World!</div>
<!-- 属性值也能够不带引号 -->
<div class=news align=center>Hello,World!</div>整个 <div> 标签的解析中,标签名 div 的解析流程和下面的 <html> 标签解析一样,当在解析标签名的过程中,碰到了空白字符,阐明要开始解析属性了,上面是相干代码:
BEGIN_STATE(TagNameState)if (isTokenizerWhitespace(character)) // 在解析 TagName 时遇到空白字符,标记属性开始 ADVANCE_TO(BeforeAttributeNameState);if (character == '/') ADVANCE_PAST_NON_NEWLINE_TO(SelfClosingStartTagState);if (character == '>')return emitAndResumeInDataState(source);if (m_options.usePreHTML5ParserQuirks && character == '<')return emitAndReconsumeInDataState();if (character == kEndOfFileMarker) {parseError(); RECONSUME_IN(DataState); } m_token.appendToName(toASCIILower(character)); ADVANCE_PAST_NON_NEWLINE_TO(TagNameState);END_STATE()#define ADVANCE_TO(newState) \do {\if (!m_preprocessor.advance(source, isNullCharacterSkippingState(newState))) {\ // 挪动到下一个字符 m_state = newState; \return haveBufferedCharacterToken(); \ } \ character = m_preprocessor.nextInputCharacter(); \ goto newState; \ // 跳转到指定状态} while (false)BEGIN_STATE(BeforeAttributeNameState)if (isTokenizerWhitespace(character)) // 如果标签名后有间断空格,那么就不停的跳过,在以后状态不停循环 ADVANCE_TO(BeforeAttributeNameState);if (character == '/') ADVANCE_PAST_NON_NEWLINE_TO(SelfClosingStartTagState);if (character == '>')return emitAndResumeInDataState(source);if (m_options.usePreHTML5ParserQuirks && character == '<')return emitAndReconsumeInDataState();if (character == kEndOfFileMarker) {parseError(); RECONSUME_IN(DataState); }if (character == '"'|| character =='\''|| character =='<'|| character =='=') parseError(); m_token.beginAttribute(source.numberOfCharactersConsumed()); // Token 的属性列表减少一个,用来寄存新的属性名与属性值 m_token.appendToAttributeName(toASCIILower(character)); // 增加属性名 ADVANCE_PAST_NON_NEWLINE_TO(AttributeNameState); // 跳转到 AttributeNameState,并且挪动到下一个字符 END_STATE()BEGIN_STATE(AttributeNameState)if (isTokenizerWhitespace(character)) ADVANCE_TO(AfterAttributeNameState);if (character =='/') ADVANCE_PAST_NON_NEWLINE_TO(SelfClosingStartTagState);if (character =='=') ADVANCE_PAST_NON_NEWLINE_TO(BeforeAttributeValueState); // 在解析属性名的过程中如果碰到 =,阐明属性名完结,属性值就要开始 if (character =='>')return emitAndResumeInDataState(source);if (m_options.usePreHTML5ParserQuirks && character =='<')return emitAndReconsumeInDataState();if (character == kEndOfFileMarker) {parseError(); RECONSUME_IN(DataState); }if (character =='"' || character == '\'' || character == '<' || character == '=') parseError(); m_token.appendToAttributeName(toASCIILower(character)); ADVANCE_PAST_NON_NEWLINE_TO(AttributeNameState);END_STATE()BEGIN_STATE(BeforeAttributeValueState)if (isTokenizerWhitespace(character)) ADVANCE_TO(BeforeAttributeValueState);if (character == '"') ADVANCE_PAST_NON_NEWLINE_TO(AttributeValueDoubleQuotedState); // 有的属性值有引号突围,这里跳转到 AttributeValueDoubleQuotedState,并挪动到下一个字符 if (character =='&') RECONSUME_IN(AttributeValueUnquotedState);if (character =='\'') ADVANCE_PAST_NON_NEWLINE_TO(AttributeValueSingleQuotedState);if (character =='>') {parseError();return emitAndResumeInDataState(source); }if (character == kEndOfFileMarker) {parseError(); RECONSUME_IN(DataState); }if (character =='<'|| character =='='|| character =='`') parseError(); m_token.appendToAttributeValue(character); // 有的属性值没有引号突围,增加属性值字符到 Token ADVANCE_PAST_NON_NEWLINE_TO(AttributeValueUnquotedState); // 跳转到 AttributeValueUnquotedState,并挪动到下一个字符 END_STATE()BEGIN_STATE(AttributeValueDoubleQuotedState)if (character =='"') {// 在以后状态下如果遇到引号,阐明属性值完结 m_token.endAttribute(source.numberOfCharactersConsumed()); // 完结属性解析 ADVANCE_PAST_NON_NEWLINE_TO(AfterAttributeValueQuotedState); // 跳转到 AfterAttributeValueQuotedState,并挪动到下一个字符 }if (character == '&') {m_additionalAllowedCharacter = '"'; ADVANCE_PAST_NON_NEWLINE_TO(CharacterReferenceInAttributeValueState); }if (character == kEndOfFileMarker) {parseError(); m_token.endAttribute(source.numberOfCharactersConsumed()); RECONSUME_IN(DataState); } m_token.appendToAttributeValue(character); // 将属性值字符增加到 Token ADVANCE_TO(AttributeValueDoubleQuotedState); // 跳转到以后状态 END_STATE()BEGIN_STATE(AfterAttributeValueQuotedState)if (isTokenizerWhitespace(character)) ADVANCE_TO(BeforeAttributeNameState); // 属性值解析结束,如果前面持续跟着空白字符,阐明后续还有属性要解析,调回到 BeforeAttributeNameStateif (character =='/') ADVANCE_PAST_NON_NEWLINE_TO(SelfClosingStartTagState);if (character =='>')return emitAndResumeInDataState(source); // 属性值解析结束,如果遇到'>'字符,阐明整个标签也要解析结束了,此时完结以后标签解析,并且重置分词状态为 DataState,并挪动到下一个字符 if (m_options.usePreHTML5ParserQuirks && character =='<')return emitAndReconsumeInDataState();if (character == kEndOfFileMarker) {parseError(); RECONSUME_IN(DataState); } parseError(); RECONSUME_IN(BeforeAttributeNameState);END_STATE()BEGIN_STATE(AttributeValueUnquotedState)if (isTokenizerWhitespace(character)) {// 当解析不带引号的属性值时遇到空白字符 ( 这与带引号的属性值不一样,带引号的属性值能够蕴含空白字符),阐明以后属性解析结束,前面还有其余属性,跳转到 BeforeAttributeNameState,并且挪动到下一个字符 m_token.endAttribute(source.numberOfCharactersConsumed()); ADVANCE_TO(BeforeAttributeNameState); }if (character =='&') {m_additionalAllowedCharacter ='>'; ADVANCE_PAST_NON_NEWLINE_TO(CharacterReferenceInAttributeValueState); }if (character =='>') {// 解析过程中如果遇到'>'字符,阐明整个标签也要解析结束了,此时完结以后标签解析,并且重置分词状态为 DataState,并挪动到下一个字符 m_token.endAttribute(source.numberOfCharactersConsumed());return emitAndResumeInDataState(source); }if (character == kEndOfFileMarker) {parseError(); m_token.endAttribute(source.numberOfCharactersConsumed()); RECONSUME_IN(DataState); }if (character =='"' || character == '\'' || character == '<' || character == '=' || character == '`') parseError(); m_token.appendToAttributeValue(character); // 将遇到的属性值字符增加到 Token ADVANCE_PAST_NON_NEWLINE_TO(AttributeValueUnquotedState); // 跳转到以后状态,并且挪动到下一个字符 END_STATE()从代码中能够看到,当属性值带引号和不带引号时,解析的逻辑是不一样的。当属性值带有引号时,属性值外面是能够蕴含空白字符的。如果属性值不带引号,那么一旦碰到空白字符,阐明这个属性就解析完结了,会进入下一个属性的解析当中。
Case4:纯文本解析
这里的纯文本指起始标签与完结标签之间的任何纯文字,包含脚本文、CSS 文本等等,如下所示:
<!-- div 标签中的纯文本 Hello,Word! -->
<div class=news align=center>Hello,World!</div>
<!-- script 标签中的纯文本 window.name = 'Lucy'; -->
<script>window.name = 'Lucy';</script>纯文本的解析过程比较简单,就是不停的在 DataState 状态上跳转,缓存遇到的字符,直到遇见一个完结标签的 ‘<‘ 字符,相干代码如下:
BEGIN_STATE(DataState)
if (character == '&')
ADVANCE_PAST_NON_NEWLINE_TO(CharacterReferenceInDataState);
if (character == '<') { // 如果在解析文本的过程中遇到开标签,分两种状况
if (haveBufferedCharacterToken()) // 第一种,如果缓存了文本字符就间接按以后 DataState 返回,并不挪动字符,所以下次再进入分词操作时取到的字符仍为 '<'
RETURN_IN_CURRENT_STATE(true);
ADVANCE_PAST_NON_NEWLINE_TO(TagOpenState); // 第二种,如果没有缓存任何文本字符,间接进入 TagOpenState 状态,进入到起始标签解析过程,并且挪动下一个字符
}
if (character == kEndOfFileMarker)
return emitEndOfFile(source);
bufferCharacter(character); // 缓存遇到的字符
ADVANCE_TO(DataState); // 循环跳转到以后 DataState 状态,并且挪动到下一个字符
END_STATE()因为流程比较简单,上面只给出解析 div 标签中纯文本的后果:
2.3 创立节点与增加节点
2.3.1 相干类图
2.3.2 创立、增加流程
下面的分词循环中,每分出一个 Token,就会依据 Token 创立对应的 Node,而后将 Node 增加到 DOM 树上 (HTMLDocumentParser::pumpTokenizerLoop 办法在下面分词中有介绍)。
下面办法中首先看 HTMLTreeBuilder::constructTree,代码如下:
// 只保留关健代码
void HTMLTreeBuilder::constructTree(AtomHTMLToken&& token)
{
...
if (shouldProcessTokenInForeignContent(token))
processTokenInForeignContent(WTFMove(token));
else
processToken(WTFMove(token)); // HTMLToken 在这里被解决
...
m_tree.executeQueuedTasks(); // HTMLContructionSiteTask 在这里被执行,有时候也间接在创立的过程中间接执行,而后这个办法发现队列为空就会间接返回
// The tree builder might have been destroyed as an indirect result of executing the queued tasks.
}
void HTMLConstructionSite::executeQueuedTasks()
{if (m_taskQueue.isEmpty()) // 队列为空,就间接返回
return;
// Copy the task queue into a local variable in case executeTask
// re-enters the parser.
TaskQueue queue = WTFMove(m_taskQueue);
for (auto& task : queue) // 这里的 task 就是 HTMLContructionSiteTask
executeTask(task); // 执行 task
// We might be detached now.
}下面代码中 HTMLTreeBuilder::processToken 就是解决 Token 生成对应 Node 的中央,代码如下所示:
void HTMLTreeBuilder::processToken(AtomHTMLToken&& token)
{switch (token.type()) {
case HTMLToken::Uninitialized:
ASSERT_NOT_REACHED();
break;
case HTMLToken::DOCTYPE: // HTML 中的 DOCType 标签
m_shouldSkipLeadingNewline = false;
processDoctypeToken(WTFMove(token));
break;
case HTMLToken::StartTag: // 起始 HTML 标签
m_shouldSkipLeadingNewline = false;
processStartTag(WTFMove(token));
break;
case HTMLToken::EndTag: // 完结 HTML 标签
m_shouldSkipLeadingNewline = false;
processEndTag(WTFMove(token));
break;
case HTMLToken::Comment: // HTML 中的正文
m_shouldSkipLeadingNewline = false;
processComment(WTFMove(token));
return;
case HTMLToken::Character: // HTML 中的纯文本
processCharacter(WTFMove(token));
break;
case HTMLToken::EndOfFile: // HTML 完结标记
m_shouldSkipLeadingNewline = false;
processEndOfFile(WTFMove(token));
break;
}
}能够看到下面代码对 7 类 Token 做了解决,因为解决的流程都是相似的,这里剖析 5 个节点 case 的创立增加过程,别离是 <!DOCTYPE> 标签,<html> 起始标签,<title> 起始标签,<title> 文本,<title> 完结标签 ,剩下的过程都应用图示意。
Case1:!DOCTYPE 标签
// 只保留关健代码
void HTMLTreeBuilder::processDoctypeToken(AtomHTMLToken&& token)
{ASSERT(token.type() == HTMLToken::DOCTYPE);
if (m_insertionMode == InsertionMode::Initial) { // m_insertionMode 的初始值就是 InsertionMode::Initial
m_tree.insertDoctype(WTFMove(token)); // 插入 DOCTYPE 标签
m_insertionMode = InsertionMode::BeforeHTML; // 插入 DOCTYPE 标签之后,m_insertionMode 设置为 InsertionMode::BeforeHTML,示意上面要开是 HTML 标签插入
return;
}
...
}
// 只保留关健代码
void HTMLConstructionSite::insertDoctype(AtomHTMLToken&& token)
{
...
// m_attachmentRoot 就是 Document 对象,文档根节点
// DocumentType::create 办法创立出 DOCTYPE 节点
// attachLater 办法外部创立出 HTMLContructionSiteTask
attachLater(m_attachmentRoot, DocumentType::create(m_document, token.name(), publicId, systemId));
...
}
// 只保留关健代码
void HTMLConstructionSite::attachLater(ContainerNode& parent, Ref<Node>&& child, bool selfClosing)
{
...
HTMLConstructionSiteTask task(HTMLConstructionSiteTask::Insert); // 创立 HTMLConstructionSiteTask
task.parent = &parent; // task 持有以后节点的父节点
task.child = WTFMove(child); // task 持有须要操作的节点
task.selfClosing = selfClosing; // 是否自敞开节点
// Add as a sibling of the parent if we have reached the maximum depth allowed.
// m_openElements 就是 HTMLElementStack,在这里还看不到它的作用,前面会讲。这里能够看到这个 stack 外面退出的对象个数是有限度的,最大不超过 512 个。// 所以如果一个 HTML 标签嵌套过多的子标签,就会触发这里的操作
if (m_openElements.stackDepth() > m_maximumDOMTreeDepth && task.parent->parentNode())
task.parent = task.parent->parentNode(); // 满足条件,就会将以后节点增加到爷爷节点,而不是父节点
ASSERT(task.parent);
m_taskQueue.append(WTFMove(task)); // 将 task 增加到 Queue 当中
}从代码能够看到,这里只是创立了 DOCTYPE 节点,还没有真正增加。真正执行增加的操作,须要执行 HTMLContructionSite::executeQueuedTasks,这个办法在一开始有列出来。上面就来看下每个 Task 如何被执行。
// 办法位于 HTMLContructionSite.cpp
static inline void executeTask(HTMLConstructionSiteTask& task)
{switch (task.operation) { // HTMLConstructionSiteTask 存储了本人要做的操作,构建 DOM 树个别都是 Insert 操作
case HTMLConstructionSiteTask::Insert:
executeInsertTask(task); // 这里执行 insert 操作
return;
// All the cases below this point are only used by the adoption agency.
case HTMLConstructionSiteTask::InsertAlreadyParsedChild:
executeInsertAlreadyParsedChildTask(task);
return;
case HTMLConstructionSiteTask::Reparent:
executeReparentTask(task);
return;
case HTMLConstructionSiteTask::TakeAllChildrenAndReparent:
executeTakeAllChildrenAndReparentTask(task);
return;
}
ASSERT_NOT_REACHED();}
// 只保留关健代码,办法位于 HTMLContructionSite.cpp
static inline void executeInsertTask(HTMLConstructionSiteTask& task)
{ASSERT(task.operation == HTMLConstructionSiteTask::Insert);
insert(task); // 持续调用插入方法
...
}
// 只保留关健代码,办法位于 HTMLContructionSite.cpp
static inline void insert(HTMLConstructionSiteTask& task)
{
...
ASSERT(!task.child->parentNode());
if (task.nextChild)
task.parent->parserInsertBefore(*task.child, *task.nextChild);
else
task.parent->parserAppendChild(*task.child); // 调用父节点办法持续插入
}
// 只保留关健代码
void ContainerNode::parserAppendChild(Node& newChild)
{
...
executeNodeInsertionWithScriptAssertion(*this, newChild, ChildChange::Source::Parser, ReplacedAllChildren::No, [&] {if (&document() != &newChild.document())
document().adoptNode(newChild);
appendChildCommon(newChild); // 在 Block 回调中调用此办法持续插入
...
});
}
// 最终调用的是这个办法进行插入
void ContainerNode::appendChildCommon(Node& child)
{
ScriptDisallowedScope::InMainThread scriptDisallowedScope;
child.setParentNode(this);
if (m_lastChild) { // 父节点曾经插入子节点,运行在这里
child.setPreviousSibling(m_lastChild);
m_lastChild->setNextSibling(&child);
} else
m_firstChild = &child; // 如果父节点是首次插入子节点,运行在这里
m_lastChild = &child; // 更新 m_lastChild
}通过执行下面办法之后,原来只有一个根节点的 DOM 树变成了上面的样子:
Case2:html 起始标签
// processStartTag 外部有很多状态解决,这里只保留关健代码
void HTMLTreeBuilder::processStartTag(AtomHTMLToken&& token)
{ASSERT(token.type() == HTMLToken::StartTag);
switch (m_insertionMode) {
case InsertionMode::Initial:
defaultForInitial();
ASSERT(m_insertionMode == InsertionMode::BeforeHTML);
FALLTHROUGH;
case InsertionMode::BeforeHTML:
if (token.name() == htmlTag) { // html 标签在这里解决
m_tree.insertHTMLHtmlStartTagBeforeHTML(WTFMove(token));
m_insertionMode = InsertionMode::BeforeHead; // 插入完 html 标签,m_insertionMode = InsertionMode::BeforeHead,表明行将解决 head 标签
return;
}
...
}
}
// 只保留关健代码
void HTMLConstructionSite::insertHTMLHtmlStartTagBeforeHTML(AtomHTMLToken&& token)
{auto element = HTMLHtmlElement::create(m_document); // 创立 html 节点
setAttributes(element, token, m_parserContentPolicy);
attachLater(m_attachmentRoot, element.copyRef()); // 同样调用了 attachLater 办法,与 DOCTYPE 相似
m_openElements.pushHTMLHtmlElement(HTMLStackItem::create(element.copyRef(), WTFMove(token))); // 留神这里,这里向 HTMLElementStack 中压入了正在插入的 html 起始标签
executeQueuedTasks(); // 这里在插入操作间接执行了 task,里面 HTMLTreeBuilder::constructTree 办法调用的 executeQueuedTasks 办法就会间接返回
...
}执行下面代码之后,DOM 树变成了如下图所示:
Case3:title 起始标签
当插入 <title> 起始标签之后,DOM 树以及 HTMLElementStack m\_openElements 如下图所示:
Case4:title 标签文本
<title> 标签的文本作为文本节点插入,生成文本节点的代码如下:
`// 只保留关健代码
void HTMLConstructionSite::insertTextNode(const String& characters, WhitespaceMode whitespaceMode)
{
HTMLConstructionSiteTask task(HTMLConstructionSiteTask::Insert);
task.parent = ¤tNode(); // 间接取 HTMLElementStack m_openElements 的栈顶节点,此时节点是 title`
unsigned currentPosition = 0;
unsigned lengthLimit = shouldUseLengthLimit(*task.parent) ? Text::defaultLengthLimit : std::numeric_limits<unsigned>::max(); // 限度文本节点最大蕴含的字符个数为 65536
// 能够看到如果文本过长,会将宰割成多个文本节点
while (currentPosition < characters.length()) {
AtomString charactersAtom = m_whitespaceCache.lookup(characters, whitespaceMode);auto textNode = Text::createWithLengthLimit(task.parent->document(), charactersAtom.isNull() ? characters : charactersAtom.string(), currentPosition, lengthLimit);
// If we have a whole string of unbreakable characters the above could lead to an infinite loop. Exceeding the length limit is the lesser evil.
if (!textNode->length()) {
String substring = characters.substring(currentPosition);
AtomString substringAtom = m_whitespaceCache.lookup(substring, whitespaceMode);
textNode = Text::create(task.parent->document(), substringAtom.isNull() ? substring : substringAtom.string()); // 生成文本节点
}
currentPosition += textNode->length(); // 下一个文本节点蕴含的字符终点
ASSERT(currentPosition <= characters.length());
task.child = WTFMove(textNode);
executeTask(task); // 间接执行 Task 插入
}}
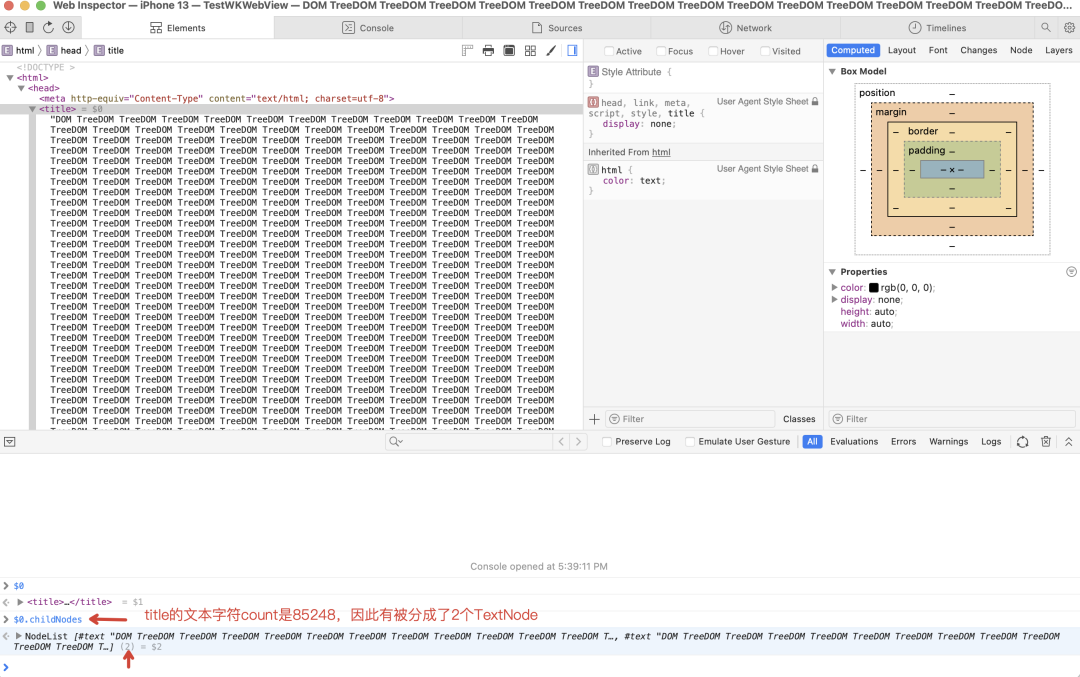
从代码能够看到,如果一个节点前面跟的文本字符过多,会被宰割成多个文本节点插入。上面的例子将 <title> 节点前面的文本字符个数设置成 85248,应用 Safari 查看的确生成了 2 个文本节点:
**Case5:完结标签 **
当遇到 <title> 完结标签,代码解决如下:
// 代码外部有很多状态解决,这里只保留关健代码
void HTMLTreeBuilder::processEndTag(AtomHTMLToken&& token)
{
ASSERT(token.type() == HTMLToken::EndTag);switch (m_insertionMode) {
...
case InsertionMode::Text: // 因为遇到 title 完结标签之前插入了文本,因而此时的插入模式就是 InsertionMode::Text
m_tree.openElements().pop(); // 因为遇到了 title 完结标签,整个标签曾经处理完毕,从 HTMLElementStack 栈中弹出栈顶元素 title
m_insertionMode = m_originalInsertionMode; // 复原之前的插入模式 break;
}
每当遇到一个标签的完结标签,都会像下面一样将 HTMLElementStack m\_openElementsStack 的栈顶元素弹出。执行下面代码之后,DOM 树与 HTMLElementStack 如下图所示:
三、内存中的 DOM 树
当整个 DOM 树构建实现之后,DOM 树和 HTMLElementStack m\_openElements 如下图所示:
从上图能够看到,当构建完 DOM,HTMLElementStack m\_openElements 并没有将栈齐全清空,而是保留了 2 个节点: html 节点与 body 节点。这能够从 Xcode 的控制台输入看到:
同时能够看到,内存中的 DOM 树结构和文章结尾画的逻辑上的 DOM 树结构是不一样的。逻辑上的 DOM 树父节点有多少子节点,就有多少指向子节点的指针,而内存中的 DOM 树,不论父节点有多少子节点,始终只有 2 个指针指向子节点: m\_firstChild 与 m\_lastChild。同时,内存中的 DOM 树兄弟节点之间也互相有指针援用,而逻辑上的 DOM 树结构是没有的。
举个例子,如果一棵 DOM 树只有 1 个父节点,100 个子节点,那么应用逻辑上的 DOM 树结构,父节点就须要 100 个指向子节点的指针。如果一个指针占 8 字节,那么总共占用 800 字节。应用下面内存中 DOM 树的示意形式,父节点须要 2 个指向子节点的指针,同时兄弟节点之间须要 198 个指针,一共 200 个指针,总共占用 1600 字节。相比逻辑上的 DOM 树结构,内存上并不占优势,然而内存中的 DOM 树结构,无论父节点有多少子节点,只须要 2 个指针就能够了,不须要增加子节点时,频繁动静申请内存,创立新的指向子节点的指针。
———- END ———-
百度 Geek 说
百度官网技术公众号上线啦!
技术干货 · 行业资讯 · 线上沙龙 · 行业大会
招聘信息 · 内推信息 · 技术书籍 · 百度周边